
今回はアイテムベースのレコメンドロジックをPythonで実装する方法をメモしておきます。
前回記事:【Python】協調フィルタリングでアニメのレコメンドシステムを実装する(ユーザーベース)
データの前処理
今回はアイテムベースのレコメンドシステムとしたいので、最終的な行列としては以下のようなイメージになります。
ユーザーID① ユーザーID② ユーザーID③…
商品①
商品②
商品③
…
前処理は前回のユーザーベースでのレコメンドの際に使用したアニメの視聴履歴を用います。
データセット→ Anime Recommendations Database | Kaggle
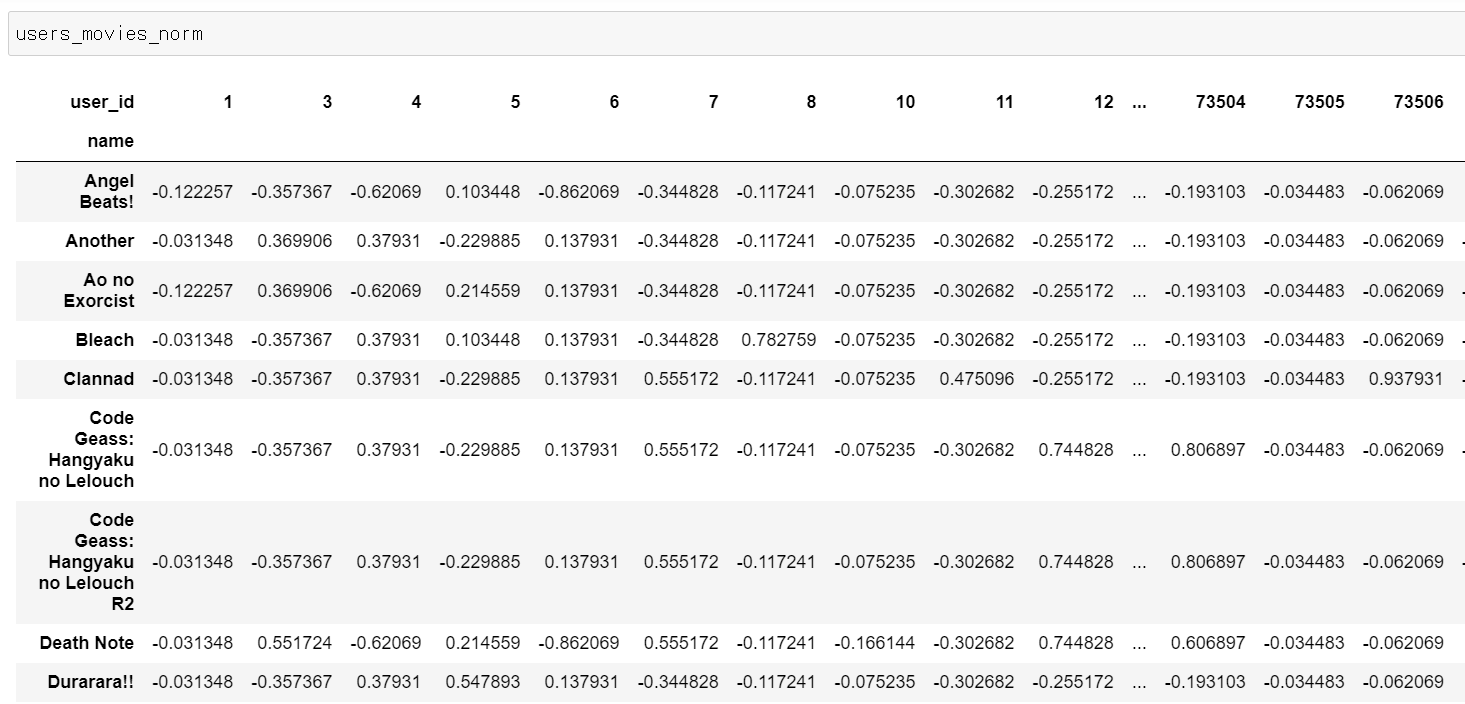
今回アイテムベースなので前回作成したマートを.Tで縦横を入れ替える必要があります。
<前処理>
import numpy as np import pandas as pd df_rating = pd.read_csv(r"C:\Users\~~\archive\rating.csv") df_label = pd.read_csv(r"C:\Users\~~\archive\anime.csv") # 量が多いので500000件以上レビューがある人気アニメに絞る df_label =df_label[df_label['members']>500000] # anime_idをキーにして内部結合する df = pd.merge(df_rating, df_label, on='anime_id', how='inner')[['user_id','anime_id','name','rating_x']] # ユーザーID×アニメタイトル users_movies = df.pivot_table(index="user_id",columns="name",values="rating_x") #欠損値を0埋めする users_movies = users_movies.fillna(0) #正規化 users_movies_norm = users_movies.apply(lambda x:(x-np.mean(x))/(np.max(x)-np.min(x)),axis=1) users_movies_norm = users_movies_norm.fillna(0) # アイテムベースのレコメンドにしたいので縦横を入れ替える users_movies_norm = users_movies_norm.T
<実行結果>
Pythonでk近傍法のレコメンドロジックを実装する
では、実際にこのk近傍法のアルゴリズムと事前に処理したデータセットを使ってモデルを構築します。Pythonで実装するにはScikit-learnという機械学習用ライブラリの関数で実装可能です。
# 使用するライブラリのインポート
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
nodes = len(users_movies_norm)
# knnのインスタンスを呼び出し
knn = NearestNeighbors(n_neighbors=nodes, algorithm= 'brute', metric= 'cosine')
# 前処理したデータセットでモデルを訓練
model_knn = knn.fit(users_movies_norm)
# 対象のアニメを選択
Anime = 'Bleach'
distance, indice = model_knn.kneighbors(users_movies_norm.iloc[users_movies_norm.index== Anime].values.reshape(1,-1),n_neighbors=nodes)
for i in range(0, len(distance.flatten())):
if i == 0:
print('Recommendations if buy like the category {0}:\n'.format(users_movies_norm[users_movies_norm.index== Anime].index[0]))
else:
print('{0}: {1} with distance: {2}'.format(i, users_movies_norm.index[indice.flatten()[i]],distance.flatten()[i]))
<実行結果>
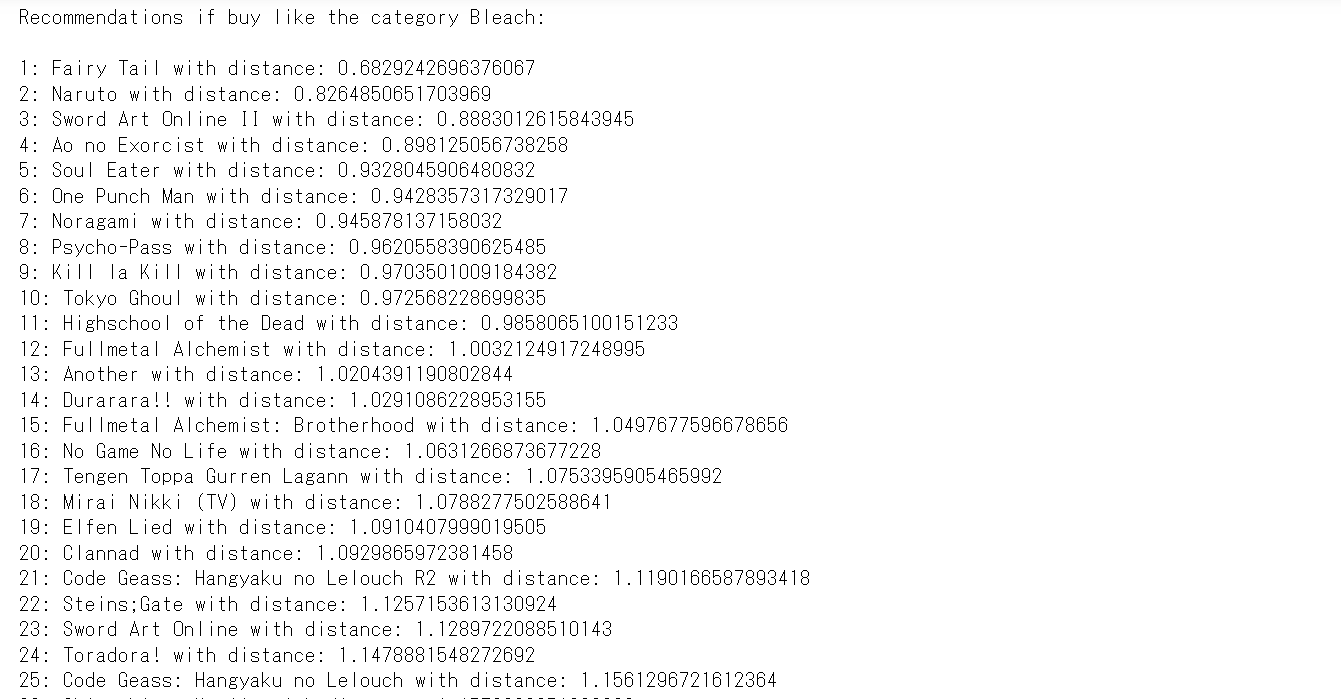
こういった感じでブリーチを見ているユーザーと距離が近いのはフェアリーテイルとNARUTOを見ているユーザーなので、これらをレコメンドでオススメしてあげればよいという事になります。
参照:https://www.codexa.net/collaborative-filtering-k-nearest-neighbor/


コメント