
今回は業務でツイッターAPIを用いてツイートデータを収集して「nlplot」というライブラリでワードクラウドや共起ネットワークの作成みたいな自然言語処理を少し試してみたので忘れないようにメモしておきます。
Contents
前準備
必要なライブラリのインストール
今回使用するライブラリは「nlplot」「Tweepy」「Mecab」の3つです
nlplot
# ライブラリのインストール $ pip install nlplot==1.6.0
バージョンでメソッドの書き方が変わっているのでバージョンを固定していますが、依存性が多いライブラリなので動かない場合は最新バージョンをインストールしたほうがいいと思います
詳しい話についてはライブラリの作成者さんのサイトを参考にしてください
Tweepy
$ pip install tweepy --upgrade
Mecab
インストールしていない方は以下のコマンドでインストールしてください
$ pip install mecab-python3
参照:Google ColaboratoryにMecabをインストールして形態素解析を行うサンプルコード
ツイートデータをスクレイピングする
まずは分析の元になるツイートデータをTwitterAPIを用いたスクレイピングにて取得します。
今回はTwitterAPI2.0を用いています。
API鍵の種類のあれこれとかツイートデータのスクレイピングについて下記記事参照
参照:【Python】TwitterAPI V2のBearer tokenを使ってツイート検索をしてみる
ちなみにですが、無料のAPI鍵だと過去10日間しか遡れない&検索数に上限があるので、全期間や過去30日間のツイートについては有料APIが必要になります。
参照:【Python】TwitterのAPIを使って過去全期間のツイートをスクレイピング
import tweepy
from datetime import datetime
from datetime import timedelta
import json
import requests
import traceback
import os
import pandas as pd
print(f'tweepyのバージョンは{tweepy.__version__}です')
consumer_key = 'xxxx'
consumer_secret = 'xxxx'
access_token = 'xxxx'
access_token_secret = 'xxxx'
#APIインスタンスの作成
client = tweepy.Client(bearer)
api = tweepy.Client(None, consumer_key, consumer_secret, access_token, access_token_secret)
# ツイート取得
data = []
for tweet in tweepy.Paginator(client.search_recent_tweets, query='ワンピース 映画 lang:ja -is:retweet',
expansions='author_id',max_results=100).flatten(limit=500):
data.append(tweet.data['text'])
df=pd.DataFrame(data, columns=['data'])
df
<実行結果>
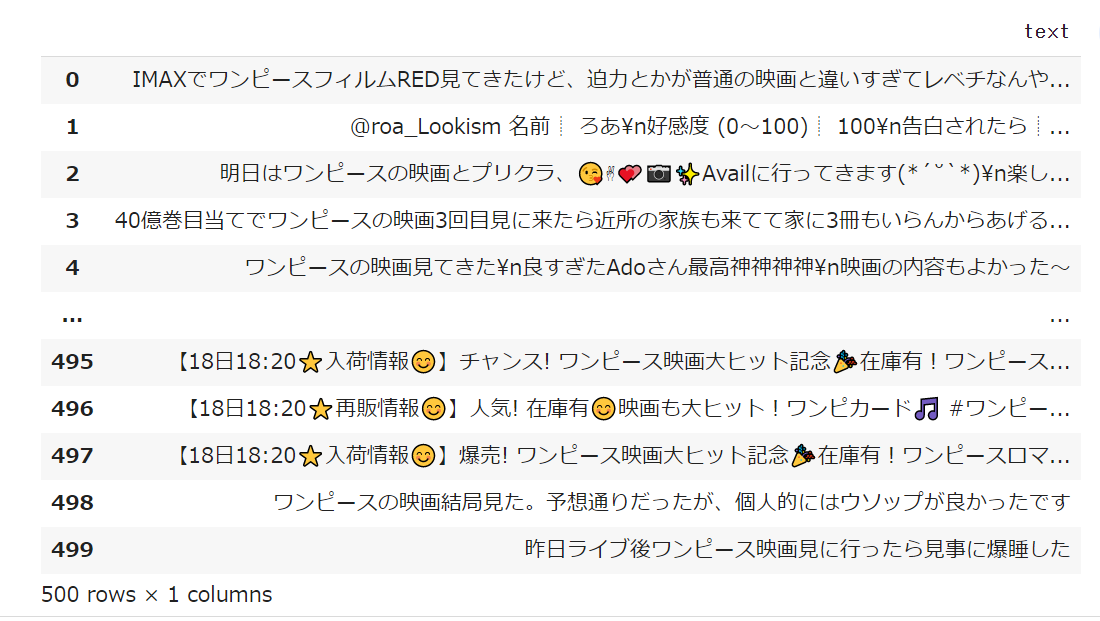
Pythonでの自然言語処理
Mecabで形態素解析して名詞を取り出す
まずは取得したテキストデータをMecabで形態素解析します。本記事はColabでMecabの環境構築が完了している前提で進めていますが、もし環境構築難しい場合はGoogle Natural Language APIなどで代用可能です。
def mecab_text(text):
ng_word = ['https', '/','t', 'co','://','.','#',':','こと','さん','ちゃん']
#MeCabのインスタンスを作成(辞書はmecab-ipadic-neologdを使用)
mecab = MeCab.Tagger('')
#形態素解析
node = mecab.parseToNode(text)
#形態素解析した結果を格納するリスト
wordlist = []
while node:
#名詞のみリストに格納する
if node.feature.split(',')[0] == '名詞':
try:
if node.surface not in ng_word:
try:
int(node.surface)
except:
if len(node.surface) > 1:
wordlist.append(node.surface)
except:
wordlist = []
#他の品詞を取得したければ、elifで追加する
#elif node.feature.split(',')[0] == '形容詞':
# wordlist.append(node.surface)
node = node.next
return wordlist
#形態素結果をリスト化し、データフレームdf1に結果を列追加する
df['words'] = df['text'].apply(mecab_text)
#表示
df
<実行結果>
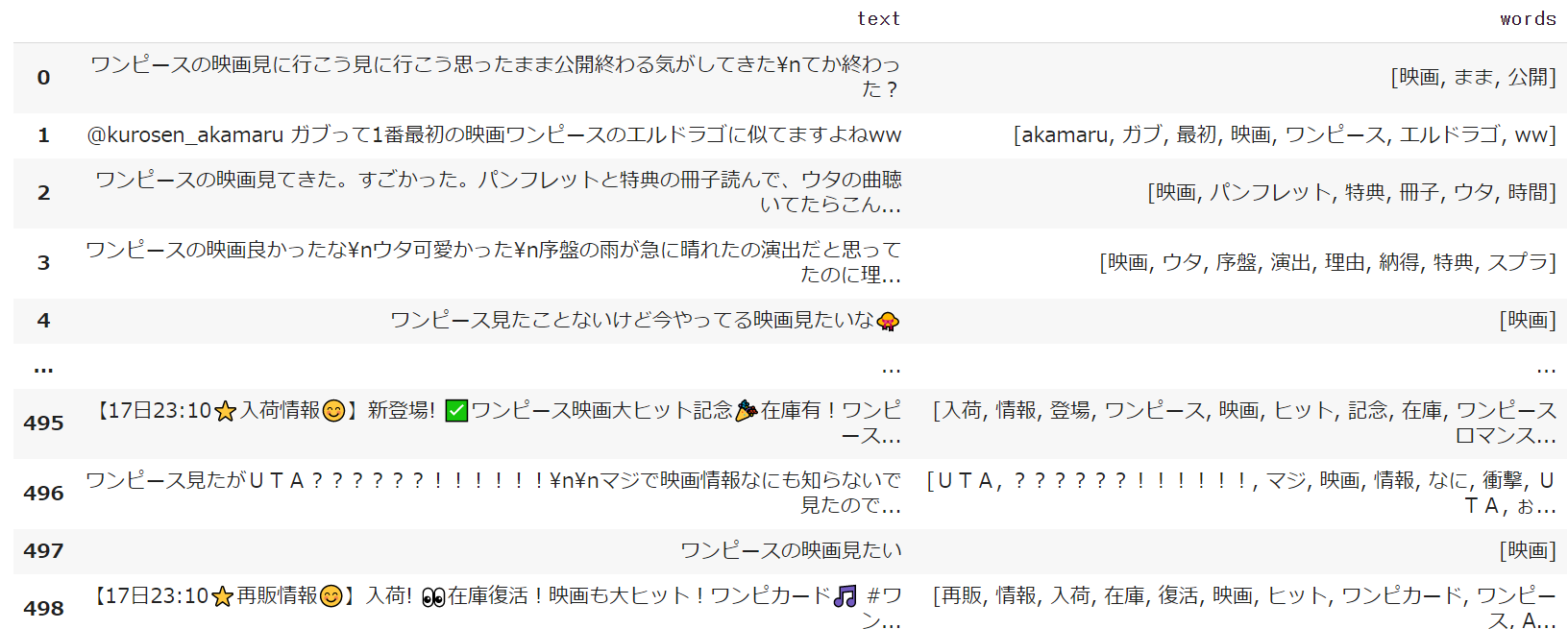
実行するとデータフレームに新たにwordsという列が作成され、そこに形態素解析したものの中で名詞と判定されたものがリストで格納されます。これでデータが前処理ができたのでいよいよこのツイートデータを自然言語処理で可視化していきます。
頻出単語の可視化
まずは頻繁に出てきたワードを可視化します。
import nlplot
npt = nlplot.NLPlot(df, target_col='words')
# top_nで頻出上位単語, min_freqで頻出下位単語を指定できる
# ストップワーズは設定しませんでした。。。
stopwords = npt.get_stopword(top_n=0, min_freq=0)
npt.bar_ngram(
title='uni-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=1,
top_n=50,
stopwords=stopwords,
)
<実行結果>
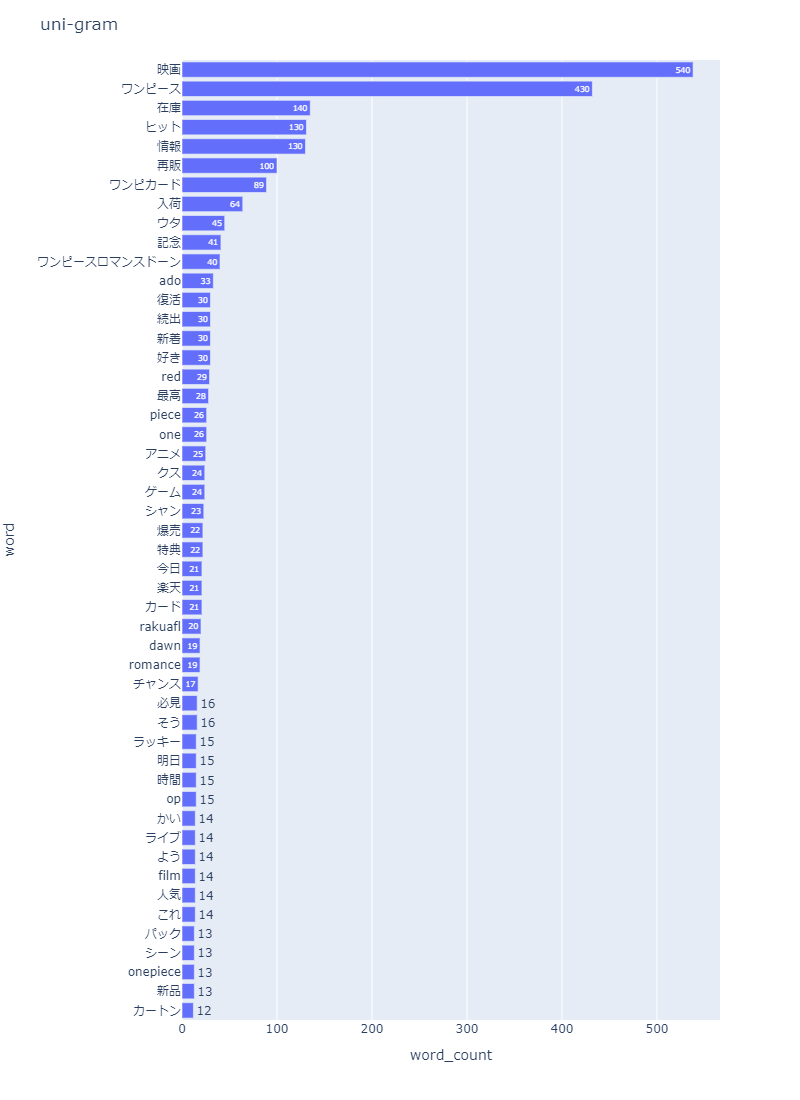
ツリーマップで見せたい場合は以下のように記述します
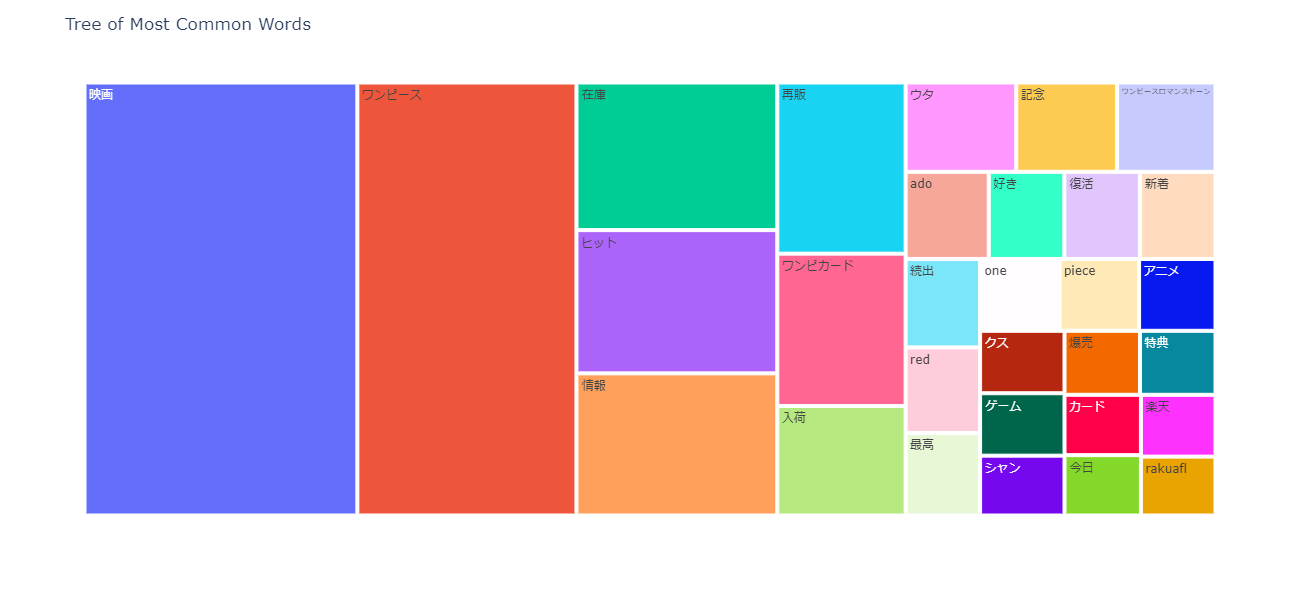
npt.treemap(
title='Tree of Most Common Words',
ngram=1,
top_n=30,
stopwords=stopwords,
)
<実行結果>
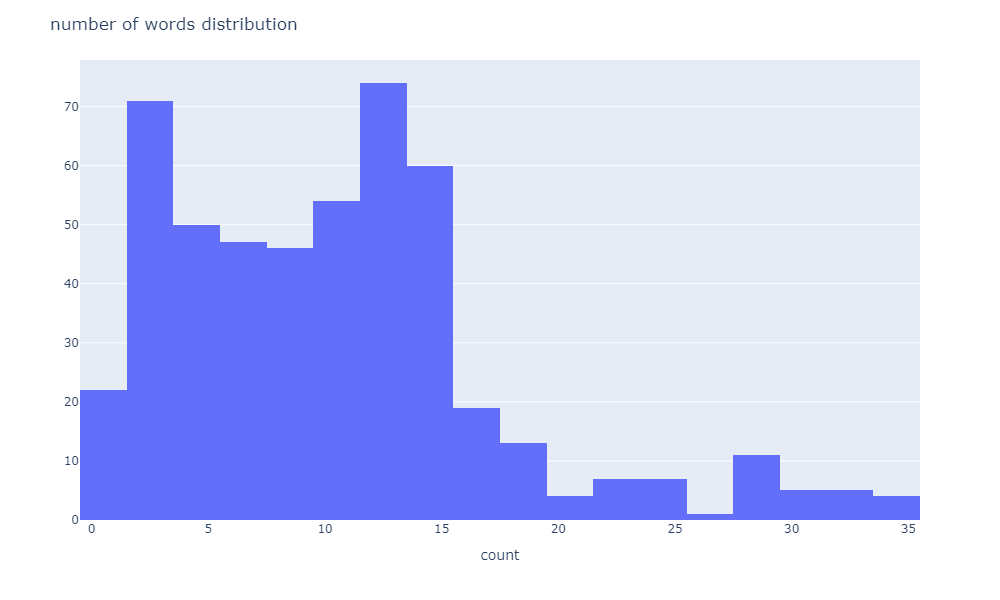
単語数の分布を確認したい場合は以下のように記述します。
# 単語数の分布
npt.word_distribution(
title='number of words distribution',
xaxis_label='count',
)
<実行結果>
ワードクラウドの作成
# ワードクラウドを出力する
npt.wordcloud(
max_words=100,
max_font_size=100,
colormap='tab20_r',
stopwords=stopwords,
)
これでグラフが表示されない場合は以下のコマンドを追加してみてください
%matplotlib inline
plt.figure(figsize=(10, 15))
plt.imshow(fig_wc, interpolation="bilinear")
plt.axis("off")
plt.show()
<実行結果>

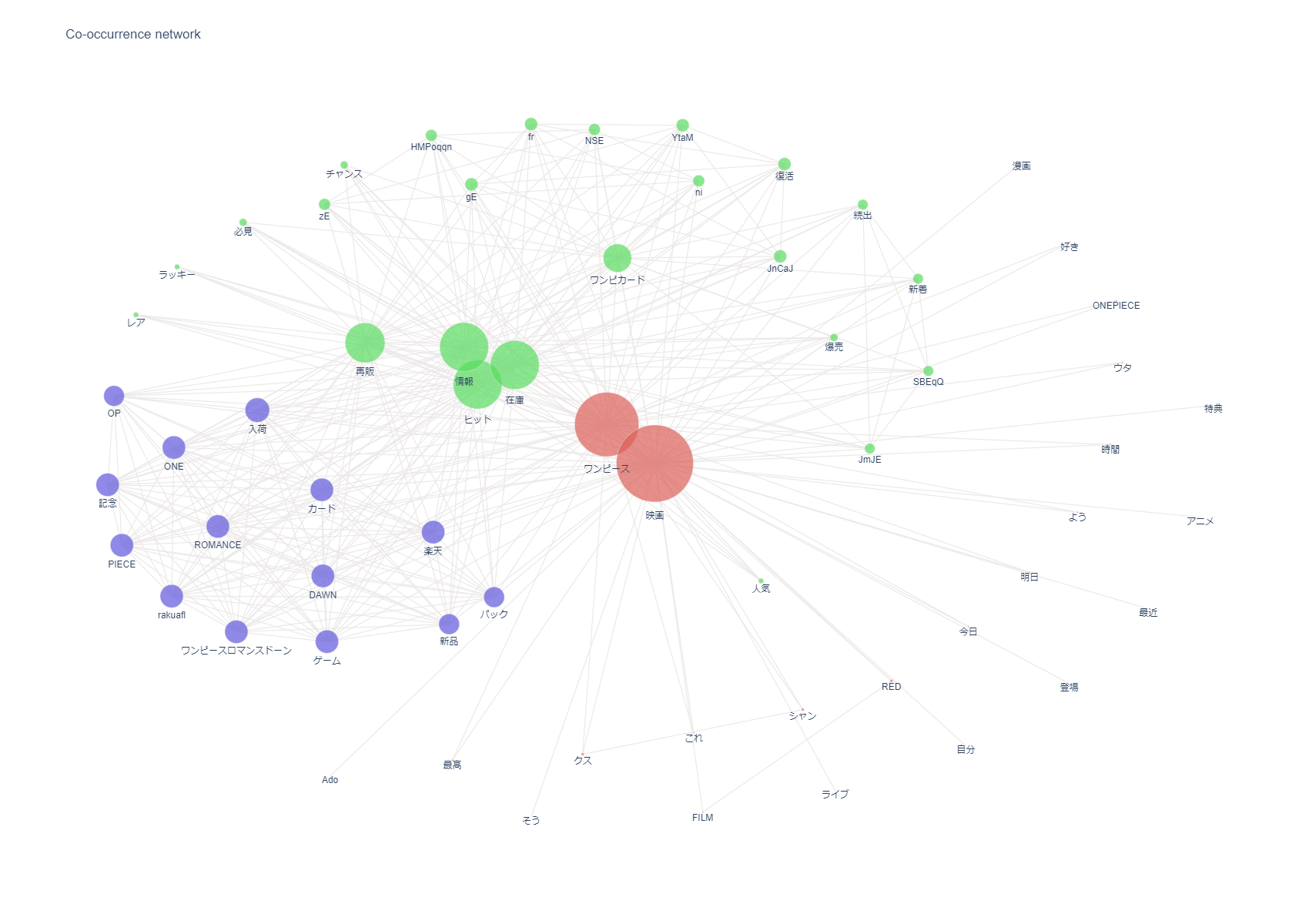
共起ネットワークの作成
#共起ネットワーク図作成
# ビルド(データ件数によっては処理に時間を要します)※ノードの数のみ変更
npt.build_graph(stopwords=stopwords, min_edge_frequency=10)
display(
npt.node_df.head(), npt.node_df.shape,
npt.edge_df.head(), npt.edge_df.shape
)
npt.co_network(
title='Co-occurrence network',
)
上記でグラフが出力されない場合は以下を試してみてください
#共起ネットワーク図作成 #iplotをインポートして使えば結果が表示される from plotly.offline import iplot # ビルド(データ件数によっては処理に時間を要します) npt.build_graph(stopwords=stopwords, min_edge_frequency=2) # ビルド後にノードとエッジの数が表示される。ノードの数が100前後になるようにするとネットワークが綺麗に描画できる #>> node_size:63, edge_size:63 fig_co_network = npt.co_network( title='Co-occurrence network', sizing=100, node_size='adjacency_frequency', color_palette='hls', width=1100, height=700, save=False ) iplot(fig_co_network)
<実行結果>
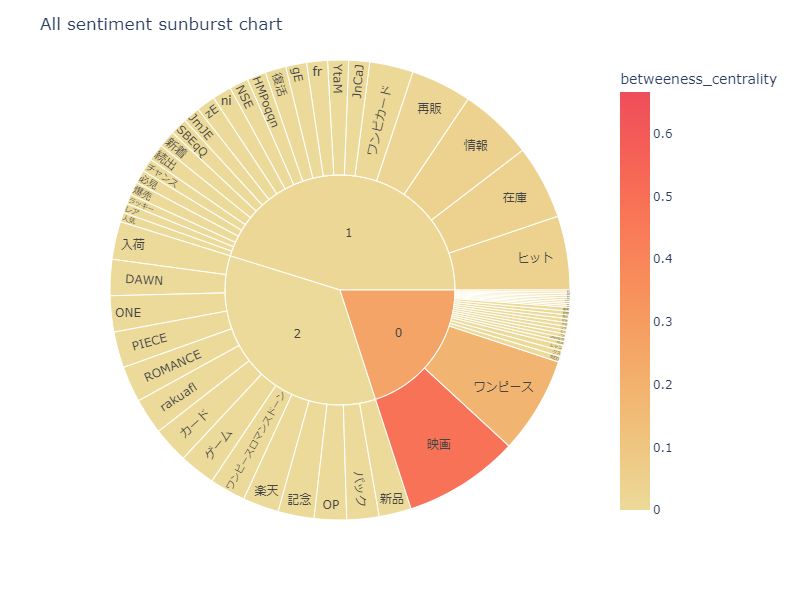
感情度の可視化
npt.sunburst(
title='All sentiment sunburst chart',
colorscale=True,
color_continuous_scale='Oryel',
width=800,
height=600,
save=True
)
<実行結果>
終わり
こんな感じで「nlplot」を使うことで関数1つで様々なグラフのプロットが可能なので非常に便利です。
関連記事:【Python】PymlaskでML-ASK感情分析をやってみた話
関連記事:【Python】GoogleColab上でNetworkXによる日本語の共起ネットワークを文字化けせずにプロット
コメント
[…] 関連記事:自然言語処理が簡単にできる「nlplot」でツイートデータを可視化・分析する […]
[…] 関連記事:自然言語処理が簡単にできる「nlplot」でツイートデータを可視化・分析する […]