
R言語でのスクレイピングなら「Rvest」
【R言語】rvestパッケージによるウェブスクレイピング その1
【R言語】rvestパッケージによるウェブスクレイピング その2
install.packages("rvest") install.packages("RMeCab", repos = "http://rmecab.jp/R") install.packages("wordcloud")
複数のURLをまとめてスクレイピングする方法
for文で複数のURLの情報をまとめて一気にスクレイピングしたい場合は大まかに2通りの方法があります。
①「URLの一部を「i」に変えてfor文を実行する」
②「リンク集をリストにしてそれでfor文を実行する」
まずは1つ目はページの番号の数字ををfor文の回す数字に当てはめる方法があります。例えばR-tipsのサイトの中身を一括取得したい場合は、以下のようにfor文を組むと可能になります。
#スクレイピングしたデータを格納するための空のリストを作る。
rtips<- list()
#1~74までのスクレイピングしたhtmlデータをtipsに格納していく
> for (i in 1:74){
+ if(i<10){
+ url<-paste(start,0,i,end,sep = "")
+ tips <- read_html(url,'Shift_JISX0213')
+ rtips<-append(rtips, list(tips))
+}
+ else{
+ url<-paste(start,i,end,sep = "")
+ tips <- read_html(url,'Shift_JISX0213')
+ rtips<-append(rtips, list(tips))
+}
+}
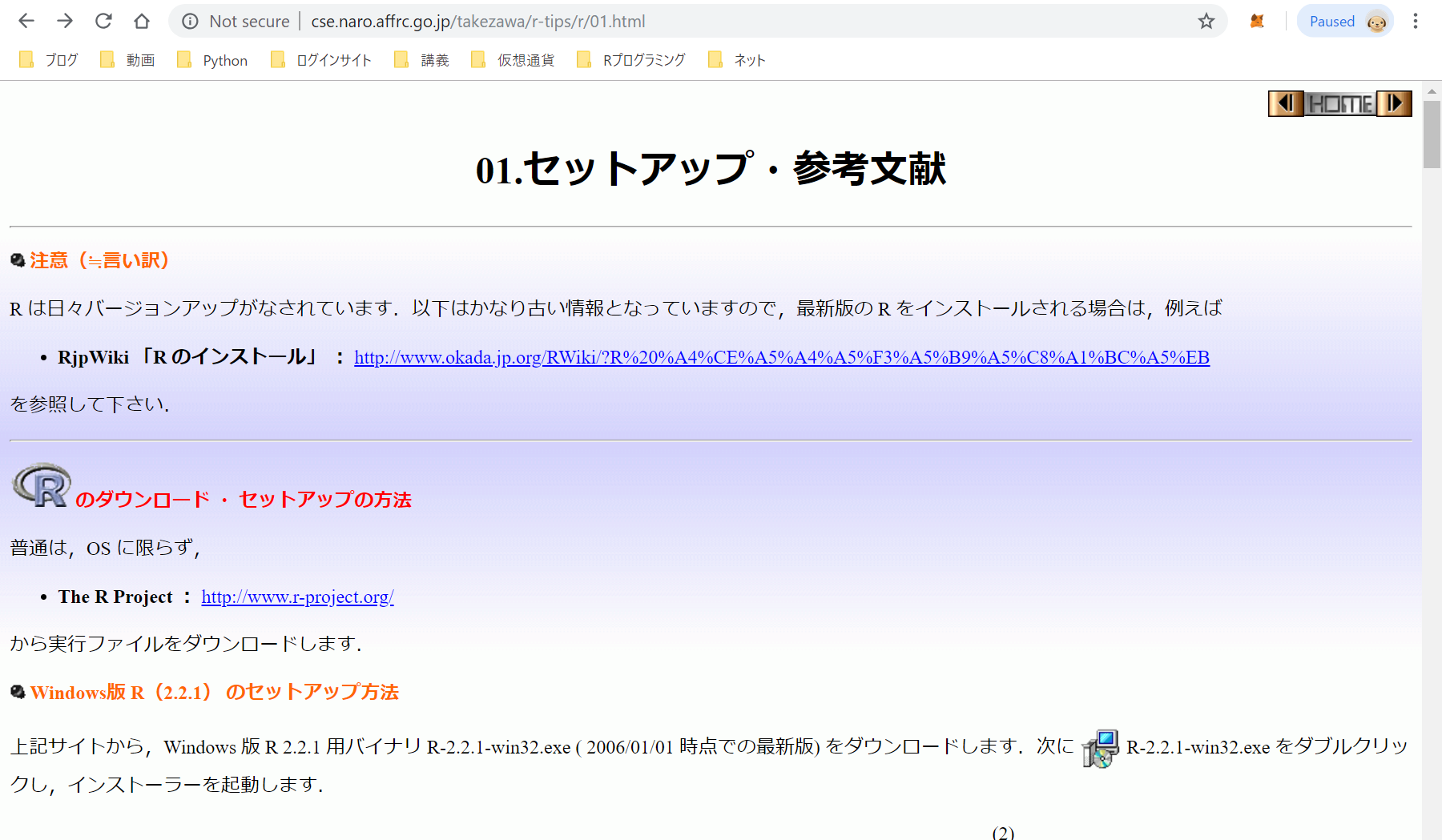
これはR-tipsのURLの仕様を把握すると書けるようになります。まずは対象となるページと、したいことが何であるかを確認しておきましょう。rtipsのURLの構成は第1節が「http://cse.naro.affrc.go.jp/takezawa/r-tips/r/01.html」となっており、最後の第74節が「http://cse.naro.affrc.go.jp/takezawa/r-tips/r/74.html」となっています。
異なっている部分は/r/~.htmlの部分なので、ここの01の部分を変数「i」にして01から74までを順番に代入していて繰り返す処理を行うfor文を作ればいいという考えになります。
まず「http://cse.naro.affrc.go.jp/takezawa/r-tips/r/01.html」だけをスクレピングするのであれば、以下のようなコードになります。
rtips <- read_html(“http://cse.naro.affrc.go.jp/takezawa/r-tips/r/01.html”,encoding = ‘Shift_JISX0213’)
これを繰り返し処理で1ページずつスクレイピングしていくような処理にするのであれば、欲しいのは01~74までのhtmlのソースなので最初の部分は「for (i in 01:74)」とします。
次にURLの書き方ですが、R-tipsの「/r/~.html」の部分を01~74まで変更しつつ同じ処理を繰り返し行いたいので01の部分を変数「i」とします。そして「i」を代入する部分以外のURLは同じなので、コードを短くするため変数に格納して省略します。
#URLの一部の文字列を変数に文字型データとして格納する start<-"http://cse.naro.affrc.go.jp/takezawa/r-tips/r/" end<-".html"
ちなみにRでの文字列の結合は「paste()」という関数で行うことができます。試しにi=1として、以下のコードを実行してみます。
i=1 #文字列を結合する paste(start,i,end) ※実行結果 [1] "http://cse.naro.affrc.go.jp/takezawa/r-tips/r/ 0 .html"
このままだと結合部分に空白のスペースが入ってしまっているので、read.html()でURLに指定したときに505エラーが行ってしまいます。なので、引数にsep=”を入れてスペースが入らないようにします。
> paste(start,i,end,sep='') [1] "http://cse.naro.affrc.go.jp/takezawa/r-tips/r/1.html"
これでread.htmlに入力するurlの作成に成功しました。あとは「for (i in 01:74)」とすることで変数「i」に1~74までの数字が繰り返し代入されて、
“http://cse.naro.affrc.go.jp/takezawa/r-tips/r/1.html”
“http://cse.naro.affrc.go.jp/takezawa/r-tips/r/2.html”
“http://cse.naro.affrc.go.jp/takezawa/r-tips/r/3.html”
…
“http://cse.naro.affrc.go.jp/takezawa/r-tips/r/74.html”
というurlに「read.html()」が実行されます。ですが、ここで問題なのが、for文で繰り返し回す際の「i」が1,2,3,4・・・74と代入していくのに対して、R-tipsのURLはサイトに行って確認してみると01,02,03・・・74となっており、「read.html()」のスクレイピングするURLを指定する際に最初の1~9ページ目のURLが一致しません。
この時の対処法としては、「i」が1~9までの間はpaste()でurlを作る際に、0を挟むようにして10~74の間は0をpasteに加えないという風に処理します。なので「i」が0~9の場合と10~74までの場合では処理が違うので、if文を使って条件分岐という場合分けを行う必要があります。これをコードで表現すると以下のように表すことができます。
#iが10未満はURLに0をはさむ
if(i<10){url<-paste(start,0,i,end,sep = "")}
#iが10以上の場合はURLに0を挟まない
else{url<-paste(start,i,end,sep = "")}
これを組み込むと以下のような文になります。
> for (i in 01:74){
+ if(i<10){
+ url<-paste(start,0,i,end,sep = "")
+ rtips <- read_html(url,'Shift_JISX0213')}
+ if(i>9){
+ url<-paste(start,i,end,sep = "")
+ rtips <- read_html(url,'Shift_JISX0213')}}
これで”http://cse.naro.affrc.go.jp/takezawa/r-tips/r/01.html”から”http://cse.naro.affrc.go.jp/takezawa/r-tips/r/74.html”まで繰り返し「read.html()」を実行して、R-tipsのサイトの情報をまとめてスクレイピングしてくれます。
ただこのままだとR-tipに格納されたスクレイピングしたHTMLデータがどんどん上書きされていってしまうので、こういう場合は先に空のリストを作ってそこに取得したデータを追加していくという形にしていくのが一般的です。
#スクレイピングしたデータを格納するための空のリストを作る。
rtips<- list()
#1~74までのスクレイピングしたhtmlデータをtipsに格納していく
> for (i in 1:74){
+ if(i<10){
+ url<-paste(start,0,i,end,sep = "")
+ tips <- read_html(url,'Shift_JISX0213')
+ rtips<-append(rtips, list(tips))
+}
+ else{
+ url<-paste(start,i,end,sep = "")
+ tips <- read_html(url,'Shift_JISX0213')
+ rtips<-append(rtips, list(tips))
+}
+}
Rでの空のリストの定義は「list()」で行うことができます。そして、tipsで格納したスクレイピングしたhtmlデータをr-tipsという空のリストの中に、リストに要素を追加する「append()」関数を使って取得したHTMLデータをドンドン追加していっています。
for文の処理の結果を保存して、別の処理に使いたい場合は、先に実行結果を保存する空のリストを作っておいて、そこに格納していくという基本的な手法です。一応rtipsの中身を確認してみると以下のような感じになっています。
>rtips
[[1]]
{xml_document}
<html>
[1] <head>\n<title>セットアップ</title>\n<meta http-equiv="Content-Type" content="text/h ...
[2] <body text="#000000" link="#0000FF" vlink="#0000FF" alink="#0000FF" background ...
[[73]]
{xml_document}
<html>
[1] <head>\n<title>R-Source</title>\n<meta http-equiv="Content-Type" content="text ...
[2] <body text="#000000" link="#0000FF" vlink="#0000FF" alink="#0000FF" background ...
[[74]]
{xml_document}
<html>
[1] <head>\n<title>R-Source</title>\n<meta http-equiv="Content-Type" content="text ...
[2] <body text="#000000" link="#0000FF" vlink="#0000FF" alink="#0000FF" background ...
yahoo!ショッピングの検索結果をスクレイピングで一括取得する
次にYahoo!ショッピングのスクレイピングを行ってみます。試しに「R言語」と検索してみます。
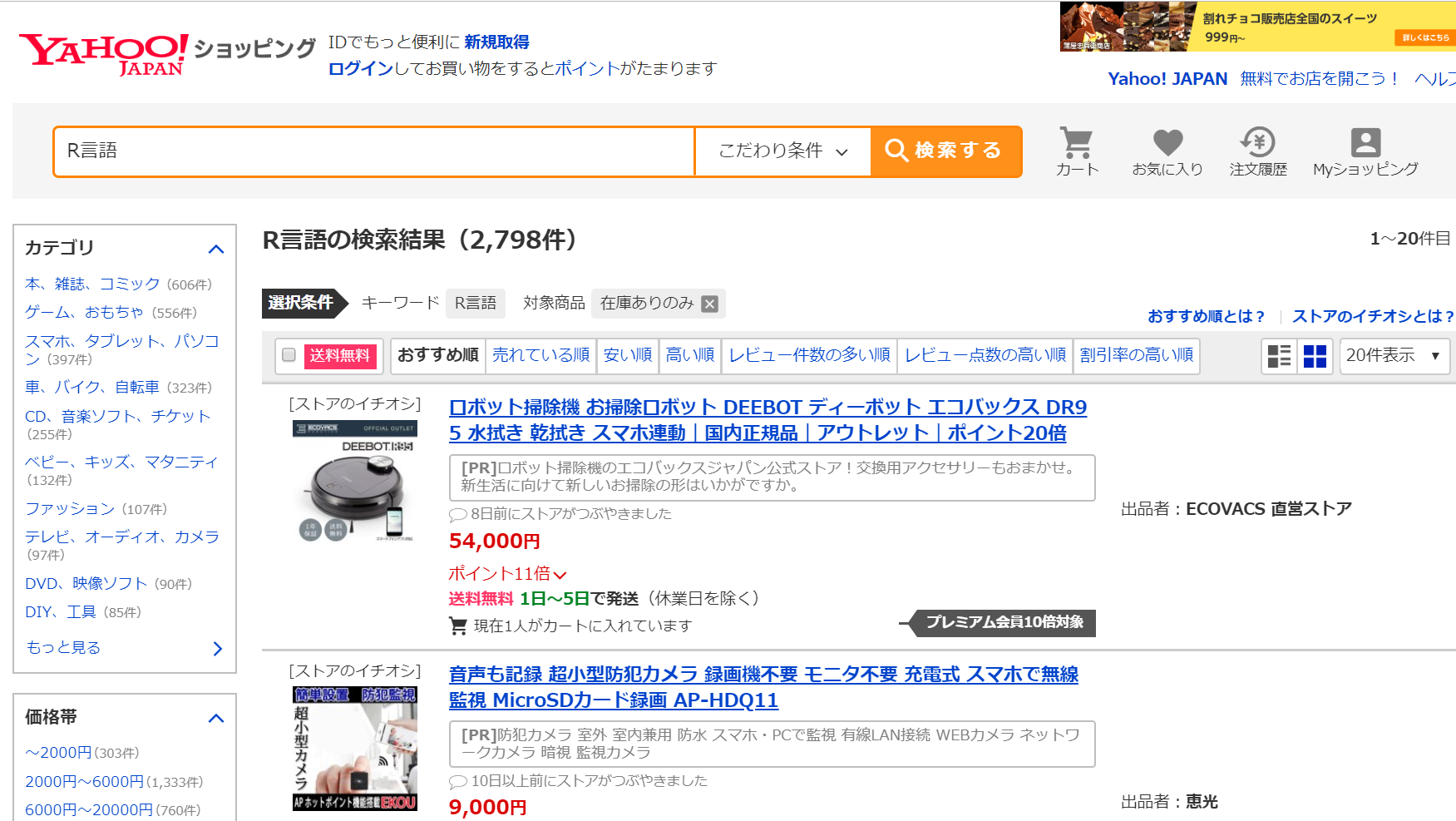
こういう感じの画面がでて来ます。1ページに付き20件で検索結果は全部で140ページあります。これをまとめて取得したいと思ったらまず上部のサイトのURLを見ながら商品ページを切り替えていきましょう。するとURLの末尾が1,21,41,61…と変移しているのがわかります。
https://shopping.yahoo.co.jp/search?p=R%E8%A8%80%E8%AA%9E&tab_ex=commerce&oq=&uIv=on&pf=&pt=&ss_first=1&ei=UTF-8&b=1
https://shopping.yahoo.co.jp/search?p=R%E8%A8%80%E8%AA%9E&tab_ex=commerce&oq=&uIv=on&pf=&pt=&ss_first=1&ei=UTF-8&b=21
https://shopping.yahoo.co.jp/search?p=R%E8%A8%80%E8%AA%9E&tab_ex=commerce&oq=&uIv=on&pf=&pt=&ss_first=1&ei=UTF-8&b=41
このように規則性がある場合はfor文で回せば一括で取得することができます。先ほどのR-tipsの場合は1,2,3,4,5と順番に代入していきましたが今回は1,21,41,61なので「i」に代入する数字を少し変えます。
#スクレイピング結果を保存する空のリストを作る
x<-list()
#コードを見やすくするためベースのURLを変数に格納する
endpoint="https://shopping.yahoo.co.jp/search?p=R%E8%A8%80%E8%AA%9E&tab_ex=commerce&oq=&uIv=on&pf=&pt=&ss_first=1&ei=UTF-8&b="
#ヤフーショッピングの検索結果を取得する
for (i in seq(1, 2781, 20)){
+ url<-paste(endpoint,i,sep = "")
+ yahoo <- read_html(url,'utf-8')
+ x<-append(x, list(yahoo))
+ Sys.sleep(10)
+ }
処理の流れ自体は先ほどと同じです。少し違うのはまず「i」に代入する数列です。今回は単なる数列ではなく、等間隔の数列を生成するseq()関数を使用しています。seq(1, 2781, 20)とすれば、1,21,41…みたいな数列を生成することができます。
そして、read_html()の引数に指定する文字コードを、先ほどのshift-Jisにしておくとエラーになったので「utf-8」に変えます。またwebスクレイピングで1つのサイトに連続してアクセスすると、向こうからerror999(同一IPからの短時間の高頻度リクエストがあった場合セッションを遮断する)を返されるので、繰り返し処理1回あたりSys.sleep(10)で10秒インターバルを設けました。
そして、スクレイピングしたYahooショッピングのデータを確認すると以下のように形になっていると思います。
> x
[[1]]
{xml_document}
<html lang="ja">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n< ...
[2] <body>\n<script async="true" language="javascript" src="//acdn.adnxs.com/ast/s ...
[[2]]
{xml_document}
<html lang="ja">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n< ...
[2] <body>\n<script async="true" language="javascript" src="//acdn.adnxs.com/ast/s ...
[[3]]
{xml_document}
<html lang="ja">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n< ...
[2] <body>\n<script async="true" language="javascript" src="//acdn.adnxs.com/ast/s ...
まとめ
以上がfor文を使った一括スクレイピングの方法です。for文の例題にもこういった感じの問題はあまりないのでスクレイピングなどでどうやってfor文やif文を使うの?と疑問に思っていたかたの助けになれば幸いです。コメントの方で質問してくだされば極力返信いたします。
次はこのスクレイピングしたHTML・XMLのデータの中から自分の欲しいデータだけを抽出する方法について解説していきたいと思います。


コメント