機械学習を実際にPythonで実行する方法

前回は機械学習の分析における大まかな手順について解説しました。というわけで今回は実際にプログラミング言語「Python」を使用して、ビットコインの価格データを機械学習していきます。
前回説明したように機械学習には「教師あり学習」と「教師なし学習」の2種類がありますが、手っ取り早くパフォーマンスが出せるのは教師あり学習です。教師あり学習とは、入出力のペア(ラベル付きデータ)から学習を行う手法です。教師あり学習は基本的に「回帰」と「分類」です。
pythonでの機械学習なら「Scikit-learn」
機械学習の計算理論をプログラミング言語に置き換えるのは手間が掛かりますが、pythonには「scikit-learn」という機械学習ライブラリが用意されていており、この「scikit-learn」を使用すると機械学習がpythonで超簡単に行えます。
「scikit-learn」はAnacondaにデフォルトでインストールされているので、Anaconda環境の人は特にインストールなどを行う必要はありません。
次は実際にpython・scikit-learnを使って、機械学習を実際に始めていきたいと思います。
機械学習に使うデータの取得と前処理
というわけで今回はビットコインの価格データを使って機械学習を行っていきます。ビットコインの価格データに関しては以下の記事で解説していますので、仕様についてはそちらを読んでいただけると幸いです。

そして上でも説明したように、機械学習に必要なものは教師データと正解データの2つです。教師データというのは回帰分析におけるx説明変数で、正解データはy(被説明変数)にあたるものです。なので、機械学習を始めるにあたっては、まずは何を「x」にして何を「y」にするのかを決めてそれにあたるデータを用意する必要があります。
今回は結果を出すのが目的ではなくデモンストレーションなので、とりあえずx(説明変数)はn日のビットコインの変化率として、y(被説明変数)はn+1日のビットコインの変化率ということにします。
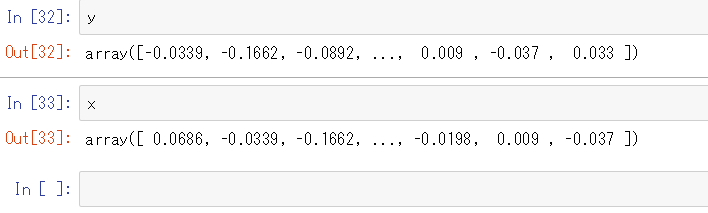
#教師データと正解データを作る x=price.pct_change().dropna().round(4).iloc[:-1].values y=price.pct_change().dropna().round(4).iloc[1:].values
コードの中身の説明をざっとしておくと、まず.pct_change()で価格データから変化率を計算します。次に.dropna()で欠損値のNanを除外します。そして、round(4)でデータの数値を小数点第4位に整うように四捨五入します。
round()は()の中に任意の引数の数字で四捨五入してくれる関数でデータの整形で非常に使うことが多いです。今回は引数を4にしたので、小数点第5位を四捨五入して第4位までの数値になるようにデータを整えています。
次の.ilocはPandasのデータフレームから任意の要素を取得できる関数です。xの方にある[:-1]というのは最後の1つの数値以外を抽出するという処理になり、yの[1:]は2番目から最後までの数値を抽出するという処理になっています。(pythonは0から始まるので[1:]で2番目のデータを指定していることになります)
これでxとyのデータを1日分スライドさせることができたか一応中身を確認しておきましょう。xの1つ目のデータに対応しているyの1つ目の要素が、xの2つ目の要素(0.0339)と同じ数値になっており、スライドできているのが分かります。
教師データ(x)と正解データ(y)を作ったら、次はこの2つのデータをそれぞれ訓練データとテストデータの2つに分割します。分割の割合はケースバイケースなので一概にどうとは言えませんが、まずはとりあえず7:3くらいで切っておけばいいでしょう。
そして訓練データを計算して作ったモデルをテストデータと照らし合わせて、誤差を計算し、その誤差が最小になるモデルを作るというのが機械学習の流れです。
#xとyをそれぞれ訓練データとテストデータの2つに分割する from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
今回はテストデータを全体に3割にしたので、test_size=0.3としています。訓練データとテストデータの比率を変える場合はここを0~1の範囲で変更してください。
こんな感じで、x_train,x_test,y_train,y_testと4つのデータができました。データはxとyの2つで、さらにそれを訓練データとテストデータの2つにそれぞれ分割するので、機械学習にあたって用意するデータは2×2の実質4種類となります。
これで形上データができたわけですが、このままモデルに入力(fit)させようとするとエラーになります。
#データを整形する Xtrain = np.reshape(x_train, (-1,1)) Xtest = np.reshape(x_test, (-1,1)) Xtrain2 = np.array(Xtrain,dtype=int) Xtest2 = np.array(Xtest,dtype=int) y_train2 = np.array(y_train,dtype=int) y_test2 = np.array(y_test,dtype=int)
for文で回してもよかったのですが、見やすくするために一応書き出して見ました。そしてモデルをfitさせるときによく出てくるエラーは
「Unknown label type: ‘continuous’」と「Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.」の2つですね。
1つ目の「Unknown label type: ‘continuous’」というエラーはロジティクス回帰のモデルで良く起きるエラーです。というのもロジティクス回帰の関数は小数点以下の数値であるfloatに対応しておらず、0.001みたいな小数点以下の数値の入った訓練データを突っ込むとエラーになります。
なので、dtype=intとしてデータをint型と定義しておきます。これをfloatのデータで実行すると00000…みたいなデータになるので、データの形を変えるしかありません。
2つ目の「Reshape…」は要は入力データの形が合ってないから整形しなおせというエラーです。このエラーは機械学習をするあたって親の顔より見るエラーといっても過言ではありません。ホント機械学習・ディープラーニングのデータの前処理でややこしいのはこの入力次元の処理ですね。ここさえ乗り切れば後は簡単です。頑張りましょう!
同じライブラリに入っている関数でもアルゴリズムごとに求められるデータの形(imput.shape)が違うので、アルゴリズムごとにnp.reshape()やnp.flatten()でデータの形を整形することが機械学習やディープラーニングでは多々あります。
そしてここのnp.reshape(x_train, (-1,1))では一次元のnumpyの数値データを1列1452行(※執筆日の要素数)の多次元配列に変換しています。np.reshape()は引数で指定した通りにデータの構造を多次元配列に変形しますが、行と列の片方の引数を-1とすると自動でもう片方の要素に合わせた数に設定してくれます。
今回は列の要素を1としているので、行を-1とすることでコンピューター側が自動的に引数を1452÷1=1452と設定してくれているわけです。もしここで(-1,2)と指定した場合は2列756行の多次元配列に変換されますね。
こんな感じでこの訓練データとテストデータの2つはpython上で元のデータを変形させて作ります。データ分析を始め、今回の機械学習やディープラーニングに使うデータを作成する前処理にnumpyとPandasが非常に役に立つので、pythonで機械学習を行うにあたってはこの2のライブラリは非常に使い勝手が良いので実際にどんどん使って慣れていきましょう。
numpyの仕様に関しては内部でCが動いていたり奥が深いので自分もまだまだ勉強中ではあるのですが、いろいろ読んだ中でも「現場で使える! NumPyデータ処理入門 機械学習・データサイエンスで役立つ高速処理手法」という参考書が細かく分かりやすくまとめてくれていたので、numpyについてちゃんと知りたい人にはオススメです。

機械学習でデータを分析する
機会学習に使うデータが準備できたので、ここからは機械学習を実際に行っていきます。実は機械学習やディープラーニングは実行自体は数行で終わるので、やるだけならホント簡単にできます。むしろ前処理が一番難しいです。
まあコードの意味を理解したり精度を上げるためにパラメーターを変更したり、新しい手法を開発するとなると、それなりに数学知識が必要なので、そこが機械学習エンジニアになるうえでのハードルですね。
そして機械学習アルゴリズムにはSVC(サポートベクトルマシーン)を始め、決定木などの機械学習アルゴリズムがあり、実務においては分析するデータの性質によってこういったアルゴリズムを使い分けていきます。
今回は教師あり学習の中でも「ロジスティック回帰」「ランダムフォレスト」「k-近傍法」という3つ機械学習アルゴリズムを試してみます。
from sklearn.metrics import accuracy_score
lr=LogisticRegression()
rfc=RandomForestClassifier()
nb=neighbors.KNeighborsClassifier()
for clf, name in [(lr,'Logsitic'),(rfc,'Random Forest'),(nb,'k-Neighbors')]:
#データを学習させる
clf.fit(Xtrain2, y_train2)
#生成したモデルによる予測値を計算
y_pred= clf.predict(Xtest2)
#実際の値と予測値の比率
scores=[]
for i in range(int(len(y_test2))):
if y_test2[i]>0 and y_pred[i]>0:
scores.append(y_test2[i])
elif y_test2[i]<0 and y_pred[i]<0:
scores.append(y_test2[i])
accuracy=len(scores)/len(y_pred)*100
print(name,'test; ',clf.score(Xtrain2, y_train2),'正解率',accuracy)
これで機械学習のアルゴリズムを3つ実行しました。for文はリストの中身を一つずつ代入して実行する仕様になっており、今回はclfとnameという2つの変数に[(lr,’Logsitic’),(rfc,’Random Forest’),(nb,’k-Neighbors’)]という3つのリストを1つずつ代入して実行するという処理を3回繰り返しています。

ごちゃごちゃ数字が出てきていると思いますが、これはモデルの評価のためのパラメーターです。
Logsitic test; 0.004132231404958678 正解率 43.659711075441415 Random Forest test; 0.8395316804407713 正解率 48.796147672552166 k-Neighbors test; 0.19834710743801653 正解率 44.301765650080256
さてモデルを計算したはいいものの、計算して作ったモデルが良いモノかどうかを決める方法な必要になってくる訳ですが、機械学習では正解率(accuracy)の他にも交差検証など、いくつか評価指標が存在するので、それらを総合的に見てモデルを評価します。
まあ今回の結果は上がるか下がるかの予測にも関わらず50%以下の正解率とお話にならない結果だった訳ですが、パフォーマンスが悪かった原因としては、説明変数:n日の価格と被説明変数:n+1日の価格には特に関係性はなかったというのが大きいでしょうね。
終わり
以上がpython・scikit-learnを使用した機械学習の簡単なやり方です。今回はふるわない結果でしたが、他のデータであればそこそこの効果が出るので機械学習・ディープラーニングは近年注目され始めています。
独学で機械学習を勉強するのであれば「Pythonで動かして学ぶ! あたらしい機械学習の教科書」が非常に分かりやすかったので手始めの一冊としてはオススメです。

ビックデータだのIoTだのという言葉が当たり前になってきた昨今において、pythonを触れるエンジニアの中でも特に統計学・機械学習が分かるエンジニアの市場価値は年々高まっていっているので、特に勉強したいものがないという人はこういった分野の勉強をしておくと仕事には困らないと思われます。
機械学習・ディープラーニングは独学で勉強するのもちろん可能ですが、1回ハマると自力で抜け出せずそのままあぼーんということも少なくありません。自分も最初独学で勉強し始めたもののディープラーニングの下りがさっぱりわからず詰んだ経験があります。
ですが最近は「侍エンジニア」や「PyQ」など、機械学習・ディープラーニングをわかりやすく教えてくれるプログラミングスクールも増えているので、お金をに余裕がある人は、そういったところに通うと効率良く学べると思います。


コメント
[…] ミナピピンの研究室【Python】機械学習ライブラリ「Scikit-learn」を使ってビットコインの価格予測を…https://tkstock.site/2019/01/04/post-1348/ 機械学習を実際にPythonで実行する方法 &nbs […]
[…] ミナピピンの研究室【Python】機械学習ライブラリ「Scikit-learn」を使ってビットコインの価格予測を…https://tkstock.site/2019/01/04/post-1348/ 機械学習を実際にPythonで実行する方法 &nbs […]