前回のあらすじ
こんにちは、ミナピピン(@python_mllover)です!前回はEDINETのAPIを使用して決算書をpdf出力して取得する処理を紹介しました。

ですが、PDFに記載してある決算情報をcsvに変換して分析ができる形に整形するのは非常に手間が掛かります。
決算情報をXBRLにしてXBRLをスクレイピングするという手もありますが、XBRLはHTMLやXMLと違ってひと癖ある文書フォーマットで非常に骨が折れます。。。
参考:https://qiita.com/teatime77/items/3ed6d4cd27f6440e163a
てな感じで、うわぁめんどくせぇなあ・・・っと思っていたのですが有志の方が素晴らしいツールを作成してくれており、それを使用したところ一発でスクレピングとデータ整形が完了したので紹介しておきます。
ツールの紹介
・ツールの保管場所
https://github.com/teatime77/xbrl-reader
・ツールの使い方
http://lkzf.info/xbrl/doc/exec.html#zip
・参考記事
https://qiita.com/teatime77/items/3ed6d4cd27f6440e163a
ドキュメントに記載されていますが、大まかな使い方としてはEDINETからタクソノミをダウンロードして配置しxbrl-reader>python内にある各PYファイルを以下のように実行してください。
python download.py python extract.py python summary.py fix
過去五年分の決算情報を取得するので数GBの要領と3日くらいの日数が掛かります。処理が完了すると、python>dataにsummary-0~2.csvが作成されます。
summary.csvを整形
以下のコードを実行してsummary.csvを整形します。
import pandas as pd
# summary-0~2のパスをご自身のPCの作業環境に合う形で指定してください
df提出日時点 = pd.read_csv(r"C:\〇〇\xbrl-reader\python\data\summary-0.csv", parse_dates=[ '提出日', '当事業年度開始日', '当事業年度終了日', '会計期間終了日' ])
df時点 = pd.read_csv(r"C:\〇〇\xbrl-reader\python\data\summary-1.csv")
df期間 = pd.read_csv(r"C:\〇〇\xbrl-reader\python\data\summary-2.csv")
# 長い項目名を短くする。
df時点 = df時点.rename(columns={
'1株当たり純資産額': '1株当たり純資産',
'平均年齢(年)' : '平均年齢',
'平均勤続年数(年)': '平均勤続年数',
})
df期間 = df期間.rename(columns={
'売上総利益又は売上総損失(△)' :'売上総利益',
'経常利益又は経常損失(△)' : '経常利益',
'営業利益又は営業損失(△)' : '営業利益',
'当期純利益又は当期純損失(△)' :'純利益',
'税引前当期純利益又は税引前当期純損失(△)':'税引前純利益',
'1株当たり当期純利益又は当期純損失(△)' :'1株当たり純利益',
'親会社株主に帰属する当期純利益又は親会社株主に帰属する当期純損失(△)': '親会社株主に帰属する純利益',
'潜在株式調整後1株当たり当期純利益' :'調整1株当たり純利益',
'現金及び現金同等物の増減額(△は減少)' :'現金及び現金同等物の増減'
})
# 平均給料額の桁がおかしいのでパターンに合わせて調整
print(df時点[(df時点['平均年間給与'] < 10000) | (10000*10000 < df時点['平均年間給与'])]['平均年間給与'])
df時点.loc[(df時点['平均年間給与'] < 10000) | (10000*10000 < df時点['平均年間給与']), '平均年間給与'] = pd.np.nan
# 有価証券報告書だけ抽出
df提出日時点 = df提出日時点[ df提出日時点['報告書略号'] == "asr" ]
df時点 = df時点[ df時点['報告書略号'] == "asr" ]
df期間 = df期間[ df期間['報告書略号'] == "asr" ]
# コンテキストごとにデータを抜き出す。
df提出日時点 = df提出日時点.reset_index()
df当期連結時点 = df時点[df時点['コンテキスト'] == '当期連結時点'].reset_index()
df当期個別時点 = df時点[df時点['コンテキスト'] == '当期個別時点'].reset_index()
df当期連結期間 = df期間[df期間['コンテキスト'] == '当期連結期間'].reset_index()
df当期個別期間 = df期間[df期間['コンテキスト'] == '当期個別期間'].reset_index()
df前期連結時点 = df時点[df時点['コンテキスト'] == '前期連結時点'].reset_index()
df前期個別時点 = df時点[df時点['コンテキスト'] == '前期個別時点'].reset_index()
df前期連結期間 = df期間[df期間['コンテキスト'] == '前期連結期間'].reset_index()
df前期個別期間 = df期間[df期間['コンテキスト'] == '前期個別期間'].reset_index()
assert len(df提出日時点) == len(df当期連結時点) == len(df当期個別時点) == len(df当期連結期間) == len(df当期個別期間) == len(df前期連結時点) == len(df前期個別時点) == len(df前期連結期間) == len(df前期個別期間)
# 前期の項目名に "前期" を付加。
df前期連結時点 = df前期連結時点.rename(columns={ '資産':'前期資産' })
df前期連結期間 = df前期連結期間.rename(columns={ '売上高':'前期売上高', '純利益':'前期純利益' })
df前期個別期間 = df前期個別期間.rename(columns={ '売上高':'前期売上高', '純利益':'前期純利益' })
# コンテキストごとに分かれているデータを一つにまとめる。
drop_columns = ['EDINETコード', '会計期間終了日', '報告書略号', 'コンテキスト', '平均年齢', '平均勤続年数', '平均年間給与', 'index' ]
df = pd.concat([
df提出日時点[['EDINETコード', '証券コード', '提出日', '会計期間終了日']],
df当期連結時点[ [x for x in df当期連結時点.columns if x not in drop_columns ] ],
df当期連結期間[ [x for x in df当期連結期間.columns if x not in drop_columns ] ],
df前期連結時点[['前期資産']],
df前期連結期間[['前期売上高', '前期純利益']],
df当期個別時点[[ '平均年齢', '平均勤続年数', '平均年間給与']],
],
axis=1)
assert len(df) == len(df提出日時点)
# 財務指標を計算する。
df['粗利益'] = df['売上高'] - df['売上原価']
df['売上高総利益率'] = df['粗利益'] / df['売上高']
df['売上高営業利益率'] = df['営業利益'] / df['売上高']
df['売上高経常利益率'] = df['経常利益'] / df['売上高']
df['売上高販管費率'] = df['販売費及び一般管理費'] / df['売上高']
df['総資本回転率'] = df['売上高'] / df['資産']
df['流動比率'] = df['流動資産'] / df['流動負債']
df['売上高変化率'] = (df['売上高'] - df['前期売上高']) / df['前期売上高']
df['純利益変化率'] = (df['純利益'] - df['前期純利益']) / df['前期純利益']
df['期首期末平均資産'] = (df['前期資産'] + df['資産']) / 2.0
df['総資産経常利益率'] = df['経常利益'] / df['期首期末平均資産']
df['総資産純利益率'] = df['純利益'] / df['期首期末平均資産']
df['総資産親会社株主に帰属する純利益率'] = df['親会社株主に帰属する純利益'] / df['期首期末平均資産']
df['自己資本'] = df['株主資本'].fillna(0) + df['評価・換算差額等'].fillna(0)
df['有利子負債'] = df['短期借入金'].fillna(0) + df['1年内返済予定の長期借入金'].fillna(0) + df['1年内償還予定の社債'].fillna(0) + df['長期借入金'].fillna(0) \
+ df['社債'].fillna(0) + df['転換社債型新株予約権付社債'].fillna(0) + df['コマーシャル・ペーパー'].fillna(0)
ここまで完了したら、EDINETコードと会社情報を紐づけるために以下のURLから必要なcsvダウンロードしてください。

EDINETコードリスト>ダウンロード対象>EDINETコードリスト
から「EdinetcodeDlInfo.csv」をダウンロードしてください。
(最新版でないと新規上場企業の証券コードが網羅できないことがあるため、keyerrorとなる場合があります)
ダウンロードが完了したら以下のコードを実行します。
# 会社情報のCSVを読み込む。(csvのパスは自身の実行環境に合わせてください)
df会社 = pd.read_csv(r"C:\Users\81903\jupyter notebook\dominono9様\EdinetcodeDlInfo.csv", encoding='cp932', skiprows=[0])
df会社 = df会社.set_index('EDINETコード')
# 会社名から "株式会社" を取り除く。
df会社['提出者名'] = df会社['提出者名'].apply(lambda x: x.replace('株式会社', '').strip())
# 会社名と業種をセットする。
df['会社名'] = df['EDINETコード'].map(lambda x: df会社.loc[x]['提出者名'])
df['業種'] = df['EDINETコード'].map(lambda x: df会社.loc[x]['提出者業種'])
# 列を並び替える
column_list = ['EDINETコード', '証券コード', '会社名','業種','提出日', '会計期間終了日', '従業員数', '平均臨時雇用人員', '所有株式数',
'発行済株式(自己株式を除く。)の総数に対する所有株式数の割合', '発行済株式総数', '連結子会社の数', '1株当たり純資産',
'自己資本比率', '現金及び現金同等物の残高', '資産', '流動資産', '固定資産', '有形固定資産', '無形固定資産',
'投資その他の資産', '負債', '流動負債', '短期借入金', '1年内償還予定の社債', '1年内返済予定の長期借入金',
'固定負債', '社債', '転換社債型新株予約権付社債', 'コマーシャル・ペーパー', '長期借入金', '純資産', '株主資本',
'資本金', '資本剰余金', '利益剰余金', '自己株式', '評価・換算差額等', '売上高', '売上原価', '売上総利益',
'販売費及び一般管理費', '給料及び手当', '減価償却費、販売費及び一般管理費', '研究開発費', '営業利益', '営業外収益',
'営業外費用', '支払利息', '経常利益', '特別利益', '特別損失', '税引前純利益', '法人税等', '純利益',
'親会社株主に帰属する純利益', '包括利益', '1株当たり純利益', '調整1株当たり純利益', '1株当たり配当額', '株価収益率',
'自己資本利益率', '営業活動によるキャッシュ・フロー', '減価償却費、営業活動によるキャッシュ・フロー',
'投資活動によるキャッシュ・フロー', '財務活動によるキャッシュ・フロー', '現金及び現金同等物の増減', '前期資産', '前期売上高',
'前期純利益', '平均年齢', '平均勤続年数', '平均年間給与', '粗利益', '売上高総利益率', '売上高営業利益率',
'売上高経常利益率', '売上高販管費率', '総資本回転率', '流動比率', '売上高変化率', '純利益変化率', '期首期末平均資産',
'総資産経常利益率', '総資産純利益率', '総資産親会社株主に帰属する純利益率', '自己資本', '有利子負債']
df = df.reindex(column_list, axis='columns')
# 結果をCSVファイルに出力する。(csvのパスは自身の実行環境に合わせてください)
df.to_csv(r"C:\〇〇\summary-join.csv", index=False)
summary-join.csvを開くと以下のような感じで決算情報がズラーと表示されます。
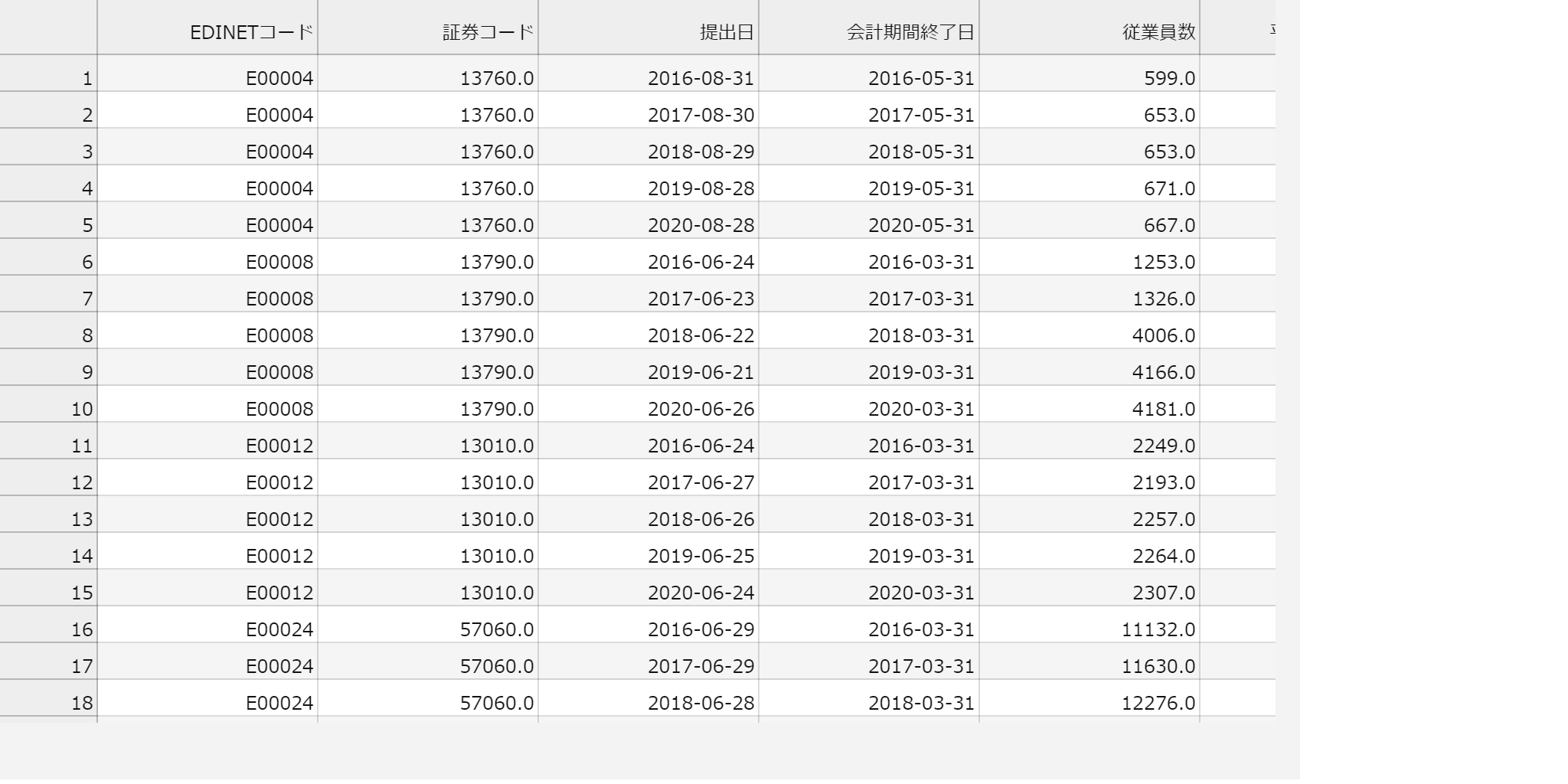
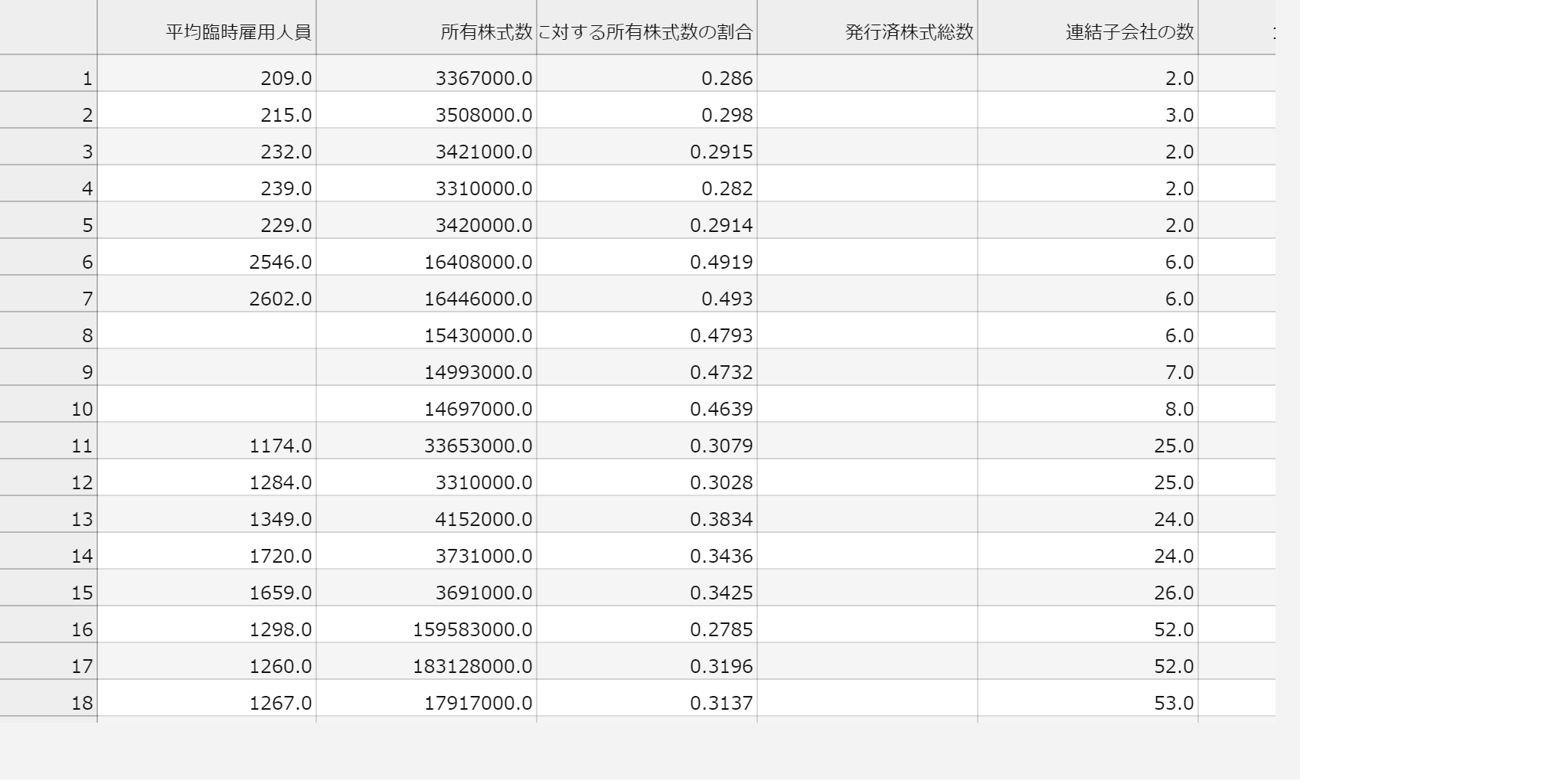
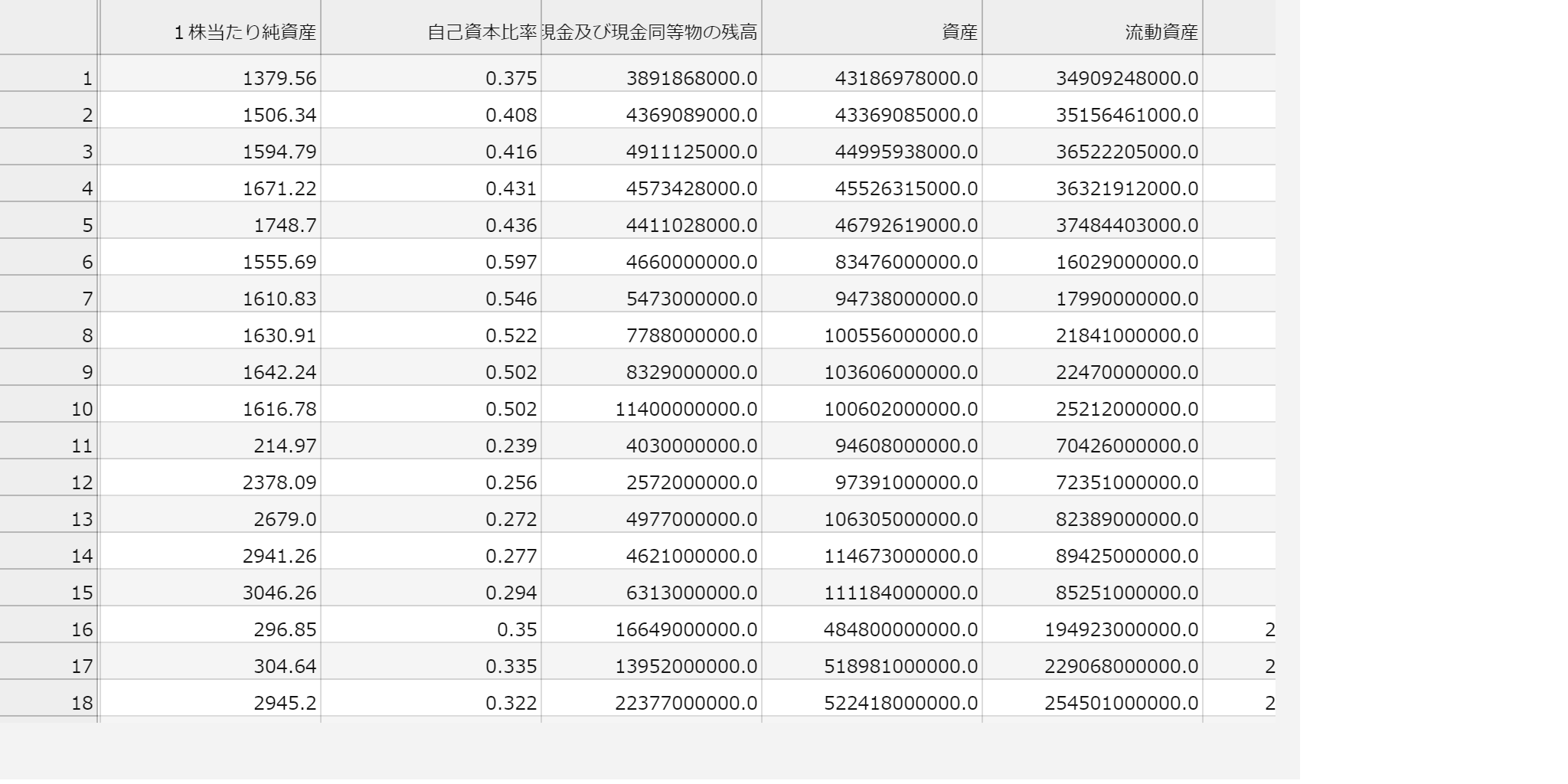
次はこれをもとに簡単な分析を行いたいと思います。では~

コメント