
業務で画像分類の手法に調査したので、その中で手法の候補の1つに上がった「Bag of visual words」について調査しました。
Bag of visual wordsの簡単な仕組み
「Bag Of Visual Words」は、画像の特徴量を1次元のベクトルに次元圧縮する手法です。
Bag of Wordsとか、Bag of Featuresとか、いろいろな名前で呼ばれています。
k-meansでk個のカテゴリに分類し、各カテゴリ毎にそのカテゴリに入る特徴量の個数を集計してヒストグラムを作成します。テストフェーズでは、KNNを使ってどのクラスに分類されるのかを判定します。
<イメージ>
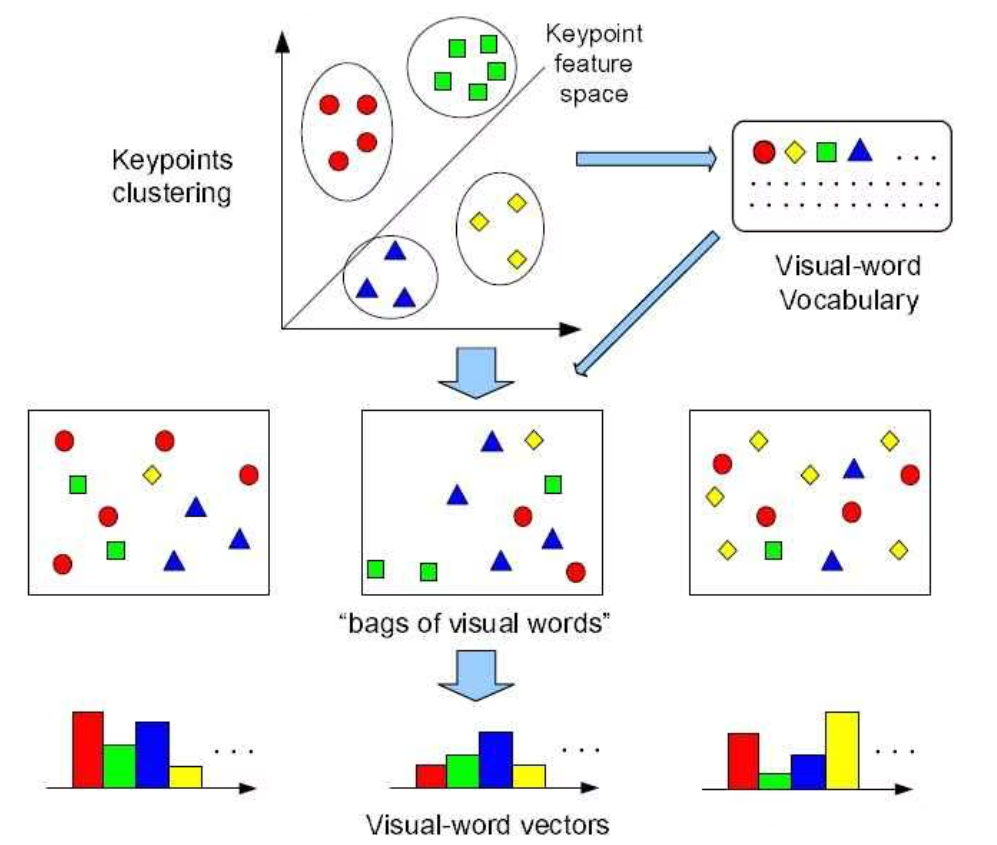
引用:イリノイ大学 http://www.ifp.illinois.edu/~yuhuang/sceneclassification.html
PythonでBag of visual wordsを実装する
前準備
icrawlerで学習の元になる画像データをスクレイピングします。
$ pip install icrawler
from icrawler.builtin import BingImageCrawler
# 犬の画像を集める
crawler = BingImageCrawler(storage={"root_dir": '犬'.strip()})
crawler.crawl(keyword='犬', max_num=100)
# ネコの画像を集める
crawler = BingImageCrawler(storage={"root_dir": '猫'.strip()})
crawler.crawl(keyword='猫', max_num=100)
関連記事:【Python】icrawlerを使ってウェブから画像を一括でダウンロード・スクレイピングする
Bag of visual wordsで犬猫の画像分類
まずは画像データの情報をCLASSID(0,1)と画像ファイルのパスに整形します。
import os
import pandas as pd
dataset = []
#IDと画像のPATHを格納したデータフレームを作る
for i in os.listdir('/content/犬'):
dataset.append([0,f'/content/犬/{i}'])
for i in os.listdir('/content/猫'):
dataset.append([1,f'/content/猫/{i}'])
# dataset
データの前処理が終わったので、この画像データを使った分類器に学習させていきます。
import cv2
import numpy as np
# 辞書サイズ(2なのは犬・猫の2種類に分類するモデルであるため)
dictionarySize = 2
# KAZE特徴量抽出器
detector = cv2.KAZE_create()
# Bag Of Visual Words分類器
bowTrainer = cv2.BOWKMeansTrainer(dictionarySize)
# 各画像を分析
for i, (classId, data_path) in enumerate(dataset):
# 進捗表示
# print(classId, data_path)
# グレースケールで画像読み込み
gray = cv2.imread(data_path, 1)
gray = cv2.resize(gray, dsize=(300, 300))
# 特徴点とその特徴を計算
keypoints, descriptors= detector.detectAndCompute(gray, None)
# intからfloat32に変換
if descriptors is not None:
descriptors = descriptors.astype(np.float32)
# 特徴ベクトルをBag Of Visual Words分類器にセット
bowTrainer.add(descriptors)
# Bag Of Visual Words分類器で特徴ベクトルを分類
codebook = bowTrainer.cluster()
# 訓練完了
print("train finish")
これで分類器が作成できたので、実際に画像を分類予測してみます。
# 予測
# KNNを使って総当たりでマッチング
matcher = cv2.BFMatcher()
# Bag Of Visual Words抽出器
bowExtractor = cv2.BOWImgDescriptorExtractor(detector, matcher)
# トレーニング結果をセット
bowExtractor.setVocabulary(codebook)
# グレースケールで読み込み
gray = cv2.imread('/xxxx.jpg', 1)
# 画像をリサイズする
gray = cv2.resize(gray, dsize=(300, 300))
# 特徴点と特徴ベクトルを計算
keypoints, descriptors= detector.detectAndCompute(gray, None)
if descriptors is not None:
# intからfloat32に変換
descriptors = descriptors.astype(np.float32)
# Bag Of Visual Wordsの計算
bowDescriptors = bowExtractor.compute(gray, keypoints)
# 結果表示
className = {
"0": "犬",
"1": "猫",
}
actual = "???"
# 分類確率が最大のインデックスを特定
max_index = np.argmax(bowDescriptors[0])
print(max_index, className[f"{max_index}"])
else:
print('fail')
参照:https://jp.mathworks.com/help/vision/ug/image-classification-with-bag-of-visual-words.html
参照:https://qiita.com/hitomatagi/items/883770046de5746a5deb

Sebastian Raschka;Vahid Mirjalili/株式会社クイープ 訳/福島 真太朗 監訳 インプレス 2020年10月22日頃
コメント