今回はPythonを使って今流行りのディープラーニングによる画像認識をやってみたいと思います。ちなみにpythonを使うのは機械学習用にライブラリが充実しているからです。

当たり前の方はスルーでいいのですが、深層学習(ディープラーニング)は機械学習の一部なのでpythonの機械学習用ライブラリを使うことで深層学習もできます。
今回使っていくのは「keras」という機械学習用ライブラリです。Pythonで機械学習をするためのライブラリーは「Pytorch」や「Tensorflow」など他にもありますが「keras」が一番簡単なので今回はとりあえずkerasでやってみます。
ディープラーニングについての大まかな流れは↓の記事で書いているのでそれと照らし合わせてもらえれば、コードの意味がより理解できるかと思います。

kerasの導入
まずkerasをインポートします。
##ライブラリのインポート import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras import optimizers import matplotlib.pyplot as plt import numpy as np %matplotlib inline
Using TensorFlow backend.と出れば成功です。kerasはTensorflowの機能一部を簡単に使っているだけなのでバックではTensorflowが動いています。kerasにしろTensorflowにしろ環境が繊細なので、私はディープラーニング以前のインストールの段階でハマってしまい結構苦労しました。

データセットを読み込む
今回は数字のデータを使います。kerasではMNISTというサンプルデータセットがあるので、そこにあるものを使います。
##データセットを読み込む (x_train, y_train), (x_test, y_test) = mnist.load_data()
サンプルデータセットは他にもアヤメやワインなどがあり、ディープラーニングの参考書では必ずといっていいほど出てきます。
もちろん自分でデータを集めて分析もできるのですが、その場合はデータの整形など前処理が結構めんどくさいです。まあデータ分析全般に言えることですが、分析自体より前処理でデータを整形するのが本当にめんどくさいですね笑
ちなみにデータをtestとtrainの2つに分けているのは、データセット全体を学習データとして使ってしまうと、そのデータセットにだけ異常に当てはまりが良いだけで、他の同じ種類のデータには有効でないモデルになってしまう過学習という現象が起こってしまう可能性があるからです。
なので、ディープラーニングを始めとする機械学習ではデータを訓練用(train)とテスト用(test)に分類しておくのが一般的です。これをミニバッチ学習といいます。訓練とテストのデータ数の割合は8:2くらいが普通だと思います。
まあ与太話は置いておいて実際にデータが読み込めているか一応変数の中身を確認しておきます。変数の中身は.shapeで確認することができます。
>>>x_train.shape (60000, 28, 28) >>>x_test.shape (10000, 28, 28)
中身はこんな感じ
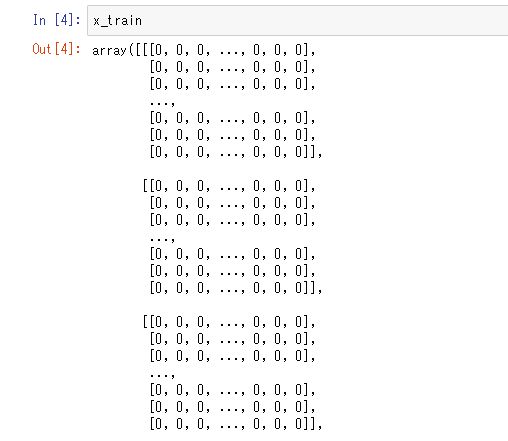
中身は手書きの文字ですが、ディープラーニングだけではなく、データ分析では数値データにしないと分析しようがないので、画像の色の濃淡を0から255の数値で表現しています。
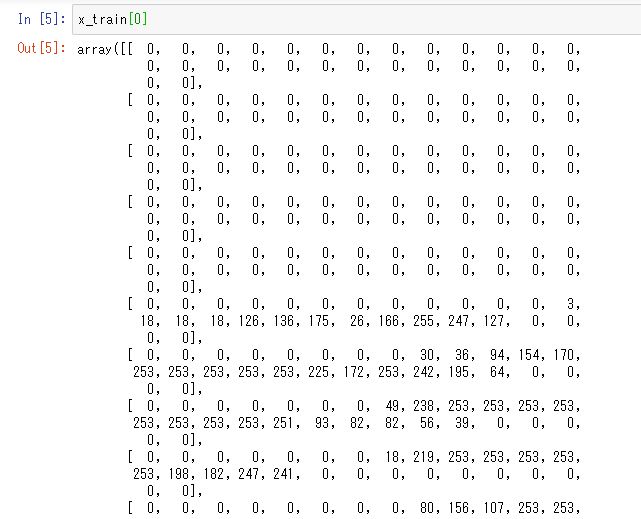
(60000, 28, 28)なので、x_trainには、こういった画像の色の濃さで表現した28×28の行列のデータが60000個入っているということになります。数が多すぎてイメージが難しいと思いますが、データが60000個あるということなので、x_train[56000]とかやっても行列データが表示されます。x_testの方もデータセットを分割した片割れなだけなので、中身はこれと同じでデータ数が60000ではなく、10000になっているだけです。
そして、y_trainにはx_trainの文字データの正解となる数字が60000個格納されています。同じようにy_testにはx_testに対応する答えの数字が配列となって格納されています。
>>>y_train array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)
つまり今回のディープラーニングは

というデータセットが60000個あり、それをディープラーニング(深層学習)でパターンを学習させることで、未知の手書き文字であっても書かれている数字を正しく認識できるようにさせるというものです。
データの整形
まずはディープラ-ニングによる分析で使うための x_ のデータ群を整形する必要があるのでそれを行っていきます。というのも先ほど x_train[0] で表示した結果(↑の画像)を見れば分かりますが、始めが array([[ になっていると思います。 [[ が二つあるということは、このnumpy行列は2次元配列であるということになります。
ディープラーニングで使うためにはnumpy行列は1次元でなければいけないので、データを2次元から1次元の配列に変換します。numpyだと.reshape()という関数で変換することができます。
## numpyで2次元データを1次元データに変換する
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
こんな感じでnumpyには行列を操作する便利関数がたくさん備わっているので、超便利です。僕も人から知らない関数を教えてもらうこともあり、まだまだですが、使いこなせるとnumpyは本当に便利です。
そして、適当なデータを開いて変換できているかを確認します。
>>>x_train[20000]
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
先頭がarray([[ から array([ に変わっており、2次元の配列から1次元の配列に変換が成功したことがわかります。ちなみに、この.reshapeという関数でどういう処理をしたのかというと
[[11111111111111]
[11111111111111]
[11111111111111]]
みたいな2次元の配列を
[11111111111111
11111111111111
11111111111111]
というような1次元の行列に変換したのです。
.reshapeの引数が60000,784なのは、x_trainのデータセットの数が60000個なので、その60000.。784は1次元に変換したときの列数をしています。この場合だと元が28×28の2次元配列なので、28×28=784というわけです。
そして次の/255は、行列の1つ1つの数字を255で割っています。なぜ255なのかというと上でチラッと書いたように、このデータは数字の画像を色の濃淡を0から255までの数字で表現しています。それを255で割ることよって、画像データを0から1の数値で表現されたデータに変換しています。
そして次は手書き文字の正解を格納した y_ もディープラーニングに使えるように少し変換します。具体的には、[1,2,3,3,4,5,6,4,6,6]というただ手書き文字の正解の数値がそのまま入っているものから、one hotベクトルに変換した配列にします。
one hotベクトルについては、文章認識などでも使うため奥が深く、詳しくはググってもらいたいのですが、例えば4という数字がある場合、普通なら4で終わりですが、one hotの場合は[0,0,0,0,1,0,0,0,0,0]という感じで表現します。つまり、[4,6,0]という数字の配列があったならば、onehotでは
[0,0,0,0,1,0,0,0,0,0]
[0,0,0,0,0,0,1,0,0,0]
[1,0,0,0,0,0,0,0,0,0]
という表現になります。
##数値配列をonehotベクトルに変換する y_train = keras.utils.to_categorical(y_train,10) y_test = keras.utils.to_categorical(y_test,10)
kerasではkeras.utils.to_categorical()という関数で、配列をonehotに変換することができます。引数の10は今回手書き文字を0~9の10パターンに分類するので10になっています。今回は数字なので1~10ですが、日本語など言葉とかのを分析する場合はまた変わってきます。今回の分析ではデータ数が60000あるため、このような数列が60000個並んでいることになります。
ディープラーニングのモデル構築
ようやくデータの前処理が終わったので、次はようやくディープラーニングのモデルの構築に入っていきます。(データ分析は本当に分析よりその前処理がめんどくさい・・・)
###ディープラーニングのモデルを構築する#### model = Sequential() ##入力層の設定## model.add(Dense(512, activation='relu', input_shape=(784,),kernel_initializer='glorot_normal')) ##中間層の作成## #30%DropOut層を追加する model.add(Dropout(0.3)) #出力を512次元としてReLU関数の活性化関数層も追加する model.add(Dense(512, activation='relu',kernel_initializer='glorot_normal')) model.add(Dropout(0.3)) model.add(Dense(512, activation='relu',kernel_initializer='glorot_normal')) model.add(Dropout(0.3)) # 出力層を作成する model.add(Dense(10, activation='softmax'))
kerasではmodel.add()という関数でネットワークにおける中間層を追加できます。当たり前ですが、addした分だけモデルの層は増えます。今回は7回なので入力層1層・中間層5層・出力層1層の7層のディープラーニングモデルとなります。
7層だとニューラルネットワークに分類される気もしますがスルーでお願いします笑。また中間層を100層とかにしたいときはfor文などで記述した方がいいでしょう。
入力層
最初の入力層にあたる
model.add(Dense(512, activation=’relu’, input_shape=(784,),kernel_initializer=’glorot_normal’))
という文は
input_shapeで入力層に入るデータの数を指定します。今回は28×28の行列データなので、784次元ということになるため784にします。
その層が出力する次元の数は最初の引数で指定できます。今回は512次元としておきます。つまりここでは784次元のデータが入り、そこに重みを掛け合わせ512次元の数値を出力するという処理をしろと命令しています。また引数のkernel_initializerは重みの初期値の設定する引数です。
重みの初期値は正規乱数とかで設定するものなのですが、最近はそれを少しアレンジしたザビエルがオススメらしいので、ザビエル(glorot_normal)にしておきます。
次のactivation=”は活性化関数に何を使うかを指定します。reluでReLU関数の活性化関数の層を追加します。昔はディープラーニングに使う活性化関数と言えば、シグモイド関数だったらしいのですが、シグモイド関数を使うと仕様上、勾配消失が起こりますし、ReLUの方が予測の精度が良いらしいので最近はReLU一色な雰囲気ですのでReLU関数にします。
中間層の設定
中間層もmodel.addで作れます。入力層との違いは入力データが、入力層からそのまま流れてくるのでinput_shapeを指定する必要のないところです。ですが、それ以外の出力する次元の数と活性化関数・重みの初期設定は同じように設定する必要があります。
model.add(Dense(512, activation=’relu’,kernel_initializer=’glorot_normal’))
また、model.add(Dropout(0.2))でドロップアウト層も作れます。ドロップアウトとかディープラーニングにおける過学習を防止する手段の1つで、不活性化ニューロンを一定の割合で削除する(計算しない)ことによって学習精度を高める的なものです。
またKerasだとDropout()でドロップアウト層を作ることができ、不活性にするニューロンの割合は引数で指定できます。今回は0.3なので30%のニューロン(重み)の不活性化するということになります。他にもバッチノーマリゼーションなど深層学習の分野ではひび新しいネタが出てくるので継続的に勉強していかなければいけませんね。
出力層
中間層を設定したら最後に出力層を作ります。出力層も入力層・中間層と同じようにmodel.add()で作れます。ただ最後なので次元の数と関数は中間層の場合と少し異なります。
今回の場合は0~9の数字の認識なので出力層の次元数は10とします。また分類問題なので、ソフトマックス関数を計算する層も加える必要があります。(回帰問題の場合は恒等関数を使用します。)
モデルの確認と実行
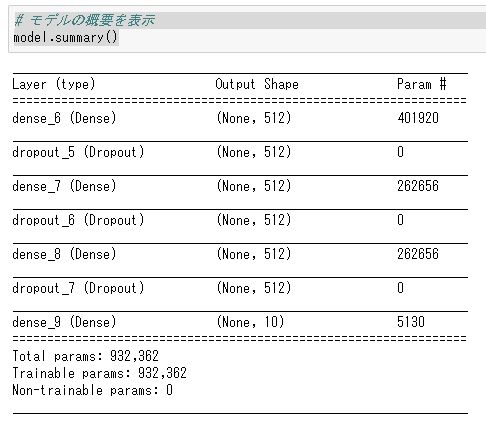
構築したディープラーニングのモデルはmodel.summary()で確認することができます。今回の場合だと↓のようになると思います。中間層の数やドロップアウト層の場所などを変えることで学習精度はめちゃくちゃ変わってきますので、いろいろアレンジしてみてください。
## 損失関数をクロスエントロピーに設定、評価方法をaccuracyに設定する model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=0.01), metrics=['accuracy']) ##ディープラーニングを開始する result = model.fit(x_train, y_train, batch_size=128, epochs=25, verbose=1, validation_data=(x_test, y_test)) ##モデルを評価する score = model.evaluate(x_test, y_test, verbose=0)
構築したディープラーニングモデルにデータを放り込む前にまず損失関数(誤差関数)とモデルの評価方法を設定する必要があります。今回は多項分類問題なので、クロスエントロピーを指定します。optimizerは誤差関数の最小値を計算する計算方法を指定する引数で、SGDとすると確率勾配降下法になります。
そして、lrで学習率を設定します。学習率は大きすぎると予測精度がガバガバになりますし、0.1~0.01の範囲で指定しておくのがベターだと思われます。metricはモデルの評価方法を指定する引数で今回は無難な分類なので正解率にしておきます。
そして、model.fit()で、モデルにデータを学習させることができますが、その際に学習するデータと学習に際してのパラメーターの設定を行う必要があります。バッチサイズはいっぺんに処理されるデータの数を指してます。
目安はよくわかりませんが、私が読んだ参考書とかでは1~128とかでやっているので、そのどれかで良いと思います。まあミニバッチ学習としてデータを分けて分析できていれば問題ないでしょう。
基本的にミニバッチの単位が小さければ小さいほど、1つ1つのデータに敏感に反応すると考えることができます。なので、明確な基準は分かりませんが、学習させるデータセットの数によってバッチサイズは変更する必要があります。
そして、その次のepochsで学習回数を指定できます。verboseは1にすると1回の学習の掛かった計算時間が何秒だったかなど計算過程が見えます。jupyterで0にすると処理中を示す※が表示されるだけになります。
コードを実行するとこんな感じでガガガ・・・と計算が始まります。
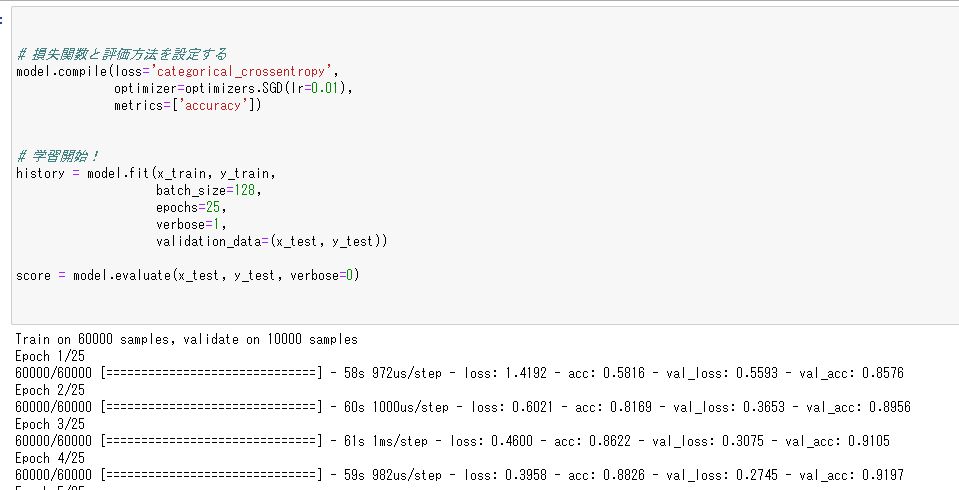
計算が終わったら訓練データをディープラーニングで学習したモデルをtestデータに当てはめた結果、つまりモデルの正確さがどれくらいだったかを確認します。
>>>print('Test accuracy:', score[1])
Test accuracy: 0.967
96.7%なので良い数値だと思います。(小学生並みの感想)
まあこんだけ綺麗なデータがありゃと当然の結果でしょう。
学習過程をプロットして確認する
モデルのフィットが終わったので、次は学習過程をグラフ化します。ディープラーニング実行時に「result = model.fit(~」としていることで学習の過程をresultという関数に保存しています。
resultの中身は辞書型のデータになっていて誤差や精度などのデータが格納されているので、これをMatplotlibでプロットします。
# 学習過程における誤差の推移をプロットする
loss = result.history['loss']
val_loss = result.history['val_loss']
acc = result.history['acc']
epochs = len(loss)
plt.plot(range(epochs), loss, marker='.', label='loss')
plt.plot(range(epochs), val_loss, marker='.', label='val_loss')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.show()

#正解率をプロットする
plt.plot(range(epochs), acc, marker='.', label='accracy')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.show()

図を見ても分かるように、学習回数が増えていくにつれて誤差が減って正解率が上がっていっているのが分かると思います。
終わり
細かく書くと超ながくなってしまいましたが、とりあえずディープラーニング頻出かつ長期本の画像認識の流れはこんな感じです。この発展形として、畳み込みディープラーニング(CNN)やリカレントネットワーク(LSTM・RNN)があります。


そいつらはこれよりもうちょっとモデル構築がめんどくさいですが、まあやっていることはそんなに変わらないと思うので、この流れがちゃんとわかっていればとりあえず実装までもっていくのはそう難しくないと思います。
またデータの前処理ですがワインやアヤメの分類にするときは入力層やデータの整形方法がまた違うので、numpyで使用する関数がまた違ってきます。にしてもnumpy超便利、なかったらと思うとゾッとしますね。
あとメモリはせめて8GBはないとディープラーニングをする場合は分析に時間がめっちゃ掛かるのでお話にならないですね。そろそろmouseあたりの16GBのノートPCを買っちゃおうかなとか思ってます笑
kerasは簡単にディープラーニングができますが、機能が制限されているので実務でガチで使うのであれば、「Pytorch」とか「Tensorflow」の方が応用パターンが広いかなと思ったり思わなかったり・・・。まあなんにせよ僕もまだまだ未熟なのでもっと腕を上げていきたいと思います。
また機械学習・ディープラーニングは昔は独学で勉強するものでしたが、昨今は月々たった3000円でディープラーニングが勉強できる「PyQ™(パイキュー)」などもできており、昔よりも学習のハードル・コストは下がりつつあります。

また他にも少し値段は高いですが、「Aidemy Premium Plan」だとレベルが高い学習内容なのでAIエンジニアとして実務レベルのスキルを身に着けられます。IT人材の給料が世界と比べて低い日本でもAIが分かるエンジニアには年収1000万を出すところもあるので、本気で勉強する気があるならば十分元はとれます。



コメント
Admiration!!!!