
今回はPythonを使って気象庁の公式HPから過去の天気情報をスクレイピングしたいと思います。
気象庁の公式HPから過去の天気情報をスクレイピングするサンプルコード
コードについてこちらのブログの記事を参考に少し修正しています。
<コード>
import os
import datetime
import csv
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
def str2float(weather_data):
try:
return float(weather_data)
except:
return 0
def scraping(url, date):
# 気象データのページを取得
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html)
trs = soup.find("table", { "class" : "data2_s" })
data_list = []
data_list_per_hour = []
# table の中身を取得
for tr in trs.findAll('tr')[2:]:
tds = tr.findAll('td')
if tds[1].string == None:
break;
data_list.append(date)
data_list.append(tds[0].string)
data_list.append(str2float(tds[1].string))
data_list.append(str2float(tds[2].string))
data_list.append(str2float(tds[3].string))
data_list.append(str2float(tds[4].string))
data_list.append(str2float(tds[5].string))
data_list.append(str2float(tds[6].string))
data_list.append(str2float(tds[7].string))
data_list.append(str2float(tds[8].string))
data_list.append(str2float(tds[9].string))
data_list.append(str2float(tds[10].string))
data_list.append(str2float(tds[11].string))
data_list.append(str2float(tds[12].string))
data_list.append(str2float(tds[13].string))
data_list_per_hour.append(data_list)
data_list = []
return data_list_per_hour
# データ取得開始・終了日
start_date = datetime.date(2021, 12, 30)
end_date= datetime.date(2021, 12, 31)
w_data = []
# データフレームのカラム定義
fields = ["年月日", "時間", "気圧(現地)", "気圧(海面)",
"降水量", "気温", "露点湿度", "蒸気圧", "湿度",
"風速", "風向", "日照時間", "全天日射量", "降雪", "積雪"]
date = start_date
while date != end_date + datetime.timedelta(1):
# 対象url(今回は東京)
url = "http://www.data.jma.go.jp/obd/stats/etrn/view/hourly_s1.php?" \
"prec_no=44&block_no=47662&year=%d&month=%d&day=%d&view="%(date.year, date.month, date.day)
data_per_day = scraping(url, date)
for dpd in data_per_day:
w_data.append(dpd)
date += datetime.timedelta(1)
# データフレームに変換
w_df = pd.DataFrame(w_data,columns=fields)
print(w_df)
# csvに出力
w_df.to_csv('weather_data.csv')
<実行結果>
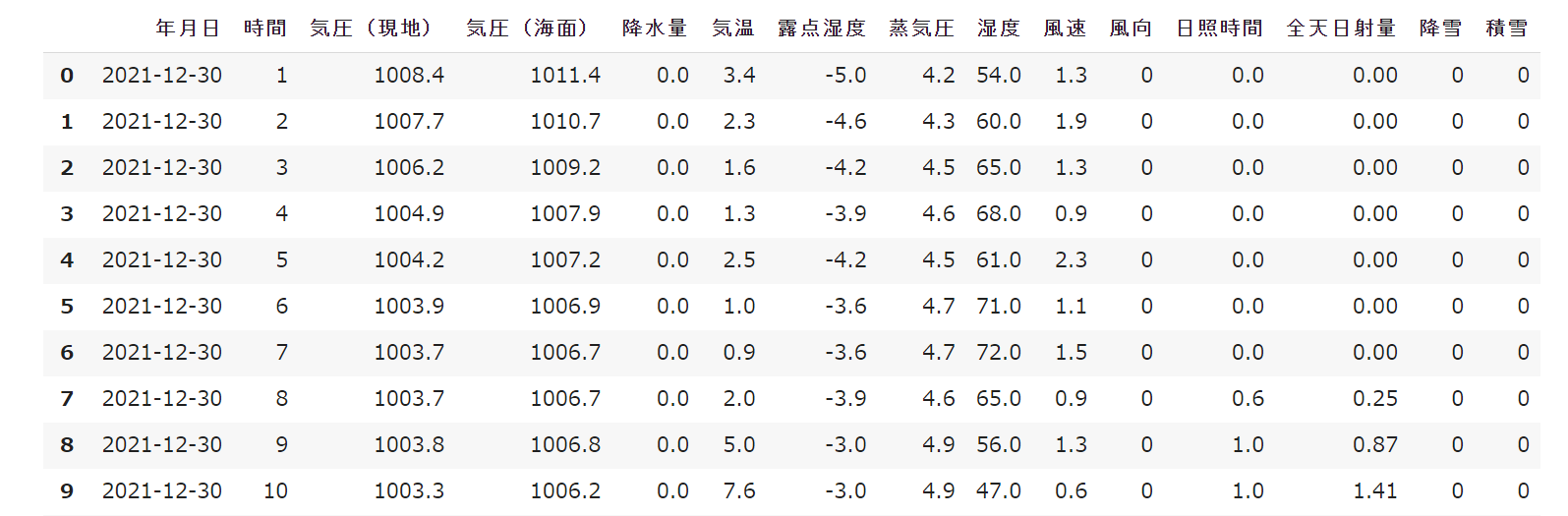
期間を一年くらいに伸ばすと処理に結構時間が掛かるので注意してください。
関連記事:RequestsとBeautifulSoupでWikipediaをスクレイピングするサンプルコード
関連記事:【Python】iTunesストアのAPIを叩いてアプリのレビューをスクレイピングで自動取得する
コメント