
Mentaの相談でよく「自作のデータをデータフレームを機械学習モデルの関数に入れるとエラーが出て動きません」というのがあるので、それのテンプレ回答になります。
ちなみに体感このエラーの原因の9割は関数が想定しているデータ型と投入しているデータ型が違うことにあります。というわけで今日は「データフレームのデータ型の確認&データ型を変換する方法」について紹介したいと思います
Contents
Pythonでのデータフレームのデータ型について
データの確認
Pythonでデータフレームを使って機械学習のモデルを作って分析や予測するときは、正しいデータ型でデータを扱わないと、予期しないエラー(unexpected~~~)が出る可能性があります。
Pythonでデータ分析を行う際はPandasのデータフレームを使います。pandasはデータフレームを作る際にデータの型を自動で推定してくれる型推定という機能があり、これで自動的に読み込んだデータフレームの各列の型を内部で決めてくれています。
この型推定の精度は高く、基本的には問題ないのですが数値データなどでたまにこちらの予想と違う方になっていることがあります。
Pandasにおけるデータ型
Pandasでは以下のようなデータ型の種類があります。
| Pandasの型 | Pythonの型 | 用途 |
|---|---|---|
| object | str or mixed | 文字列や文字列と数値の混合型 |
| int64 | int | 整数 |
| float64 | float | 浮動小数点 |
| bool | bool | 真/偽 |
| datetime64 | NA | 日付および時刻 |
| timedelta[ns] | NA | 2つの日時の差 |
| category | NA | 文字列のカテゴリ |
PandasにおけるObject型は文字列型を指しますが、リストや辞書などもobject型に分類されます。
使用するデータ
まずデータを用意します。
import pandas as pd data = [[1,'A',187.5,65,1.0],[2,'B',177.5,'55',1],[3,'C',167.5,45,0],[4,'D',157.5,48,0]] df = pd.DataFrame(data,columns=['number','name','height','weight','sex']) df
<実行結果>
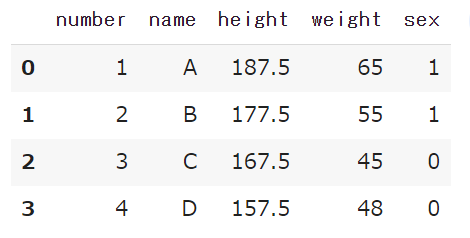
インデントがおかしい場合はこちらのノートブックを参照してください
→https://colab.research.google.com/drive/1e0LUo2X4JO34D4wdlVeGLsMGYzWNyYci?usp=sharing
Pandasでの処理
データ型を確認する
データを読み込んだところで、データフレームのデータ型を確認します。
データ型を確認するには、df.dtypesを使います。
df.dtypes
<実行結果>

こんな感じで、各列のデータ型が確認できます。
よくある型推定ミスの例
特によくあるのがint型とfloat型の違いです。特にscikit-learnなどの機械学習系もライブラリでモデルを作成する際は目的変数となる列データはint型が指定されていることが多いです。
なので、よくあるデータセットだと目的変数にあたる列はint型になるように整備されています。しかし自作のデータでは同じ0.1なのにPandasがfloat型だと判定してエラーになるケースが多いです。
でこれはなぜ起きるのかという話ですが、上のデータのnumberとsexの型を見てください。同じ数値なのにデータ型がintとfloatと異なっています。これはsexの列に1.0というデータが入っているためです。この1.0というデータをみてpandasがsexのデータ型をfloat(浮動小数点型)だと判断しています。
こうやってみると分かりやすい話ですが、こういうデータは大抵エクセルで作ってpd.read_csv(~~~.csv)で読み込むと思いますが、エクセルでデータをガチャガチャしているうちに数値がfloatになっていたなんてことがあります。ですが、こういう場合でもエクセルは内部上は1.0のデータであってもPythonとは違い表面上は1と表示されるため、気付かないことが多いです
なので自作のデータを作った際にエクセルで確認すると0と1としかないので、サンプルデータと同じ構造にできた~と思っても内部上は1.0と記録されているのでpandasで読み込むとfloat型で判定されサンプルデータ(目的変数の列が数値型)のデータフレームと置き換えてモデルに入れようとすると型違いでエラーがおきます。
次に多いのがint型とobject型です。こちらはnumberとweightの列を見れば分かりますが、同じ数字しか入っていないのに型の推定結果が異なっています。これはweightの方に’55’というデータがあるからです。これもエクセルだと文字型と数値型が特に区別されないのでエクセルから見ると気付かないことが多いです。また普通にデータが膨大な場合は全部のデータを確認しないと思いますが、何かの手違いで異常値や欠損値(NAN)が入っている場合などこういったことが起こります。
データ型を変換する(float→数値)
Pandasでデータ型を変換するにはdf.astype()を用います。
例としてsexを数値型(int)に変換します
df['sex'] = df['sex'].astype('int')
print(df.dtypes)

sexのデータ型がfloat→intに変換されていることがわかります。
目的の型に変換できないとき
データが綺麗な場合は上記のようにastypeすれば済むのですが、例えばデータに変なものが混じっている場合などはastypeで変換を掛けてもエラーになります。
import pandas as pd
data = [[1,'A',187.5,65,1.0],[2,'B',177.5,'55',1],[3,'C','xxxx',45,0],[4,'D',157.5,48,'xxx']]
df = pd.DataFrame(data,columns=['number','name','height','weight','sex'])
print(df)
df['sex'] = df['sex'].astype('int')
<エラーメッセージ>
ValueError: invalid literal for int() with base 10: 'xxx'
これは「xxx」が数字に変換できないことが原因みたいです。sexの列を数値として扱うにはこれらを取り除く必要がありそうです。文字列の置換にはreplace()を使います。また、簡潔に表現するためにlambda関数(無名関数)を使用します。
lambda x: x.replace('xxx', '1')
そして、df.apply()と組み合わせることでlanbdaで定義した関数を処理を列の全データに対して一行ずつ実行することができます。
def test(x):
if x == 'xxx':
x = x.replace('xxx', '1')
else:
pass
return x
df['sex'] = df['sex'].apply(lambda x:test(x)).astype('float')
df
これでxxxを1に変換してsexの列を数値型に変換することができました。
またこういったケースだとpd.to_numeric()を用いることで、より柔軟に対応することができます。引数にerrors=”coerce”を追加することで、変換できない項目は欠損に変換することができます。
#異常値があるheightの列を数値型に変換する
df['height'] = pd.to_numeric(df['height'], errors='coerce')
print(df)
この場合異常値はNaNに変換されます。また欠損値も分析においては好ましくないので、何等か処置をする必要があります。今回は欠損を0で置き換える処理を追加します。
# 欠損値を0埋めする df['height'] = df['height'].fillna(0) print(df)
データ型を変換する(文字列→日付)
文字型を日付型に変換します。
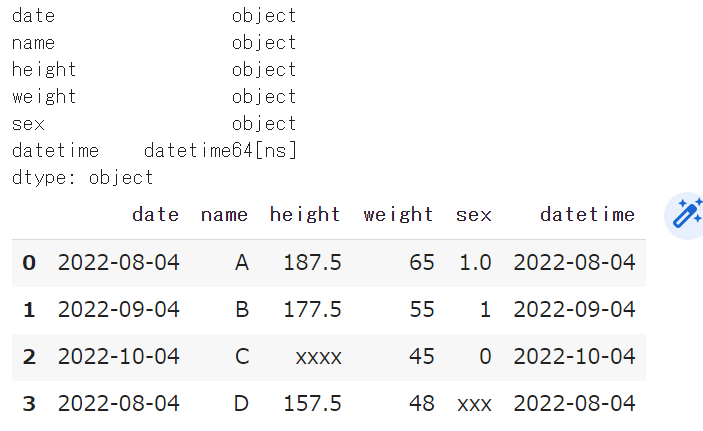
import pandas as pd data = [['2022-08-04','A',187.5,65,1.0],['2022-09-04','B',177.5,'55',1],['2022-10-04','C','xxxx',45,0],['2022-08-04','D',157.5,48,'xxx']] df = pd.DataFrame(data,columns=['date','name','height','weight','sex']) print(df)
今回は新規に”datetime”列を作成します。日付型への変換は pd.to_datetime ()を用います。
df["datetime"] = pd.to_datetime(df['date']) print(df.dtypes) df
<実行結果>
条件分岐による置換
他にもPandasでは条件分析を使った置換もできます。例えばデータのカラムが1だったらTrueに変換、0だったらFalseに変換なんてことも可能です。
参照:【Python】データフレームの列データをapply関数+lambdaで条件分岐してまとめて置換する
終わり
Pandasのデータフレームのデータフレームを変換する方法を紹介しました。scikit-learnに用意されているアヤメやBoston住宅価格のデータは予め整形されていて非常にきれいなものですが、自作のデータだったり実務で扱うデータは、今回の例に挙げたデータのように、そのままでは分析に使えないといったケースは少なくありません。
機械学習はモデルを作ったり精度予測の部分がフォーカスされがちですが、実際には前処理に膨大な時間を使うので前処理がとても大切になります。データ分析者としての腕前には変なデータをいかにきれいに整形できるかという部分が勿論関与してくるので、今後データ分析の世界を目指すのであればぜひこういったテクニックを身に着けておいたほうが良いと思います。
プログラミングでエラーが出た時はまずprint()でデータの中身を見る、それでも原因が分からないときは、変数ならtype()、データフレームならdf.dypesでデータの型を確認しましょう!
データ処理やスクレイピングについてはMENTAにて相談受け付けておりますのでお気軽にご連絡ください。


コメント