Contents
はじめに
近年、ChatGPTを活用したアプリケーションが急速に普及しています。本記事では、 LangChain × Streamlit × ChatGPT を組み合わせて、 情報検索機能を備えたAIチャットアプリ を開発する方法を詳細に解説します。
1. プロジェクトの概要
本記事で作成するアプリケーションは以下の特徴を持ちます。
- LangChain を利用してGPT-4との対話を最適化
- ChromaDB を使用した情報検索機能
- Streamlit による直感的なUI
- .envファイルでOpenAI APIキーを管理
- 会話履歴を保持し、インタラクティブな体験を実現
2. 必要な環境とインストール
まず、必要なライブラリをインストールしましょう。要件は下記になります。バージョンが違うと関数の呼び出しや依存性でエラーになるのでバージョンも合わせてください
openai==1.61.1 langchain==0.2.0 chromadb== 0.3.29 langchain-community==0.2.0 langchain-openai==0.1.10 langchainhub==0.1.21 streamlit-chat==0.1.1
また実行ディレクトリに「resources」というフォルダを作成しそこに「note.txt」というファインチューニングさせる情報を記述したテキストファイルを配置してください
<resources/note.txt>
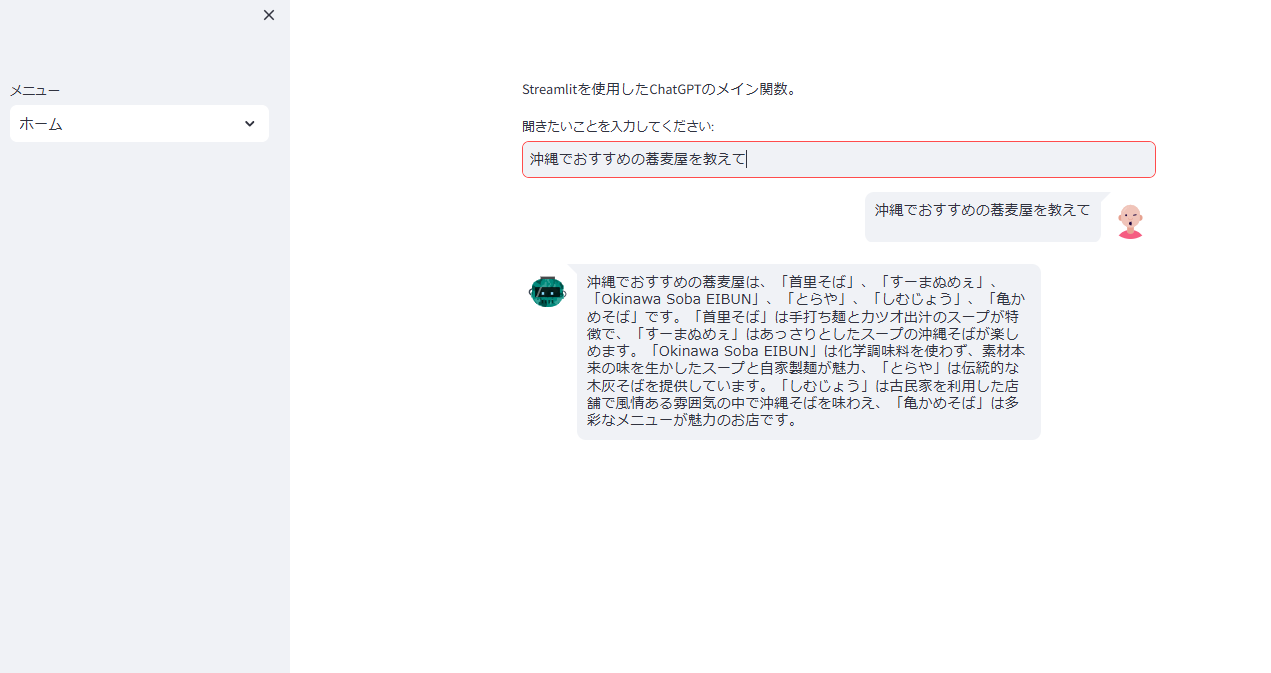
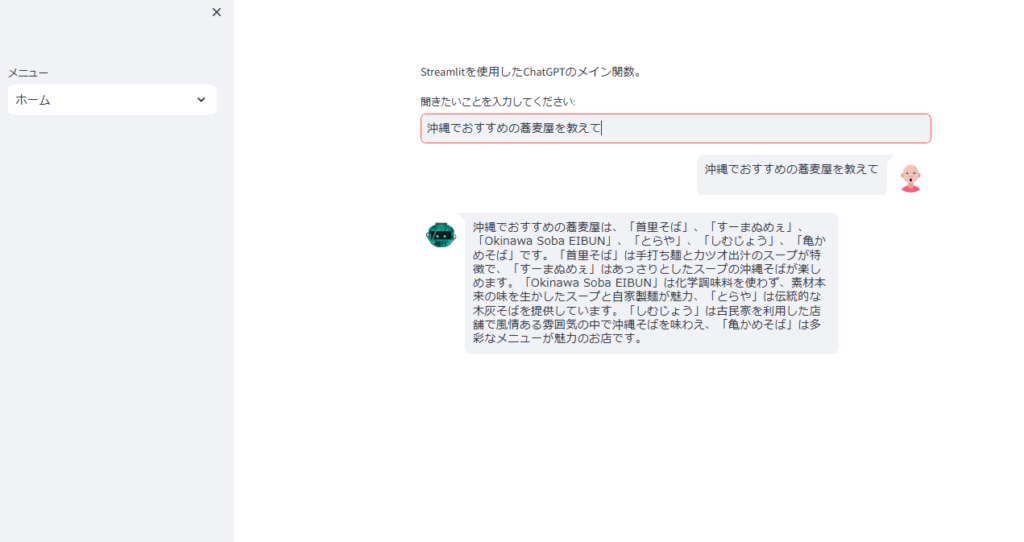
那覇市でおすすめの沖縄そばのお店をいくつかご紹介します。 「首里そば」 は首里城近くにある人気店で、手打ち麺とカツオ出汁のスープが特徴です。行列ができることも多いため、早めの来店がおすすめです。 次に、「すーまぬめぇ」 は、古民家を改装した雰囲気の良い店内で、あっさりとしたスープの沖縄そばを楽しめるお店です。落ち着いた空間で食事をしたい方にぴったりです。 また、「Okinawa Soba EIBUN」 は、化学調味料を使わず、素材本来の味を生かしたスープと自家製麺が魅力のお店です。健康志向の方や、こだわりの沖縄そばを味わいたい方におすすめです。 さらに、「とらや」 では、伝統的な 木灰そば を提供しており、独特の風味とコシのある麺が特徴です。昔ながらの沖縄そばの味を堪能したい方に最適です。 一方、「しむじょう」 は、古民家を利用した店舗で、風情ある雰囲気の中、伝統的な沖縄そばを味わえます。観光で訪れる方にも人気が高く、沖縄らしい景観とともに食事を楽しめます。 最後に、「亀かめそば」 は、地元の方々にも愛されるお店で、多彩なメニューが魅力です。シンプルながらも深みのある味わいの沖縄そばを提供しており、コストパフォーマンスの良さも魅力の一つです。 那覇市を訪れた際には、ぜひこれらの名店を巡り、それぞれ異なる沖縄そばの味を楽しんでみてください。
3. コードの詳細解説
3.1 OpenAI APIの設定
まず、ChatGPTのAPIキーの設定を行います。
import openai
import streamlit as st
# OpenAI APIキーの取得
api_key = "sk-proj-xxxxx"
if not api_key:
st.error("OPENAI_API_KEY が設定されていません。環境変数または .env ファイルを確認してください。")
st.stop()
# OpenAI APIキーを設定
openai.api_key = api_key
3.2 ChatGPT の初期化
LangChain を使用して GPT-4 のモデルを初期化します。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_key=api_key,
model_name="gpt-4",
)
✅ ChatOpenAI を使用することで、 プロンプト管理や対話の最適化 が可能になります。
3.3 ChromaDB を使ったベクターストアの作成
本アプリでは、情報検索機能を強化するために ChromaDB を活用 します。
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from pathlib import Path
def initialize_vector_store() -> Chroma:
"""ベクターストアの初期化"""
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
vector_store_path = "./resources/note.db"
if Path(vector_store_path).exists():
vector_store = Chroma(embedding_function=embeddings, persist_directory=vector_store_path)
else:
loader = TextLoader("resources/note.txt", encoding='utf-8')
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vector_store = Chroma.from_documents(
documents=splits, embedding=embeddings, persist_directory=vector_store_path
)
return vector_store
✅ ChromaDB を使うことで、ユーザーの質問に適した情報を検索し、回答の精度を向上させる ことができます。
3.4 Retriever の設定
ベクターストアから情報を取得するための Retriever を初期化 します。
from langchain_core.vectorstores import VectorStoreRetriever
def initialize_retriever() -> VectorStoreRetriever:
"""Retrieverを初期化"""
vector_store = initialize_vector_store()
return vector_store.as_retriever()
✅ Retriever を利用すると、 ベクターストアに保存された情報を効率的に検索 できます。
3.5 LangChain のチェーンを定義
ユーザーの入力を受け取り、 検索結果を元に ChatGPT の回答を生成 します。
from langchain import hub
from langchain.schema import AIMessage
def initialize_chain():
"""LangChainのチェーンを初期化"""
prompt = hub.pull("rlm/rag-prompt")
retriever = initialize_retriever()
def chain(user_input):
try:
retrieved_docs = retriever.get_relevant_documents(user_input)
context = "\n".join([doc.page_content for doc in retrieved_docs])
formatted_prompt = prompt.format(context=context, question=user_input)
response = llm.invoke(formatted_prompt)
return response
except Exception as e:
st.error(f"エラーが発生しました: {e}")
return AIMessage(content="申し訳ありません、現在問題が発生しています。後でもう一度お試しください。")
return chain
✅ LangChain のプロンプトを最適化し、回答の質を向上 させています。
3.6 Streamlit を用いたUIの構築
Streamlit を活用して、 直感的なチャットUI を作成します。
import streamlit as st
from streamlit_chat import message
def main() -> None:
# サイドバーメニューの作成
menu = ["ホーム", "ヘルプ"]
choice = st.sidebar.selectbox("メニュー", menu)
if choice == "ホーム":
"""Streamlitを使用したChatGPTのメイン関数"""
chain = initialize_chain()
# チャット履歴の初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# ユーザー入力の監視
user_input = st.text_input("聞きたいことを入力してください:")
if user_input:
st.session_state.messages.append({"role": "user", "content": user_input})
with st.spinner("GPTが入力中です..."):
ai_response = chain(user_input)
st.session_state.messages.append({"role": "assistant", "content": ai_response.content})
# メッセージの表示
for msg in st.session_state.messages:
if msg['role'] == 'user':
message(msg['content'], is_user=True, avatar_style="personas")
elif msg['role'] == 'assistant':
message(msg['content'], is_user=False, avatar_style="bottts")
if __name__ == "__main__":
main()
✅ Streamlitを活用して、ノーコード感覚でUIを構築 できます。
まとめ
コード全体は下記になります
from pathlib import Path
import streamlit as st
from langchain import hub
from langchain.schema import AIMessage, HumanMessage
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_core.vectorstores import VectorStoreRetriever
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
import openai
from pathlib import Path
from streamlit_chat import message
# OpenAI APIキーの取得
api_key = "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"
if not api_key:
st.error("OPENAI_API_KEY が設定されていません。環境変数または .env ファイルを確認してください。")
st.stop()
# OpenAI APIキーの設定
openai.api_key = api_key
# ChatOpenAIの初期化
llm = ChatOpenAI(
openai_api_key=api_key,
model_name="gpt-4",
)
def initialize_vector_store() -> Chroma:
"""Initialize the VectorStore."""
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
vector_store_path = "./resources/note.db"
if Path(vector_store_path).exists():
vector_store = Chroma(embedding_function=embeddings, persist_directory=vector_store_path)
else:
# print()
loader = TextLoader("resources/note.txt", encoding='utf-8')
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vector_store = Chroma.from_documents(
documents=splits, embedding=embeddings, persist_directory=vector_store_path
)
return vector_store
def initialize_retriever() -> VectorStoreRetriever:
"""Retrieverを初期化します。"""
vector_store = initialize_vector_store()
return vector_store.as_retriever()
def initialize_chain():
"""LangChainを初期化します。"""
prompt = hub.pull("rlm/rag-prompt")
retriever = initialize_retriever()
def chain(user_input):
try:
retrieved_docs = retriever.get_relevant_documents(user_input)
context = "\n".join([doc.page_content for doc in retrieved_docs])
formatted_prompt = prompt.format(context=context, question=user_input)
response = llm.invoke(formatted_prompt)
return response
except Exception as e:
st.error(f"エラーが発生しました: {e}")
return AIMessage(content="申し訳ありません、現在問題が発生しています。後でもう一度お試しください。")
return chain
def main() -> None:
# サイドバーメニューの作成
menu = ["ホーム", "ヘルプ"]
choice = st.sidebar.selectbox("メニュー", menu)
if choice == "ホーム":
"""Streamlitを使用したChatGPTのメイン関数。"""
chain = initialize_chain()
# チャット履歴の初期化
if "messages" not in st.session_state:
st.session_state.messages = []
# ユーザー入力の監視
user_input = st.text_input("聞きたいことを入力してください:")
if user_input:
# st.session_state.messages.append(HumanMessage(content=user_input))
st.session_state.messages.append({"role": "user", "content": HumanMessage(content=user_input)})
with st.spinner("GPTが入力中です..."):
# response = chain(user_input)
ai_response = chain(user_input)
# st.session_state.messages.append(AIMessage(content=response.content))
st.session_state.messages.append({"role": "assistant", "content": AIMessage(content=ai_response.content)})
# メッセージの表示
for msg in st.session_state.messages:
print(msg)
if msg['role'] == 'user':
message(msg['content'].content, is_user=True, avatar_style="personas")
elif msg['role'] == 'assistant':
message(msg['content'].content, is_user=False, avatar_style="bottts")
elif choice == "ヘルプ":
st.title("ヘルプ")
st.write("ここにヘルプ情報を記載します。")
if __name__ == "__main__":
main()
<実行結果>
本記事では、 LangChain × Streamlit × ChatGPT を活用したAIチャットアプリの開発手順 を詳しく解説しました。
関連記事:streamlit-authenticatorでログイン機能を追加する
関連記事:StreamlitでCSVダウンロード機能を実装する方法

コメント