
こんにちは、ミナピピン(@python_mllover)です!
今回はherokuのデータベースにPythonで収集した情報を保存する手順を紹介したいと思います。
herokuの基本的なことについては以下の記事に記載しておりますので、まずそちらを参考としてください!
関連記事:Python製プログラムを「Heroku scheduler」を使って無料で定期実行する
Herokuにポスグレを追加する
# herokuにログインする $ heroku login
# プロジェクトに接続
$ heroku git:remote -a (プロジェクト名)
Heroku で PostgreSQL を使うために、アドオンを追加します。
$ heroku addons:add heroku-postgresql
アドオンを追加したらデータベースを作成します。
#データベースを作成 $ heroku addons:create heroku-postgresql:hobby-dev
ここで出てくるhobby-devとはherokuのプラン名でこれを指定することで無料でDBを作成できます。ただし1万行までしか書き込みができないみたいです。
しかもこれはアプリ単体ではなくアカウント全体の話みたいです。これはちょっと痛いですね・・・とりあえず1万行超えたときの無難な対応は有料プランに移行する、というところみたいです。
参考:PostgreSQL のプランを Free から Hobby に移行する(Heroku) – ブログ
他にもアプリの仕様として会員情報を保存するようなものでなければ、都度別の場所にバックアップを取ったりcsvに吐き出しておくなどして無料プランでやりくりすることもできそうです。
参考:Heroku postgresqlアドオンの無料プランで制限に達したとき | ikapblog
参考:herokuのデータベースをリセット/リストア/再構築する – Qiita
参考:MetabaseをHerokuで使って、10000行を超えて無料の限界が来たときの対処法 | Be full stack
DB情報を見る
下記のコマンドでHerokuのDB情報を見ることができます。
$ heroku pg:info
<実行結果>
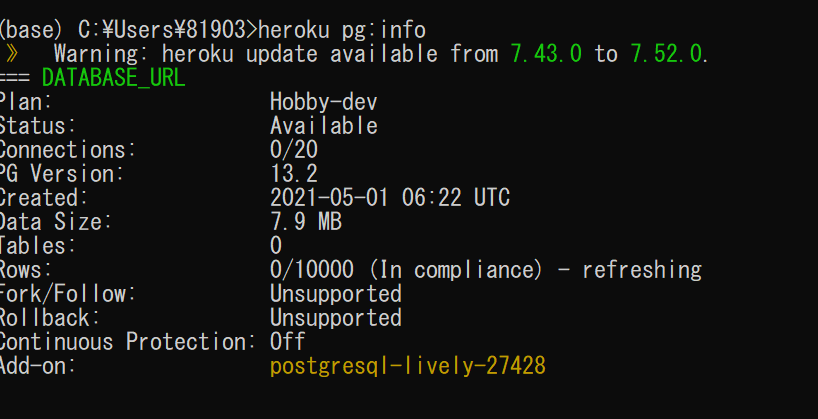
データベースのURLを確認する
heroku上のデータベースのURLを確認する
$ heroku run python
>>> a = os.environ.get('DATABASE_URL')
>>> print(a)
postgres://~
このURLは次で使用するのでコピペしてどこかにメモっておきましょう。
Pythonでスクレピングした情報をherokuのデータベースに書き込む
<main.py>
# ライブラリの読み込み
import requests
import json
from sqlalchemy import create_engine
from datetime import datetime
import pandas as pd
# データベースへ接続(自身のサーバーのデータベースのURLを入力してください)
engine = create_engine('postgresql://~', echo = False)
# 取得したデータをデータフレームにする
for i in range(10):
data_list.append([f"first_{i}",f"last_{i}", i])
df = pd.DataFrame(data_list,columns=['first_name','last_name','age'])
# テーブルに書き込む
df.to_sql('data_list', con = engine, if_exists='append')
# データベースの中身を確認する(デバック用)
print(engine.execute('SELECT * FROM data_list').fetchall())
<reqirement.txt>
pandas==1.2.0 requests==2.25.1 numpy==1.19.4 sqlalchemy==1.4.12
<runtime.txt>
python-3.7.10
<Procile>
web: python main.py
これをherokuにデプロイしてコードが動くかを確認します。
# herokuにコードをデプロイする $ git add . $ git commit $ git push heroku master
# heroku上のPyファイルを実行する $ heroku run python main.py
エラーなく↓みたいな取得した情報がコンソール上にプリントされれば成功です。
[['first_0','last_0',0]~~~]
定期的に実行する場合は以下の記事を参考にしてください!
関連記事:Python製プログラムを「Heroku scheduler」を使って無料で定期実行する
ご質問などございましたらmentaにて受け付けております!
では~
関連記事:【Python】Heroku+Flaskでサーバレスアプリをデプロイする

コメント
[…] 関連記事:【Python】Herokuのデータベースにスクレイピングしたデータを保存する […]