
今回はテキストデータから共起ネットワークをプロットします。そもそも共起ネットワークとは同時に出現する単語の組み合わせをエッジで繋ぎ、単語間の関係をネットワークで表したものです。これにより、文章内の単語の関連性を可視化できます。
<イメージ図>
共起ネットワークはPythonだと「networkx」というライブラリを使って簡単に実装することができます。
・実行環境
GoogleColab
Python3.7
networkx2.6.3
Contents
データの取得と加工
今回使用するデータは、青空文庫 Aozora Bunkoにある福沢諭吉の『学問のすすめ』です。すでにテキストファイル化したものはをGITからダウンロードしてgooglecolabの一番上のディレクトリにアップロードして配置してください。
ライブラリのインストール
!pip install mecab-python3 unidic-lite !apt install aptitude !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3==0.7 !apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1 !pip install mecab-python3 > /dev/null !ln -s /etc/mecabrc /usr/local/etc/mecabrc
日本語フォントのインストール
次にMatplotlibの日本語フォントをインストールしてデフォルトの文字フォントとして設定します。
!apt-get -y install fonts-ipafont-gothic import matplotlib.pyplot as plt plt.rcParams['font.family'] = 'IPAPGothic'
ライブラリの読み込み&不要な単語を削除
!pip install mojimoji
!pip install neologdn
import MeCab
from wordcloud import WordCloud
import re
import pandas as pd
import numpy as np
import matplotlib
from collections import defaultdict, Counter
from copy import copy, deepcopy
from pathlib import Path
import collections
import urllib.request
import MeCab
import mojimoji
import neologdn
import unicodedata
import itertools
import networkx as nx
%matplotlib inline
def get_stopword_lsit(write_file_path):
if not write_file_path.exists():
url = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
urllib.request.urlretrieve(url, write_file_path)
with open(write_file_path, 'r', encoding='utf-8') as file:
stopword_list = [word.replace('\n', '') for word in file.readlines()]
return stopword_list
def get_noun_words_from_sentence(sentence, mecab, stopword_list=[]):
return [
x.split('\t')[0] for x in mecab.parse(sentence).split('\n') if len(x.split('\t')) > 1 and \
'名詞' in x.split('\t')[3] and x.split('\t')[0] not in stopword_list
]
def split_sentence(sentence, mecab, stopword_list):
sentence = neologdn.normalize(sentence)
sentence = unicodedata.normalize("NFKC", sentence)
words = get_noun_words_from_sentence(
sentence=sentence, mecab=mecab, stopword_list=stopword_list
)
words = list(map(lambda x: re.sub(r'\d+\.*\d*', '0', x.lower()), words))
return words
with open('gakumonno_susume.txt', 'r', encoding='utf-8') as file:
lines = file.readlines()
sentences = []
for sentence in lines:
texts = sentence.split('。')
sentences.extend(texts)
mecab = MeCab.Tagger('-Ochasen')
stopword_list = get_stopword_lsit(Path('stopword_list.txt'))
# stopword_list=['ここ', 'あれ','ん','よう','0','こと','さん','の', 'ん','これ','もの','そう']
noun_sentences = []
for sentence in sentences:
noun_sentences.append(
split_sentence(sentence=sentence, mecab=mecab, stopword_list=stopword_list)
)
for words in noun_sentences[:5]:
print(words)
noun_sentences = list(filter(lambda x: len(x) > 1 and '見出し' not in x, noun_sentences))
combination_sentences = [list(itertools.combinations(words, 2)) for words in noun_sentences]
combination_sentences = [[tuple(sorted(combi)) for combi in combinations] for combinations in combination_sentences]
tmp = []
for combinations in combination_sentences:
tmp.extend(combinations)
combination_sentences = tmp
combination_sentences[:5]
def make_jaccard_coef_data(combination_sentences):
combi_count = collections.Counter(combination_sentences)
word_associates = []
for key, value in combi_count.items():
word_associates.append([key[0], key[1], value])
word_associates = pd.DataFrame(word_associates, columns=['word1', 'word2', 'intersection_count'])
words = []
for combi in combination_sentences:
words.extend(combi)
word_count = collections.Counter(words)
word_count = [[key, value] for key, value in word_count.items()]
word_count = pd.DataFrame(word_count, columns=['word', 'count'])
word_associates = pd.merge(
word_associates,
word_count.rename(columns={'word': 'word1'}),
on='word1', how='left'
).rename(columns={'count': 'count1'}).merge(
word_count.rename(columns={'word': 'word2'}),
on='word2', how='left'
).rename(columns={'count': 'count2'}).assign(
union_count=lambda x: x.count1 + x.count2 - x.intersection_count
).assign(jaccard_coef=lambda x: x.intersection_count / x.union_count).sort_values(
['jaccard_coef', 'intersection_count'], ascending=[False, False]
)
return word_associates
jaccard_coef_data = make_jaccard_coef_data(combination_sentences)
jaccard_coef_data.head(10)
共起ネットワーク用にデータを整形
group_values = [0, 0.01, 0.02, 0.04, float('inf')]
plot_data = jaccard_coef_data.copy()
plot_data['group_num'] = 0
group_names = []
for i in range(len(group_values) - 1):
plot_data['group_num'] = plot_data.apply(
lambda x: i + 1 if group_values[i] <= x['jaccard_coef'] and x['jaccard_coef'] < group_values[i + 1] else x['group_num'],
axis=1
)
group_names.append((group_values[i], group_values[i + 1]))
plot_data = plot_data.groupby('group_num')['jaccard_coef'].count().reset_index().rename(
columns={'jaccard_coef': 'n_combi'}
).assign(rate=lambda x: x.n_combi / x.n_combi.sum()).assign(
rate_cumsum=lambda x: x.rate.cumsum()
)
plot_data = pd.concat([
pd.DataFrame(group_names, columns=['jaccard_lower', 'jaccard_upper']),
plot_data
], axis=1)
plot_data
前処理についての詳しい解説は以下のサイトに記載されているのでチューニングの際などは参考にしてください
参照:https://www.dskomei.com/entry/2019/04/07/021028
NetworkXで共起ネットワークをプロットする
日本語の文字化けについて
データの前処理ができたので次は共起ネットワークをプロットします。
ネットの他の記事を見るとnx.draw_networkx_labels()の引数でフォントを指定すれば日本語の文字化けが解消されるとありましたがGoogleColab上だと日本語が文字化けしたままでした。なので、matplotlib.font_managerで’IPAPGothic’のttfファイルを直接指定します
サンプルコード
import matplotlib.font_manager
#日本語フォント読み込み
font_path = r'/usr/share/fonts/opentype/ipafont-gothic/ipag.ttf'
font_prop = matplotlib.font_manager.FontProperties(fname=font_path)
def plot_network(
data, edge_threshold=0., fig_size=(15, 15),
fontfamily='Osaka', fontsize=14,
coefficient_of_restitution=0.15,
image_file_path=None
):
nodes = list(set(data['node1'].tolist() + data['node2'].tolist()))
plt.figure(figsize=fig_size)
G = nx.Graph()
# 頂点の追加
G.add_nodes_from(nodes)
# 辺の追加
# edge_thresholdで枝の重みの下限を定めている
for i in range(len(data)):
row_data = data.iloc[i]
if row_data['weight'] >= edge_threshold:
G.add_edge(row_data['node1'], row_data['node2'], weight=row_data['weight'])
# 孤立したnodeを削除
isolated = [n for n in G.nodes if len([i for i in nx.all_neighbors(G, n)]) == 0]
for n in isolated:
G.remove_node(n)
# k = node間反発係数
pos = nx.spring_layout(G, k=coefficient_of_restitution)
pr = nx.pagerank(G)
# nodeの大きさ
nx.draw_networkx_nodes(
G, pos, node_color=list(pr.values()),
cmap=plt.cm.Reds,
alpha=0.7,
node_size=[60000*v for v in pr.values()]
)
# 日本語ラベル
datas = nx.draw_networkx_labels(G, pos, font_size=fontsize, font_family=fontfamily, font_weight="bold")
for t in datas.values():
t.set_fontproperties(font_prop)
# エッジの太さ調節
edge_width = [d["weight"] * 100 for (u, v, d) in G.edges(data=True)]
nx.draw_networkx_edges(G, pos, alpha=0.4, edge_color="darkgrey", width=edge_width)
plt.axis('off')
plt.tight_layout()
if image_file_path:
plt.savefig(image_file_path, dpi=300)
n_word_lower = 50
edge_threshold=0.025
plot_data = jaccard_coef_data.query(
'count1 >= {0} and count2 >= {0}'.format(n_word_lower)
).rename(
columns={'word1': 'node1', 'word2': 'node2', 'jaccard_coef': 'weight'}
)
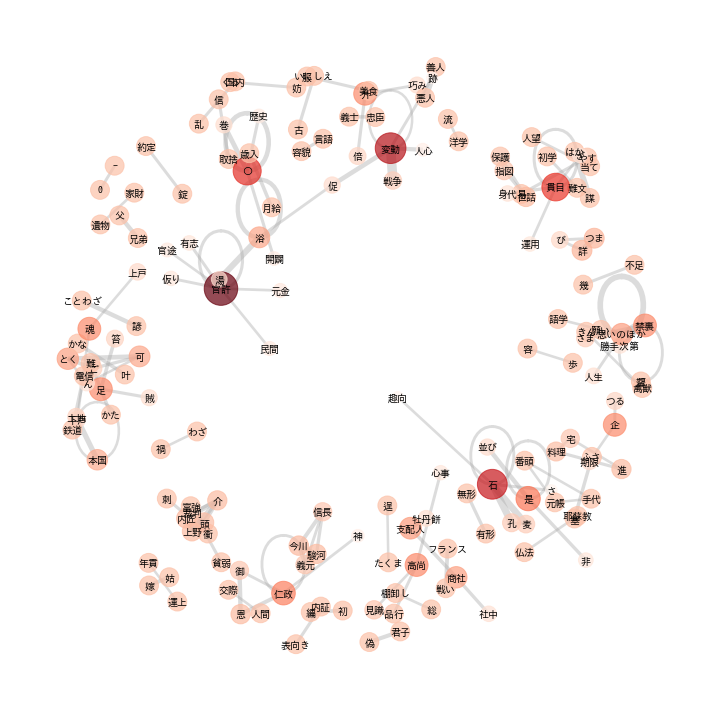
plot_network(
data=plot_data,
edge_threshold=edge_threshold,
fig_size=(10, 10),
fontsize=9,
fontfamily='Osaka',
coefficient_of_restitution=0.08,
image_file_path='/co_occurence_network.png'
)
<実行結果>
ノートブック:https://colab.research.google.com/drive/1eSXZuqO5WqcspxPe73MNSgjGwnG4jPe1?usp=sharing

参考:https://www.currypurin.com/entry/2018/03/25/015759
参考:https://propen.dream-target.jp/blog/networkx_sample
参考:https://www.dskomei.com/entry/2019/04/07/021028
コメント
[…] 関連記事:【Python】GoogleColab上でNetworkXによる日本語の共起ネットワークを文字化けせずにプロット […]
[…] 関連記事:【Python】GoogleColab上でNetworkXによる日本語の共起ネットワークを文字化けせずにプロット […]
[…] 関連記事:【Python】GoogleColab上でNetworkXによる日本語の共起ネットワークを文字化けせずにプロット […]