
Contents
Seleniumでのブラウザを自動操作する方法
PythonでGoogleクロームやIE・Firefoxなどのウェブブラウザは「Selenium」というライブラリを使って自動操作することができます。
ということで今日は「Selenium」のインストール方法と使い方、Seleniumで起動したブラウザでの検索ボックスに文字入力→クリックする方法などを分かりやすく解説していきたいと思います。
Seleniumの使い方
まずはコマンドラインからpipでSeleniumをインストールします。
#seleniumをインストールする pip install -U selenium
ライブラリをダウンロードしたら次はウェブドライバー(Webdriver)をダウンロードします。以下のURLにアクセスし、pythonのところ(https://pypi.org/project/selenium/)をクリックしてください。→https://pypi.org/project/selenium/
するとブラウザに合わせた、バージョンが選択できるので、クロームなりFirefoxなりを選択し、次はOSに対応したものを選択します。私はWindows10なので、Win32.zipをダウンロードしました。
ブラウザは基本自分の好きなものを選べばいいと思いますが、Seleniumを使って文字入力を行う場合、サイトのソースが一番見やすいのはGoogleChromeなので、個人的にはクロームが一番推奨です。
今のchromeのバージョンが分からないという人は以下のサイトにアクセスすると現在のブラウザのchromeのバージョンが確認できます。
What version of Chrome do I have? – WhatIsMyBrowser.com
そして、ダウンロードしたらzipファイルを解凍して展開し、中にあるexeファイルを起動します。コマンドプロンプトみたいな黒い画面が表示されて、そこのメッセージの中にon port 9515という記述があればOKです。
ちなみにChromeDriverをPythonでのみ利用するなら、「pip install chromedriver-binary」 でインストールできます。
次はコマンドプロンプトからSeleniumを実行します。「Jupyter Notebook」とかから起動するとパスの問題でエラーになることがあるので、アナコンダプロンプトや「spyder」から起動するのが無難です。「$python」でpythonを起動します。起動したら以下のコードを実行します。
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
drv=webdriver.Remote("http://127.0.0.1:9515", DesiredCapabilities.CHROME)
これで以下のようなブラウザが起動すれば成功です。
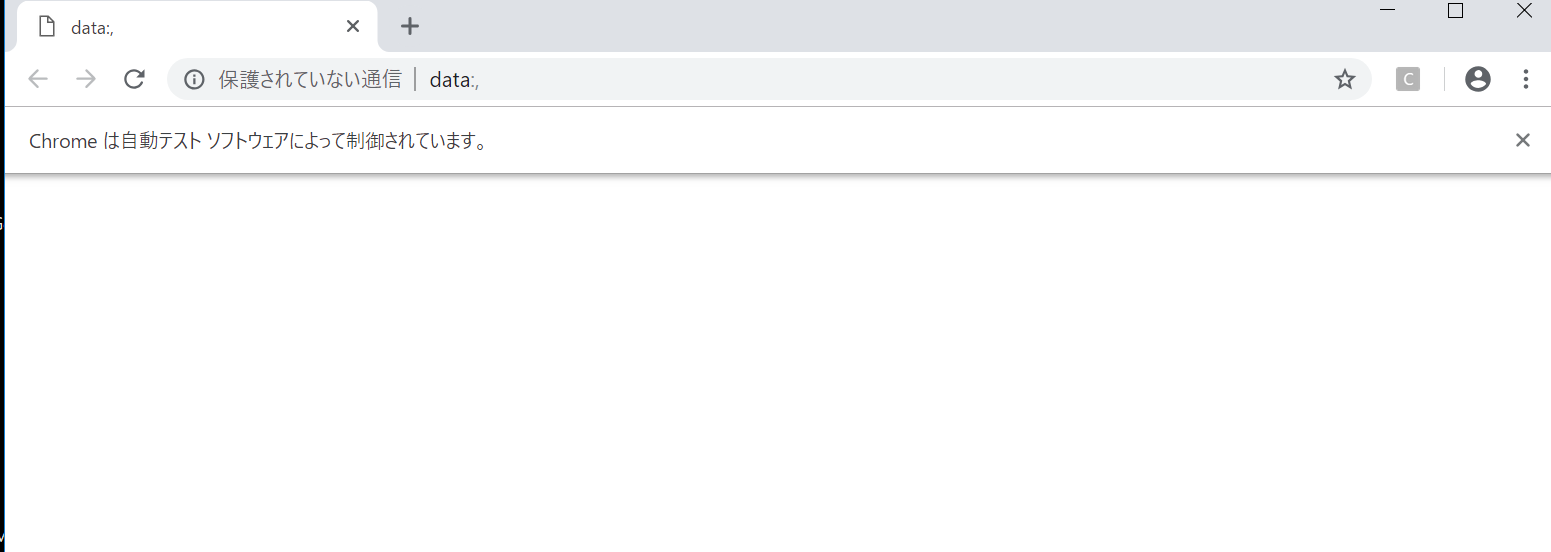
MaxRetryError: HTTPConnectionPool(host='127.0.0.1', port=9515):
Max retries exceeded with url: /session (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x0000017EFE1BE198>:
Failed to establish a new connection: [WinError 10061] 対象のコンピューターによって拒否されたため、接続できませんでした。',))
この時上記のようなエラーが起きた場合は下のコードで代用してみてください。
# ライブラリのインポート from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities # ドライバーのインスタンスを定義する drv = webdriver.Chrome(executable_path="ここにchromedriver.exeのPATHを入力")
chromedriver.exeのPATHはSeleniumを実行するpyファイルと同じディレクトリに存在している場合はそのままexecutable_path=chromedriver.exeで行けますが、他のディレクトリのある場合はそのPATHを指定してあげる必要があります。
ファイルのパスはWindowsなら、ファイルエクスプローラーで「shift」を押しながら右クリックで「パスをコピー」という項目ができるので、それで確認できます。(パスの\を\\にする必要があります。)
Seleniumを操作するサンプルコード
これでPythonからのSeleniumの実行環境を準備は整ったので、次は実際にSeleniumでブラウザを操作していきたいと思います。
# Amazonにアクセスする
drv.get("http://www.amazon.co.jp")
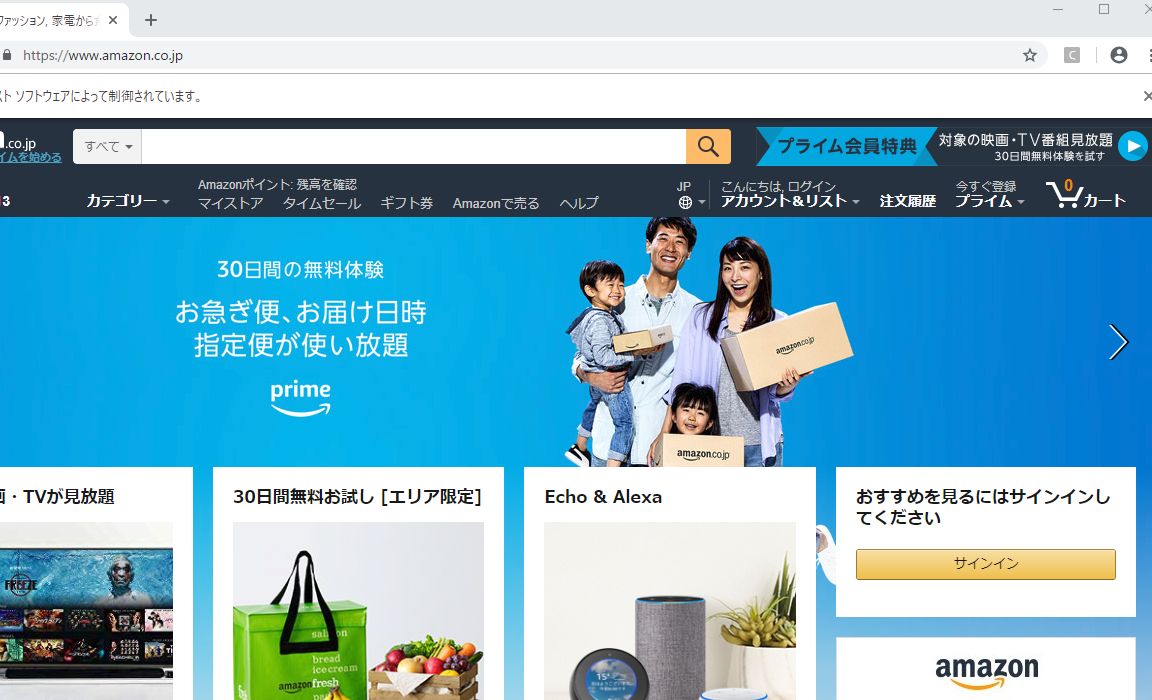
これでページにアクセスできました。ただこれだけだとSNSとかのログインに必要なユーザーネーム(またはメールアドレス)とパスワードをブラウザ上で入力してログインしたり、Amazonで検索ボックスにキーワードを入力して商品を検索、みたいなことはできません。
Seleniumで以上のような「サイトのボックスに文字を入力してクリックしてページを移動するなどといった操作」を行うためには、サイトのhtmlのソースコードを検証し、目当てのボックスにkeyを送信するという操作を行う必要があります。
クリックや文字入力などのアクションを起こすHTMLの要素に指定するには id、class、name 等から指定する事ができますが、個人的にはXpathで指定したほうがエラーが起こる可能性が低いと思うのでオススメです。
単純なサイトならidなどで要素を指定できるのですが、TwitterやAmazonのようなややこしいソースのサイトはxpathでやっています。
XPathとは何か?
XPath(XML Path Language)とは、XML形式の文書から特定の部分を指定して抽出するための簡潔な構文(言語)です。HTML形式の文書にも対応しています。
CSSではセレクタを使ってHTML文書内の特定の部分を抽出しますが、XPathはより簡潔かつ柔軟に指定ができるので、「Selenium」などでブラウザの自動操作ではエラーが起こりにくいです。
Seleniumの引数に使うXPath(要素)の調べ方
XPathの調べ方は表示されているページのhtmlを見て調べるのが手っ取り早いです。例えば先ほどアクセスしたAmazonのサイトの上記の検索ボックスに検索したい文字を入力するとします。
まずGoogleクロームの場合であれば、右クリックの検証というところをクリックするとページのソースを確認できます。そして文字を入力したい検索ボックスの要素を調べるには検索ボックスにマウスのカーソルを合わせて右クリックでもう一度検証をします。
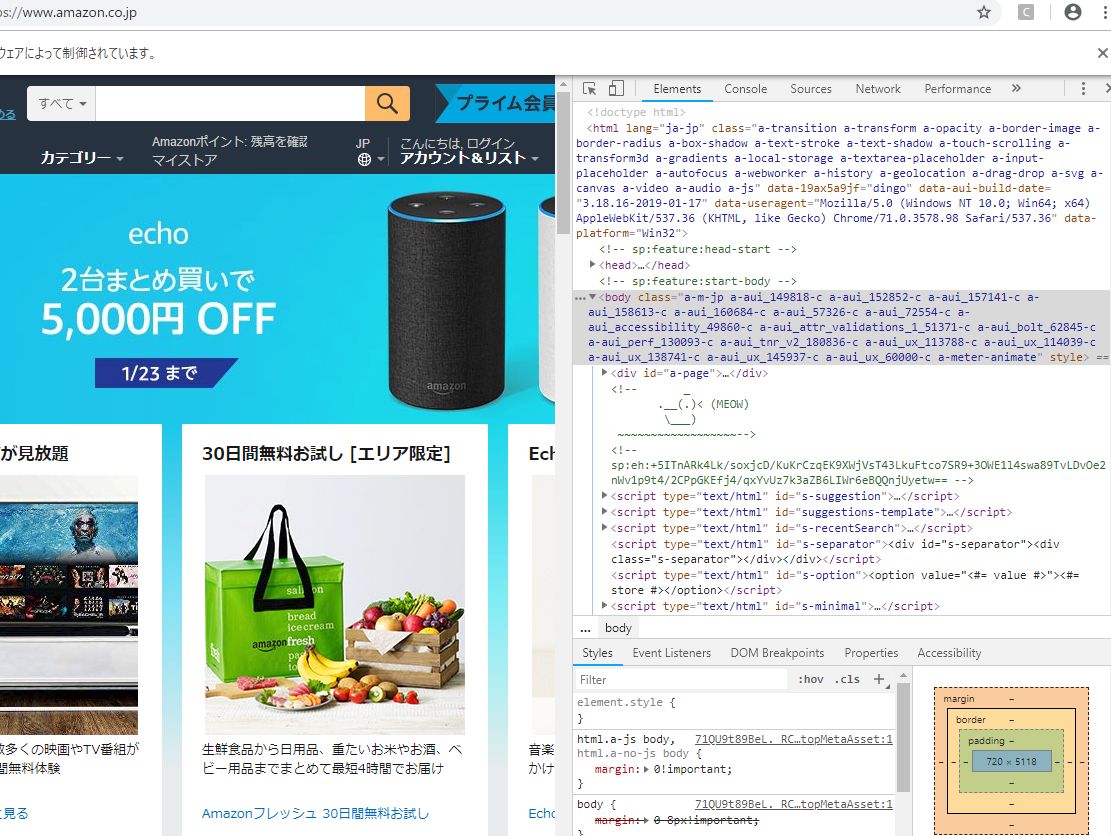
すると、対応するソースがドラッグされて表示されます。ブラウザで文字が入力をするボックスは基本的に<input>タグなので、<input>で囲まれたタグがドラックされていればそれが目当ての要素で間違いないでしょう。
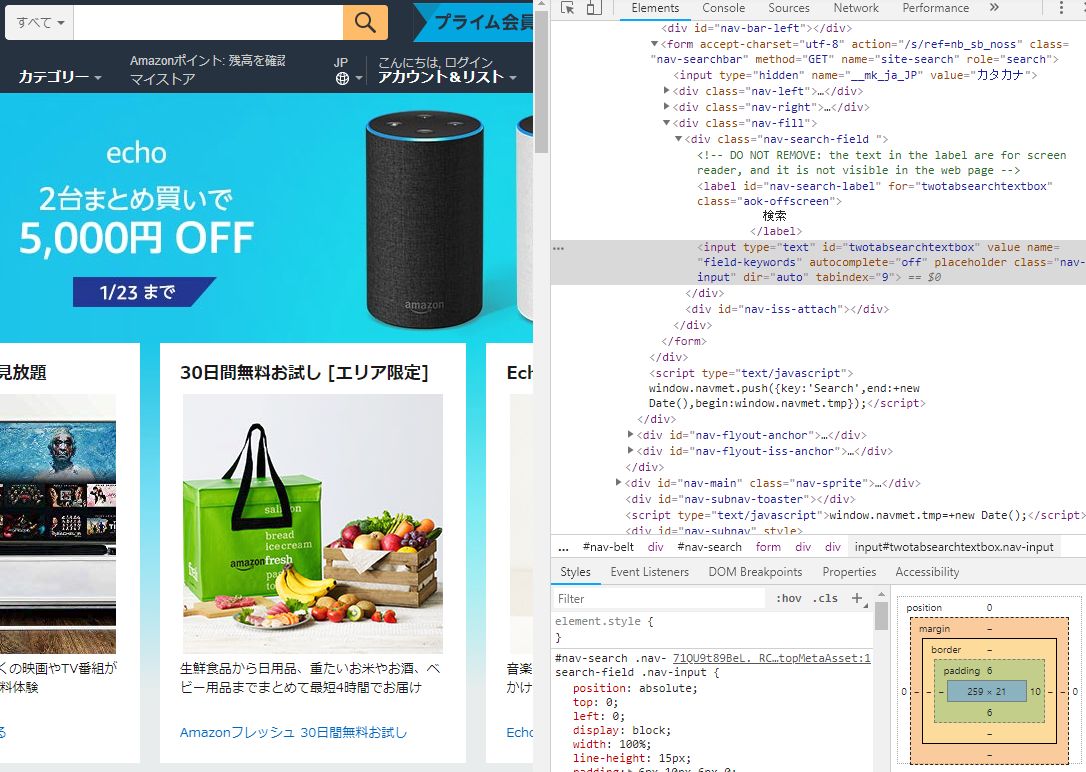
今回欲しい目当ての要素はXPathなので、ドラッグされた部分を右クリックして「コピー→XPathをコピー」するとクリップボードに目当ての文字入力ボックスのXPathがコピーされているので、それを引数に設定します。
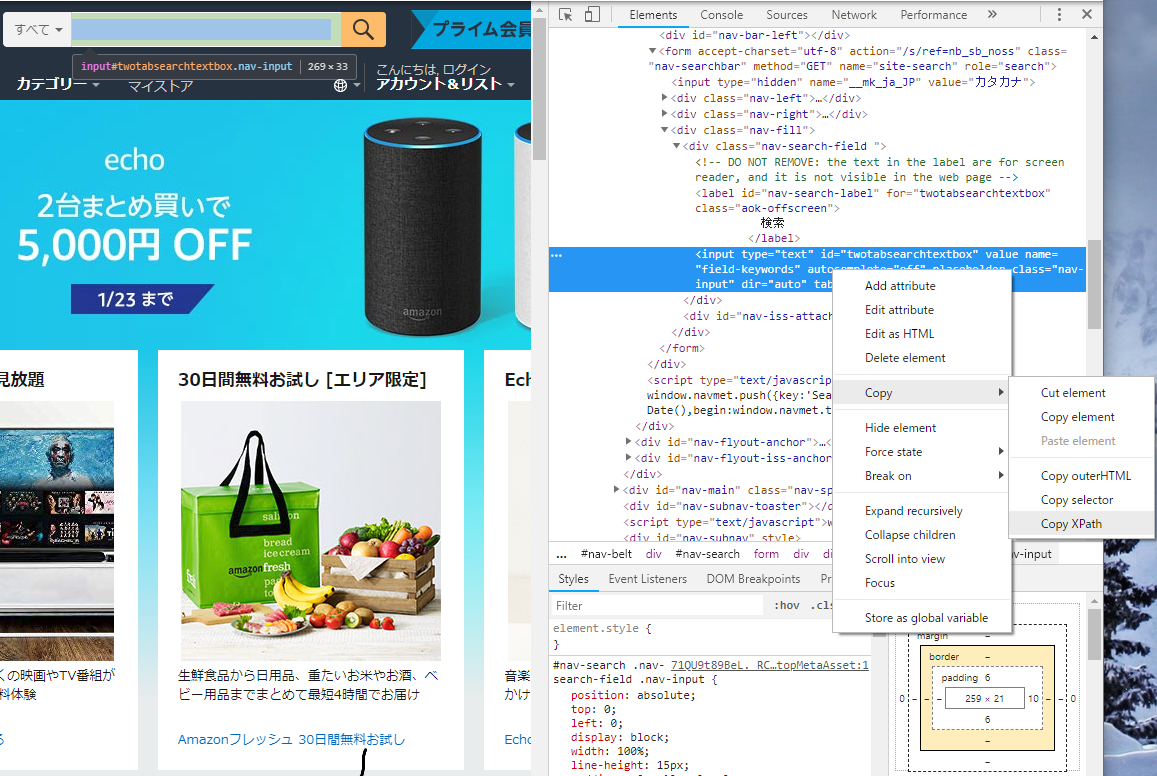
今回のAmazonの検索ボックスの要素のXPathは「//*[@id=”twotabsearchtextbox”]」だと分かりました。というわけで、Amazonでサイト上部の検索ボックスに文字を入力して検索したい場合は以下のように記述します。今回は「python Selenium」と入力して商品を検索してみます。
# Amazonで検索したいキーワードを検索ボックスに入力する
word = drv.find_element_by_xpath("//*[@id=\"twotabsearchtextbox\"]")
word.send_keys("python selenium")
次は「drv.find_element_by_xpath()」の引数に文字を入力したいボックスのXpathを指定し、「.send_keys()」の引数にブラウザに入力したい文字を入力します。
クリックボタンのXPathは先ほどと同じ要領で、ページを右クリックでHTMLを検証した状態でクリックのボタンをさらに右クリックで検証して、ドラッグされたソースのHTMLの部分をさらに右クリックで「コピー→XPathをコピー」で取得することができます。コードで書く際はXPathの指定と入力する文字を一緒くたにするとコードが長くなるので、変数で2行に分けたほうが見やすいでしょう。
# 要素を指定してクリックする
path = drv.find_element_by_xpath("//*[@id=\"nav-search\"]/form/div[2]/div/input")
path.click()
実行するとブラウザで表示しているAmazonの検索ボックスに「python Selenium」と入力されて横のクリックボタンがクリックされ、検索結果が表示されます。
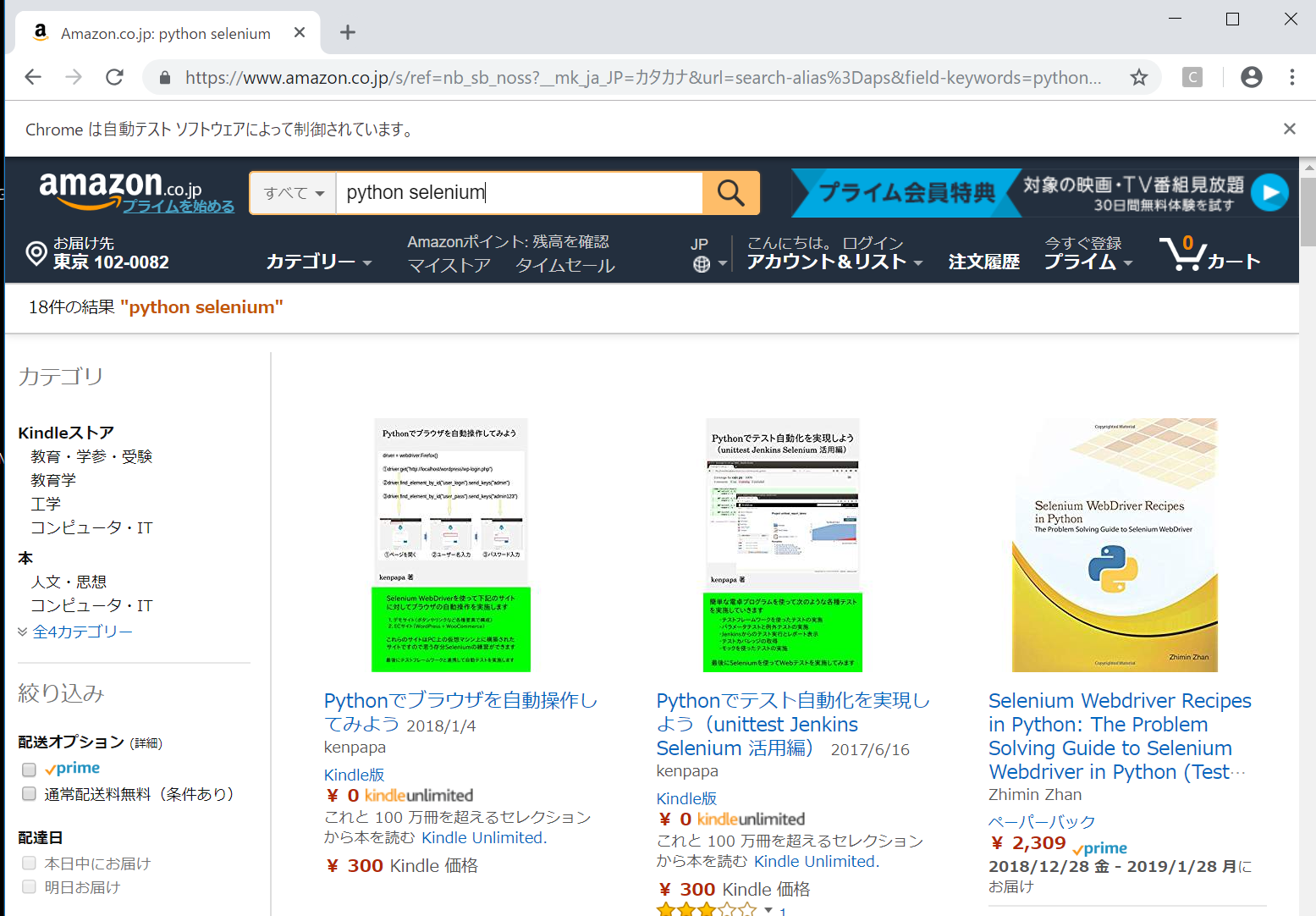
そして、Seleniumで開いたWebブラウザを閉じる際は以下のコード実行します。
# Webページを閉じる driver.close() # Webドライバーを終了する driver.quit()
終わり
以上がSeleniumの基本的な使い方です。文字を入力したい場合、ターゲットとなる文字を入力するボックスはclassよりもxpathで指定したほうがcssとかの影響を受けないので、動作が安定するかもしれません。
にしてもPythonは「requests」といい「Selenium」といいWebスクレイピングを便利にしてくれるライブラリがたくさんあるので、データ集めにはもってこいのプログラミング言語だと思いますね。
あと一応スクレイピングでは、著作権の問題や、サーバー側の負荷、各種規約(会員としてログインする場合の会員規約等)やマナーなどを考慮する必要があります。
たとえば、Twitter などは利用規約で明示的にスクレイピングが禁止されていますし、APIが用意されている場合はAPIを使ってスクレイピングしたほうがいいです。
自分はこのサイト以外にもサーバーも運営していたりで、スクレイピングされる側・する側両方の気持ちもわかりますが、あくまでスクレイピングはサイトのサーバーに負担を掛けないように節度と良識を持って行うようにしましょう。
関連記事:【2021年版】Python+Seleniumでツイッターに自動でログインしてツイートする
関連記事:【Python】SeleniumでTor経由でIPを切り替えつつスクレイピングする



コメント
[…] 関連記事:「Selenium」でブラウザを自動操作してWebサイトをスクレイピングする […]