前回のまとめ
前回はRの「Rvest」というパッケージを使用して、大量をhtmlページをfor文を使ってまとめてスクレイピングしました。

今回はそのスクレイピングしたデータを引き続き「Rvest」を使って、自分を欲しいデータ部分だけを抽出する方法について解説していきます。
取得したHTMLデータを解析する
とりあえずデータは取得できたので、次はこの中から必要な情報だけを抽出する処理を行っていきたいと思います。とりあえずお試し用にデータを1つサンプルとして使います。
>sample<-x[10]
>sample
※実行結果
[[1]]
{xml_document}
<html lang="ja">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n<meta ...
[2] <body>\n<script async="true" language="javascript" src="//acdn.adnxs.com/ast/stati ...
xml_documentと書いてあるので、これはhtmlではなくXMLだということが分かります。まずは取得したデータのHTML構造を確認します。
#HTML構造を確認する html_structure(sample[[1]])
これを実行すると延々とHTMLツリーが実行されます。ここで欲しいはページ全体のhtmlデータではなく、検索結果で出てきた商品の情報です。なので、この膨大なhtmlタグの中から欲しい情報を格納しているタグを探す必要があります。Rvestで指定したあるHTMLノードを抽出するためには「html_nodes()」を用います
そして、自分の欲しい情報がどのタグに囲まれているかを探すときは、ブラウザからサイトのソースを確認するのが一番手っ取り早いです。ブラウザからサイトのhtml情報を確認するにはGoogle Chromeが一番便利なのでオススメです。
Google Chromeの場合はサイトで「右クリック→検証」をクリックします。するとページのソースが表示されます。
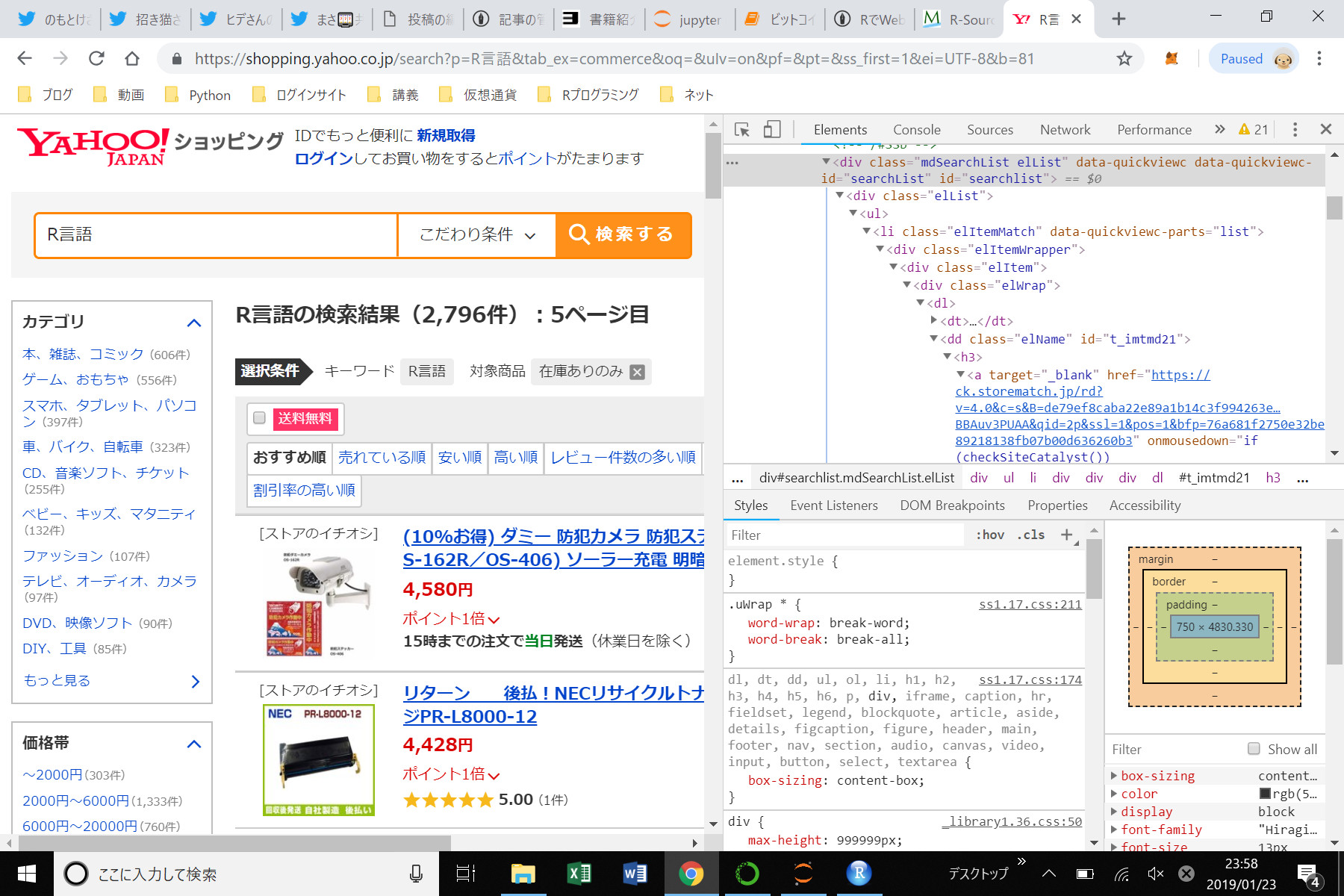
この形になったら次は中央の商品の検索結果の部分を右クリックしてもう一度検証をクリックします。
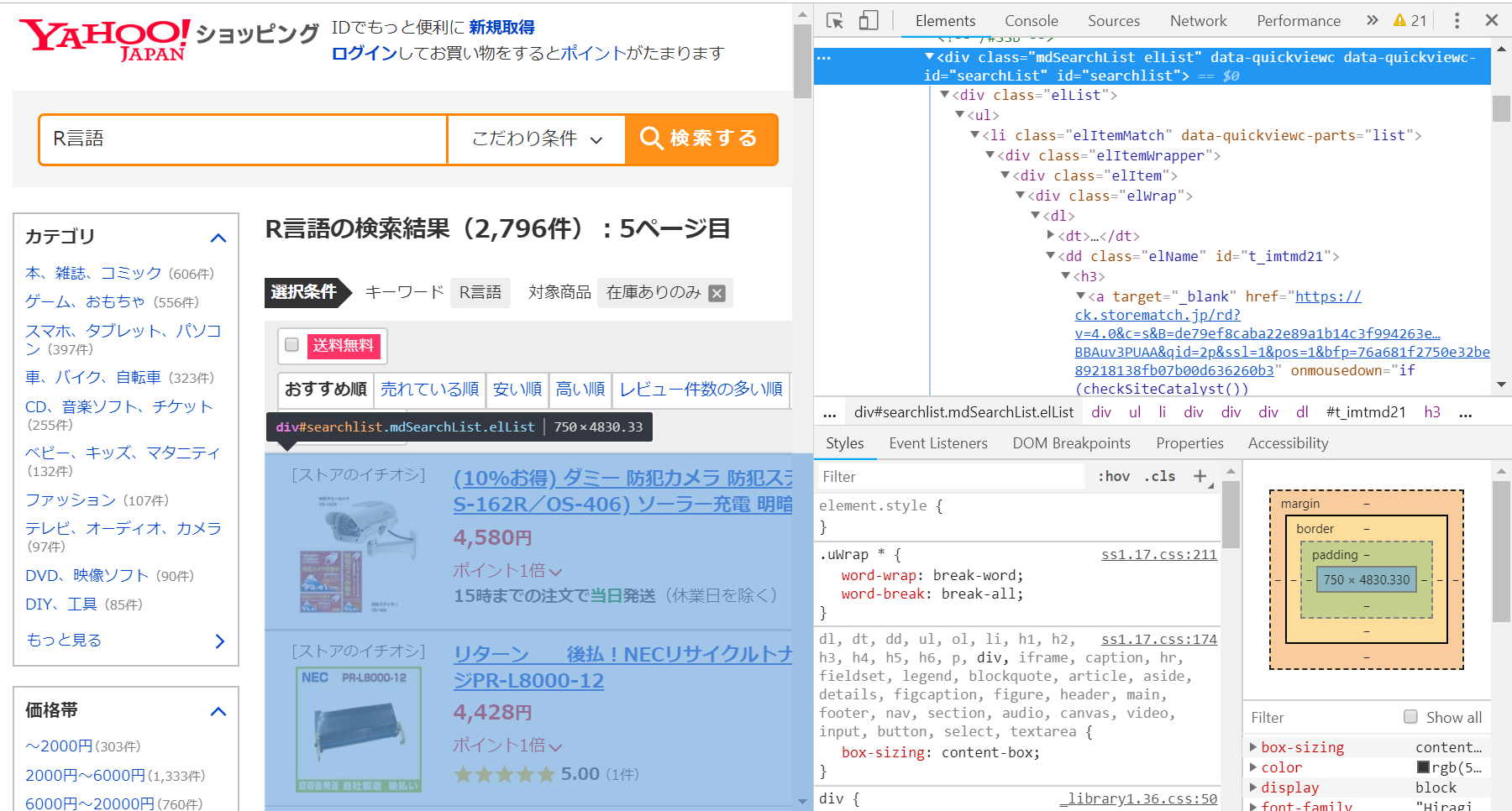
すると指定した部分に対応するタグがドラッグされます。他にも右側のソースコードの部分をクリックすると、対応するブラウザの部分がドラッグされるので、自分の欲しい情報の部分に対応しているhtmlタグを見つけましょう。商品名は<h3></h3>タグに囲まれています。なのでまずはh3タグに囲まれた部分を抽出してみます。
#h3タグの中身を抽出する word<-html_nodes(sample[[1]], "h3") word ※実行結果 {xml_nodeset (48)} [1] <h3><a target="_blank" href="https://store.shopping.yahoo.co.jp/ecovacsjapan/dr95 ... [2] <h3><a target="_blank" href="https://store.shopping.yahoo.co.jp/ekou/ls-r2.html" ... [3] <h3><a target="_blank" href="https://store.shopping.yahoo.co.jp/dendouki2/fuj-np1 ...
ヤフーショッピングのサイトのソースと照らし合わせてみると、この<h3>で囲まれた部分が抽出できているのが分かります。
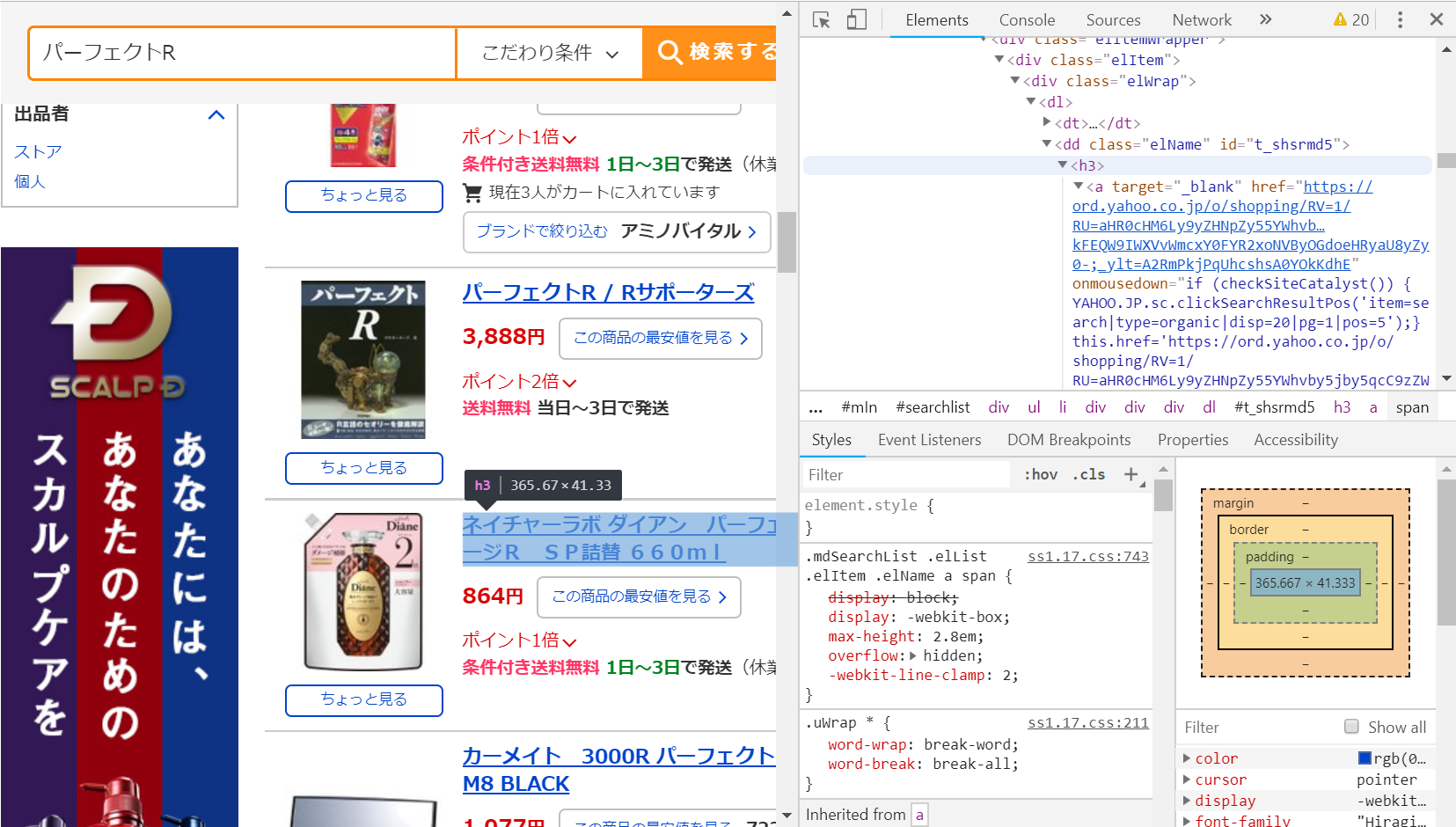
そして、今回取得したい商品名は<span>タグに囲まれていることが分かるので、次はここから<span>タグの部分だけを抽出していきます。
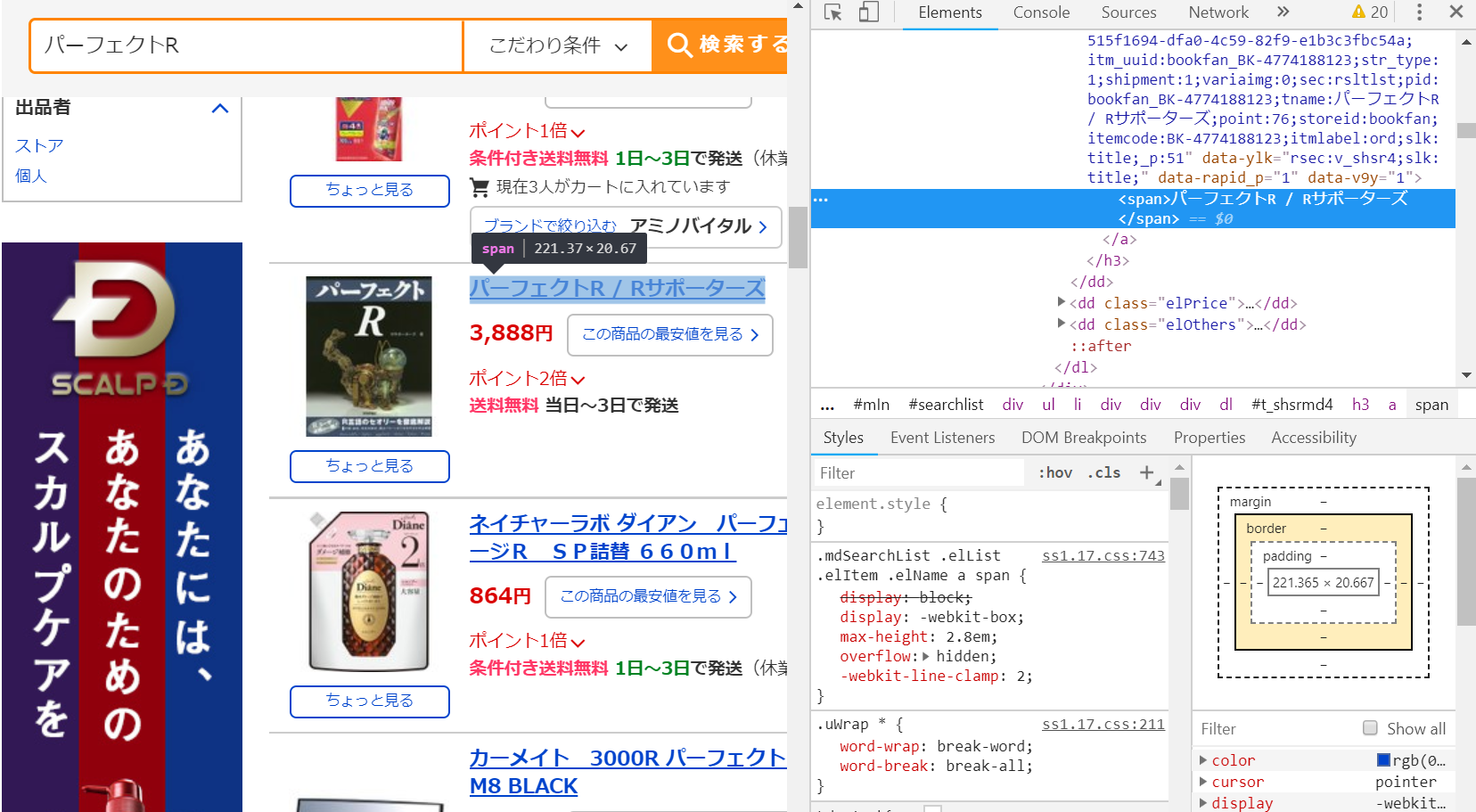
#<span>タグに囲まれた部分を抽出する >names<-html_nodes(word, "span") %>%html_text() #中身を確認する > names ※実行結果 [1] "ロボット掃除機 床拭き お掃除ロボット DEEBOT ディーボット R95 水拭き 乾拭き スマホ連動 |ECOVACS エコバックス|国内正規品|ポイント20倍" [2] "音声も記録 超小型防犯カメラ 録画機不要 モニタ不要 充電式 スマホで無線監視 MicroSDカード録画 AP-HDQ11" [3] "富士電機 NP1PM-48R プログラマブルコントローラ MICREX-SX SPHシリーズ" [4] "富士電機 NP1PS-74R プログラマブルコントローラ MICREX-SX SPHシリーズ" [5] "言語学 / 認知文法のエッセンス/ジョンR.テイラー/瀬戸賢一" [6] "9インチ Android4.4搭載タブレット デュアルコアCPU ROM:8GB Office搭載 日本語対応 HDMI出力 F/Rダブルカメラ K9023" [7] "ボードゲーム チケット・トゥ・ライド:ニューヨーク 多言語版(295275)" [8] "SP.1246 ニスモR34 GT-R Zチューン 未塗装クリアボディ 51246 [TMYTAM51246] [タミヤ(TAMIYA)]" [9] "「R」Commanderハンドブック/舟尾暢男【著】" [10] "アート・オブ・Rプログラミング" [11] "みんなのR" [12] "パーフェクトR" [13] "シリーズUseful R 7" [14] "誰にでもできるらくらくR言語" [15] "新品本/フレッシュマンから大学院生までのデータ解析・R言語 渡辺利夫/著" <
こうすると商品の検索結果の部分だけをピンポイントで抽出できます。
終わり
以上がRvestを使ったスクレイピングの方法と取得したHTML・XMLデータの解析方法です。R言語を使用したwebスクレイピングについて、本格的に勉強するならば「Rによるスクレイピング入門」という参考書がオススメです。入門と書いてますが実務で使えるレベルのことが分かりやすく書いてあります。



コメント