
こんにちは、ミナピピン(@python_mllover)です!
今回はスクレイピングしたwebサイトのテーブルタグの中の情報をデータフレームにして効率良く処理する方法について紹介したいと思います。
pandasでテーブルタグ内のテキスト情報をスクレイピングする
スクレイピングはrequestsやseleniumで行いますが、pandasのpd.read_html()というメソッドを使用することでURL内のテーブルタグの情報をデータフレームとして取得することができます。
以下はヤフーファイナンスの3558(ロコンド)の株価の時系列情報を取得してみた例です
import pandas as pd dfs = pd.read_html(f'https://m.finance.yahoo.co.jp/stock/historicaldata?code=3558.T') dfs[0]
<実行結果>
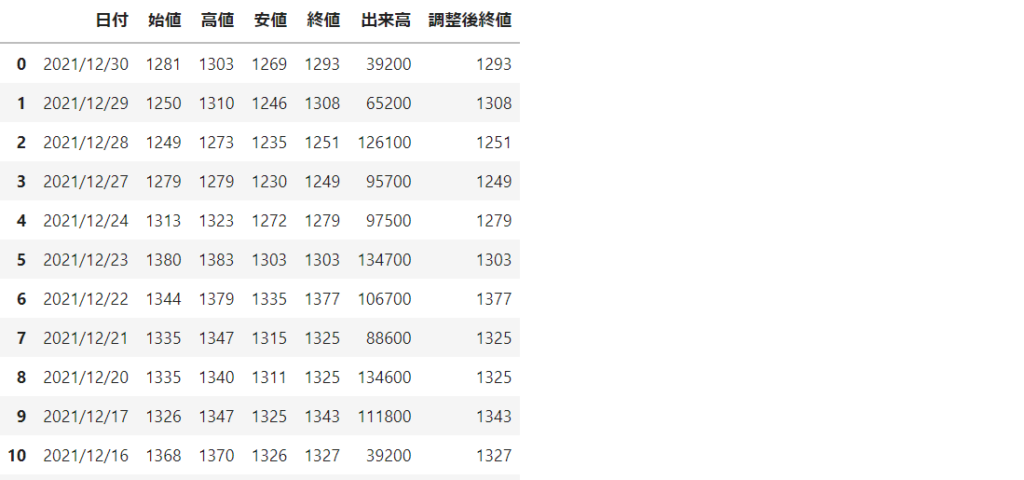
これrequestsやseleniumとかでやろうとすると結構手間は掛かるので非常に便利ですが、内部の処理の詳細がよく分からないので依存しすぎるのもちょっと怖い感じがします。
でも動いているからヨシ!
小ネタ・注意点
ウェブサイトによってはテーブルの情報をJSで動的生成しているものがあり、そういった場合はpd.read_table()でテーブル情報を取得できない時があります。
スクレイピングができないときはSeleniumでJSでテーブルが動的生成された後のHTMLを対象とするとテーブル情報をデータフレームとして取得できます。
参考記事:【Python】「Selenium」を使ってブラウザを自動操作する

コメント
First time here, haha