
今回は業務で協調フィルタリング(ユーザーベース)を用いたレコメンドロジックをPythonで実装した際のメモになります。(ユーザーベースとアイテムベースの違いは以下参照)
関連記事:【Python】レコメンドでよく使われる機械学習アルゴリズムの一覧とコード実装
使用するデータセットはKaggleに用意されているレコメンド用のアニメ視聴データです。簡単なロジックの仕組みとしてはメモリベースでユーザーの視聴履歴からコサイン類似度を計算し、似たようなユーザーを抽出してその評価数値から上位のものをレコメンドするというユーザーベースのレコメンドロジックになります。
データセット→ Anime Recommendations Database | Kaggle
Contents
前処理
データの読み込み
まずはデータを読み込みます。
import numpy as np import pandas as pd df_rating = pd.read_csv(r"C:\Users\~~\archive\rating.csv") df_label = pd.read_csv(r"C:\Users\~~\archive\anime.csv") # 量が多いので500000件以上レビューがある人気アニメに絞る df_label =df_label[df_label['members']>500000]
今回は実装するだけなので雑に足切りしましたが、本来は検証しつつ足切りのラインは決めた方がいいです。
anime_idをキーにしてデータセットを内部結合する
# anime_idをキーにして内部結合する df = pd.merge(df_rating, df_label, on='anime_id', how='inner')[['user_id','anime_id','name','rating_x']]
↓こんな感じになっています。

ダミー変数のマートを作る
次に協調フィルタリングで用いる各ユーザーのコサイン類似度やユークリッド距離の計算するために必要なマートを作成します。具体的にはユーザーID×アニメタイトルの行列データを作成します。
# ユーザーID×アニメタイトル users_movies = df.pivot_table(index="user_id",columns="name",values="rating_x")
変数 users_moviesの中身は↓のようになっています。

ですが、このままだと欠損値があり計算ができないので、0埋めします。また数値の大きさを統一するために正規化を行います。
#欠損値を0埋めする users_movies = users_movies.fillna(0) #正規化 users_movies_norm = users_movies.apply(lambda x:(x-np.mean(x))/(np.max(x)-np.min(x)),axis=1) users_movies_norm = users_movies_norm.fillna(0)
これでusers_movies_norm の中身は↓のようになっています。

コサイン類似度を計算する
# コサイン類似度を計算 from scipy.sparse import csr_matrix from sklearn.metrics.pairwise import cosine_similarity users_movies_sparse = csr_matrix(users_movies_norm.values) user_sim = cosine_similarity(users_movies_sparse) user_sim_df = pd.DataFrame(user_sim,index=users_movies_norm.index,columns=users_movies_norm.index) (予備:#スペックが足りない場合はインデックスで読み込むデータを一部のみにする) from scipy.sparse import csr_matrix from sklearn.metrics.pairwise import cosine_similarity users_movies_sparse = csr_matrix(users_movies_norm.iloc[:20000].values) user_sim = cosine_similarity(users_movies_sparse) user_sim_df = pd.DataFrame(user_sim,index=users_movies_norm.iloc[:20000].index,columns=users_movies_norm.iloc[:20000].index)
1列目のユーザーに対する類似ユーザー上位100人を抽出する
# ユーザーID1と類似度の高いユーザー上位100人を抽出する sim_users = user_sim_df.iloc[0,:].sort_values(ascending=False)[0:100] print(sim_users) # ユーザーのインデックスをリストに変換 sim_users_list = sim_users.index.tolist() print(sim_users_list)
類似ユーザーの視聴データのみのmartを作る
sim_df = pd.DataFrame()
count = 0
# 類似度の高い上位ユーザーのスコア情報を集めてデータフレームに格納
for i in users_movies_norm.iloc[:,0].index:
if i in sim_users_list:
sim_df = pd.concat([sim_df,pd.DataFrame(users_movies_norm.iloc[count]).T])
count += 1
本来データフレームをfor文で回すのはあまり良い手法ではないので、where系の関数を用いて処理した方がいいと思います。
対象ユーザーの視聴済みアニメを抽出して計算から除外する
# ユーザーID1の視聴済みアニメを取得する
user_list = users_movies[users_movies.index==1].T
user_list = user_list[user_list[1]!=0].T.columns.tolist()
# 未視聴のアニメリストを作る
result = list(set(users_movies_norm.columns) - set(user_list))
# 未視聴のアニメのスコアデータ
users_movies_norm = users_movies_norm[result]
#各アニメ評点の平均をとる
score = []
for i in range(len(users_movies_norm.columns)):
mean_score = users_movies_norm.iloc[:,i].mean()
name = users_movies_norm.iloc[:,i].name
score.append([name, mean_score])
# 集計結果からスコアの高い順にソートする
score_data = pd.DataFrame(score).sort_values(1)
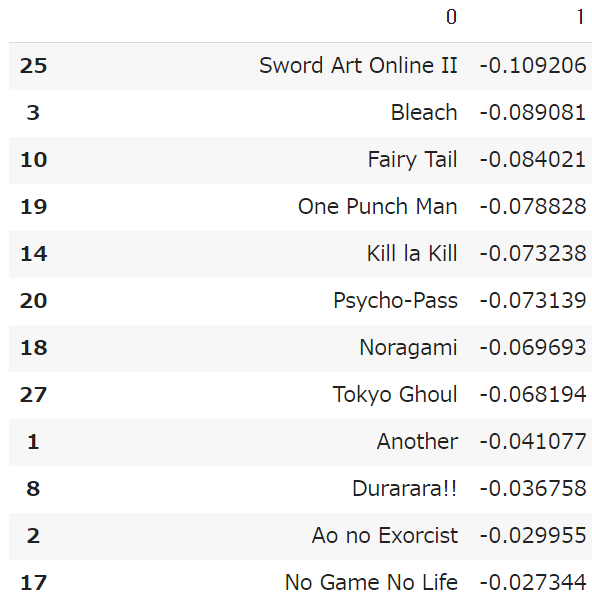
ソードアートオンライン2、ブリーチ、フェアリーテイル辺りをオススメすればよいという結果になります。
・googlecolabのリンク



コメント
[…] 前回記事:【Python】協調フィルタリングでアニメのレコメンドシステムを実装する(ユーザーベース) […]