 SQL
SQL 【AWS/SQL】Athenaで小数点を表示されないときの対処法
Athenaで小数点を表示されないときの対処法をまとめておきます
Athenaで小数点を表示させる
AthenaはPrestoをベースにしているので、Prestoの関数を利用してクエリを書くことができます。小数点...
SQL SQL SQL 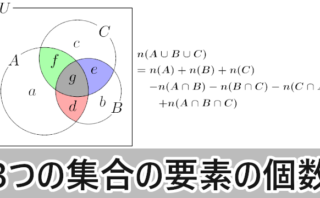 SQL BigQuery GCP SQL
SQL BigQuery GCP SQL  Python
Python  SQL
SQL