
今回はGoogleColab環境でLoraの学習モデルを追加学習し、それを使用してStableDiffusion WebUIで特定のアニメキャラを生成する方法について紹介したいと思います。
Contents
前準備
作業環境
環境はGoogleColabを想定しています。StableDiffusion WebUIが起動できている&すでにLoRaが導入されている前提で話を進めます
StableDiffusionの基本的なことやAIの倫理観的な部分、GoogleColabでWebUIでAI画像を生成する方法については下記記事を参照してください。
関連記事:【Python】Stable Diffusionを使ってAI画像を生成するサンプルコード
モデルの追加学習について
モデルの学習についてはWebUIからDreamBoothという拡張機能を使用する方法がありますが、バージョンなどの互換性でうまく動かないので、今回は「kohya-ss」というモジュールを使用した方法を紹介します。ネットで調べる感じこれのほうがDreamBoothより安定性が高いっぽいです
訓練用画像の収集
まず学習に必要な画像を集める必要があります。
画像の集め方はシンプルにGoogle検索の画像検索結果を手動で集めるのでもよいかなと思いますが、Pythonである程度自動化することが可能です。詳しくは下記記事を参考にしてください
関連記事:【Python】icrawlerで画像検索結果を一括ダウンロード・スクレイピングする
今回訓練したのは以下の画像です。
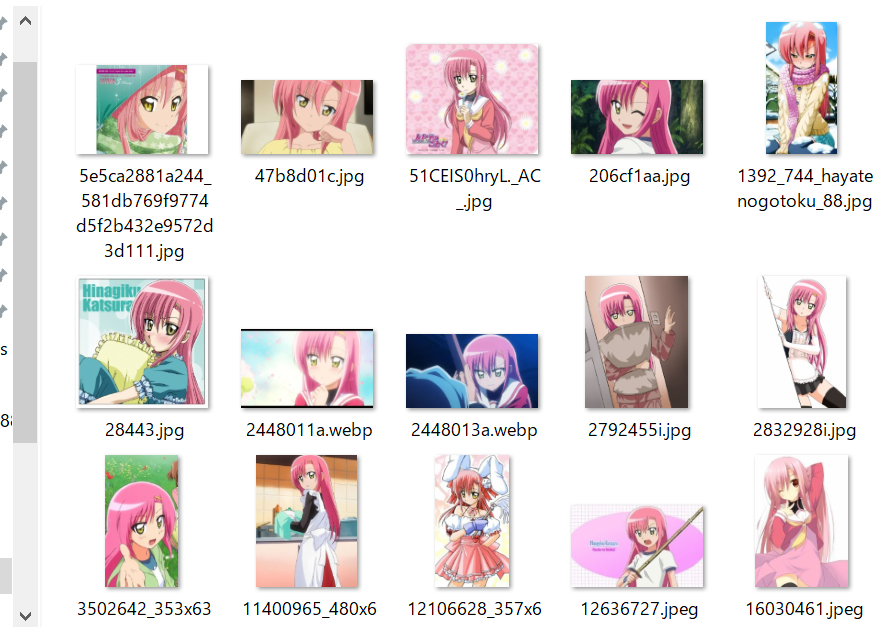
LORAの元モデルを用意する
今回は「AOM3A1B」を前提にしています。以下のリンクにアクセスしてページ右上部の「Download」をクリックしてください。(サイズは2GBほどです)
これをGoogleDriveの任意の場所に配置します
Colabでモデルを訓練する
まずドライブをマウントします
from google.colab import drive
drive.mount('/content/drive')
python3.10のインストール
colabにはpython3.9が入っていますが、sd-scriptsで推奨されているpythonのバージョンが3.10なのでバージョンをアップデートします
!sudo apt autoremove !sudo apt-get -y update !sudo apt-get -y install python3.10 !sudo cp `which python3.10` /usr/local/bin/python !wget https://bootstrap.pypa.io/get-pip.py !sudo python get-pip.py !python --version !pip --version
kyoya-ssのダウンロード・インストール
以下のコマンドで「kyoya-ss」をダウンロードします。
!git clone https://github.com/kohya-ss/sd-scripts %cd sd-scripts !pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 !pip install --upgrade -r requirements.txt !pip install -U --pre triton !pip install xformers==0.0.16rc425
これでkyoya-ssが「/content」直下にインストールされます
accelerateの設定
次に「accelerate」をデフォルト設定で指定します。
!accelerate config default --mixed_precision fp16
次に「sd-scripts」の配下に集めた画像をコピーして配置します
下記のコマンドでは「/content/drive/MyDrive/train_img」に配置した訓練用画像を
sd-scripts直下の「unitychan」というディレクトリにコピーして移動します
キャプションとタグの付与
# sd-scriptsに配下に訓練用画像をコピーする %cd /content/sd-scripts %cp -r /content/drive/MyDrive/train_img ./unitychan
次に画像にキャプションを付与します
# 画像にキャプションを付与する !python finetune/make_captions.py --batch_size 8 ./unitychan !python finetune/tag_images_by_wd14_tagger.py --batch_size 4 ./unitychan
タグの整理と前処理を行います
!python finetune/merge_captions_to_metadata.py ./unitychan meta_cap.json !python finetune/merge_dd_tags_to_metadata.py ./unitychan --in_json meta_cap.json meta_cap_dd.json !python finetune/clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
latentsの事前取得
使用するモデルのlatentsの事前取得を行います。下記コマンドの「/content/drive/MyDrive/lora_models/AOM3A1B_orangemixs.safetensors」は自身の環境のPATHに合わせたものに変更してください
!python finetune/prepare_buckets_latents.py ./unitychan meta_clean.json meta_lat.json /content/drive/MyDrive/lora_models/AOM3A1B_orangemixs.safetensors --batch_size 4 --max_resolution 512,512 --mixed_precision no
学習実行
下記のコードで学習を実行します。
!accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=/content/drive/MyDrive/lora_models/AOM3A1B_orangemixs.safetensors --in_json meta_lat.json --train_data_dir=./unitychan --output_dir=output_models --shuffle_caption --train_batch_size=1 --learning_rate=1e-4 --max_train_steps=400 --use_8bit_adam --xformers --gradient_checkpointing --mixed_precision=fp16 --save_every_n_epochs=4 --save_precision=fp16 --save_model_as=safetensors --network_module=networks.lora
- train_data_dir=./unitychan # 訓練したい画像のPATH
- pretrained_model_name_or_path=/content/drive/MyDrive/lora_models/AOM3A1B_orangemixs.safetensors # チューニングしたいモデルのPATH
- –output_dir=output_models # チューニングした後のモデルの出力先
学習済みモデルをDrive保存する
最後にモデルをDriveにモデルをコピーして保存します。下記のコマンドは「/content/drive/MyDrive/output_models.safetensors」に出力する想定ですが、自身の環境に合わせたものにしてください
# 最後の学習モデルをDriveに保存する !cp output_models/last.safetensors /content/drive/MyDrive/output_models.safetensors # モデルの過程をZIPで保存する場合 # !zip output_models.zip output_models/* # !cp output_models.zip /content/drive/MyDrive/lora_models/output_models.zip
生成したモデルをWebUIで使用する
キャラの特徴を表したプロンプトを確認
まず学習に使用した画像のプロンプトを確認します。
# 学習に使用した画像のプロンプトを確認する !cat /content/sd-scripts/unitychan/*.txt
<出力結果>
1girl, solo, short_hair, open_mouth, collarbone, closed_eyes, purple_hair, nude, red_hair, wet, oekaki, wet_hair, showering
1girl, solo, smile, short_hair, blue_eyes, simple_background, shirt, white_background, jewelry, jacket, purple_hair, flower, ahoge, belt, pants, necklace, bracelet, cross, casual 1girl, solo, smile, short_hair, open_mouth, blue_eyes, skirt, thighhighs, long_sleeves, pink_hair, ahoge, boots, one_eye_closed, uniform, military, military_uniform, knee_boots, pink_skirt, salute, two-finger_salute
1girl, solo, short_hair, blue_eyes, simple_background, purple_eyes, pink_hair, purple_hair, ahoge, uniform, military, military_uniform, black_background
…
生成したモデルに対して上記にプロンプトをそのまま使用すると元モデルの画風に合わせて学習した画像の特徴に合わせたキャラの絵柄が出力されやすくなります。
StableDisffusion WebUIでの使用方法
StableDisffusion WebUIの導入方法については長くなるので下記の記事を参考にしてください
関連記事:【Python】GoogleColab上でStableDiffusion+LoRAで美少女イラストを生成する
生成したモデル(output_models.safetensors)は「~~~/stable-diffusion-webui/models/Lora」の直下に配置しWebUIを起動します。
起動してtxt2imgのタブから以下のアイコンをクリックします
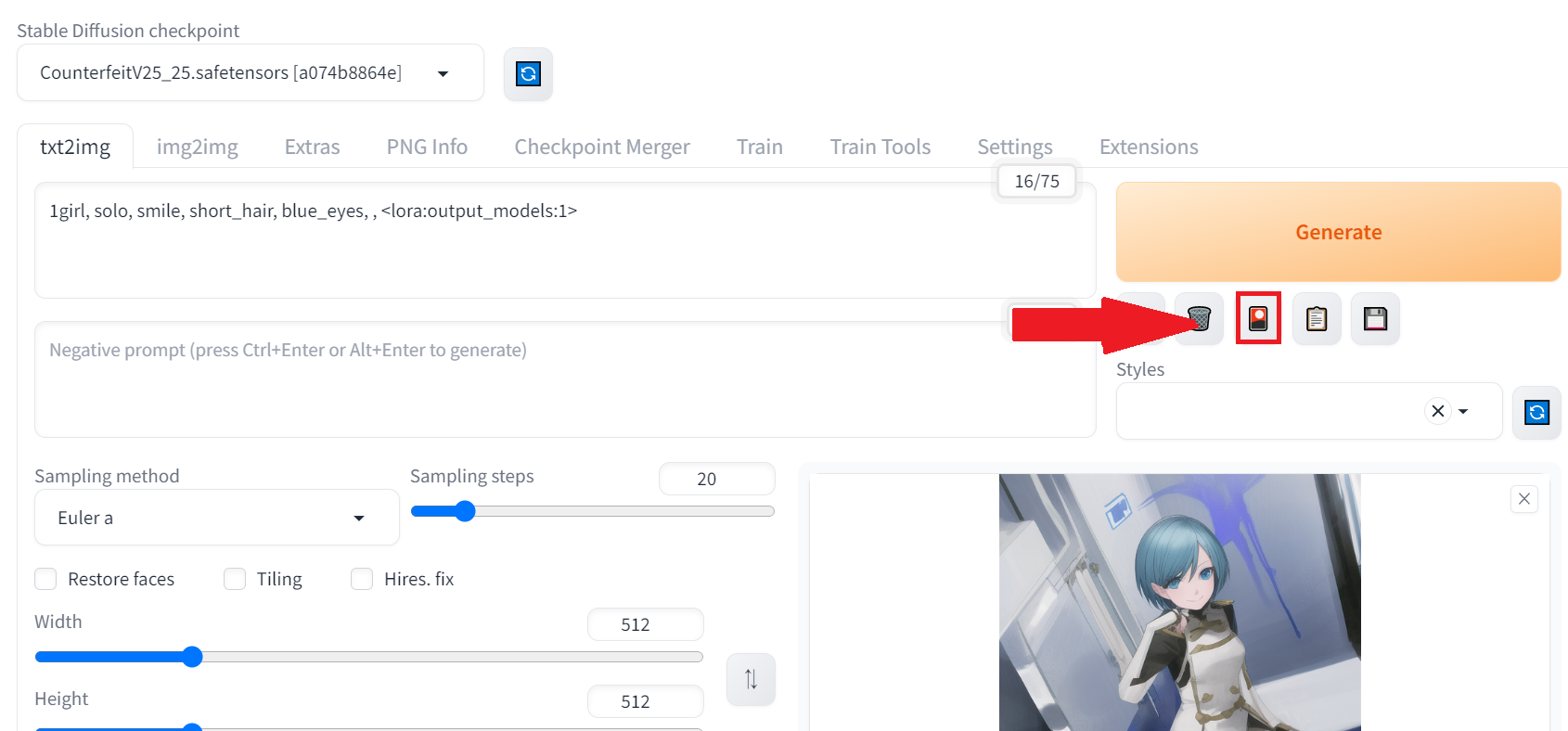
するとタブが開くので「Lora」のタブに移動すると「output_models」が反映されています。
該当モデルをクリックするとプロンプトに「 <lora:output_models:1>」が追加されます。
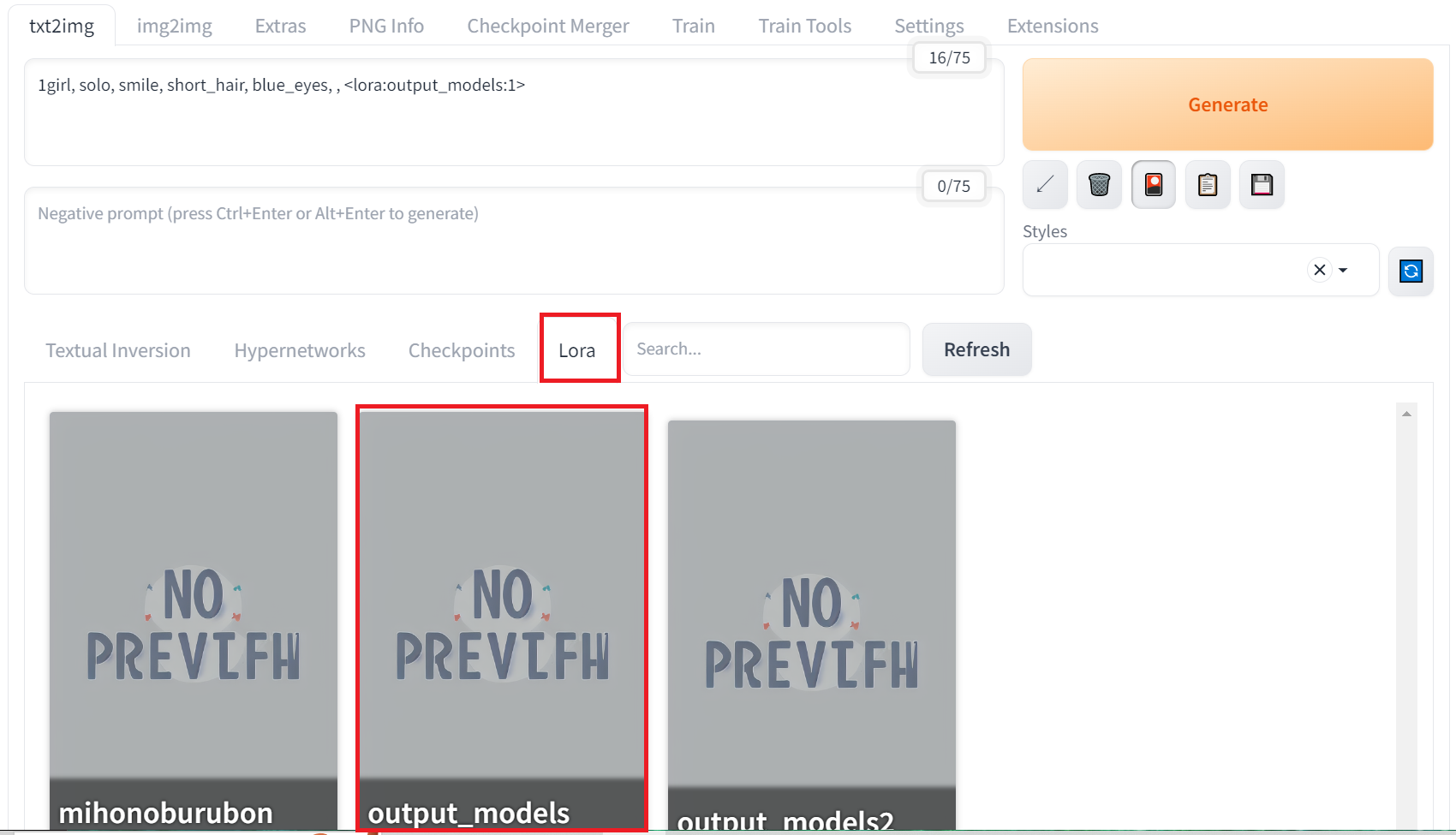
読み込まれていない場合はその横の「Refresh」を押すと反映されます。
プロンプトの指定
<lora:output_models:1>だけだとプロンプトが弱くキャラがうまく反映されないので、その前に
学習に使用した画像のプロンプトを付け加えると精度が良くなります
<イメージ例>
1girl, solo, smile, short_hair, blue_eyes, simple_background, shirt, white_background, jewelry, jacket, purple_hair, flower, ahoge, belt, pants, necklace, bracelet, cross, casual 1girl, solo, smile, short_hair, open_mouth, blue_eyes, skirt, thighhighs, long_sleeves, pink_hair, ahoge, boots, one_eye_closed, uniform, military, military_uniform, knee_boots, pink_skirt, salute, two-finger_salute, , <lora:output_models:1>
<元データ>
↓
<生成結果>




あんまりガチャを回していませんが、特徴は大分捉えられていると思います。絵柄は似たモデルを前提にするとより近づけやすくなるかなと思います
参照:https://blog.14nigo.net/2023/03/trytocreatelora.html?m=1

コメント
[…] 関連記事:【Colab】StableDiffusionのLoraを追加学習して特定のアニメキャラを生成する […]