
機械学習系シリーズ記事
→Pythonと機械学習で株価を予測する~Scikit-learnの決定木アルゴリズムを使う
→【Python】機械学習ライブラリ「Scikit-learn」を使ったビットコインの価格予測
→【Python】ビットコイン価格をディープラーニングで予測する
ビットコインの価格データを取得する
<作業環境>
- Python3.6
- Windows10
- Jupyter Notebook
まずはビットコインの価格データをスクレイピングで取得します。
参照記事:【Python】CoinGeckoのAPIからビットコイン・アルトコインの価格データを取得する
# ライブラリの読み込み
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import time
import requests
import json
from datetime import datetime
def get_btcprice(ticker,max):
url = 'https://api.coingecko.com/api/v3/coins/' + ticker + '/market_chart?
vs_currency=jpy&days=' + max
r = requests.get(url)
r2 = json.loads(r.text)
return r2
# jsonから価格データだけをPandasに変換して抽出する
def get_price(r2):
s = pd.DataFrame(r2['prices'])
s.columns = ['date', 'price']
date = []
for i in s['date']:
tsdate = int(i / 1000)
loc = datetime.utcfromtimestamp(tsdate)
date.append(loc)
s.index = date
del s['date']
return s
# ビットコインの全期間の価格データを取得する
r2 = get_btcprice('bitcoin', 'max')
btc = get_price(r2)
価格データが取得出来たら、次は変化率を計算します。今回は普通の変化率でも問題ないと思いますが、一応対数変化率を使います。
# 対数収益率の計算 change = btc['price'].apply(lambda x: np.log(x)).diff(periods=1)
対数変化率を計算したら次はtalibでテクニカル指標を算出します。
参照→【Python】テクニカル指標が簡単に計算できるTa-libの使い方
# talibでテクニカル指標を計算する import talib price = btc['price'] momentum = round(talib.MOM(price, 5), 0) macd = talib.MACD(price) rsi = round(talib.RSI(price, timeperiod=7), 0)
これで必要なものは揃ったので、一応データフレームにして概要を把握します。
# 各データをつなぎ合わせてデータフレームを作成
df = pd.DataFrame({"date": btc.index, "price": change * 100, "mom": momentum, "macd": round(macd[2], 0), "rsi": rsi})
# プロットする画像のサイズを拡大する
from pylab import rcParams
# テクニカル指標を可視化する
plt.subplot(3, 1, 1)
plt.plot(df['rsi'][-30:])
plt.ylabel('RSI')
plt.grid(which='both')
plt.subplot(3, 1, 2)
plt.plot(df['macd'][-30:],)
plt.ylabel("MACD")
plt.hlines([0], df.index[-30], df.index[-1], "red", linestyles='dashed')
plt.grid(which='both')
plt.subplot(3, 1, 3)
plt.plot(df['mom'][-30:])
plt.ylabel("Momentum")
plt.hlines([0], df.index[-30], df.index[-1], "red", linestyles='dashed')
plt.grid(which='both')
<実行結果>
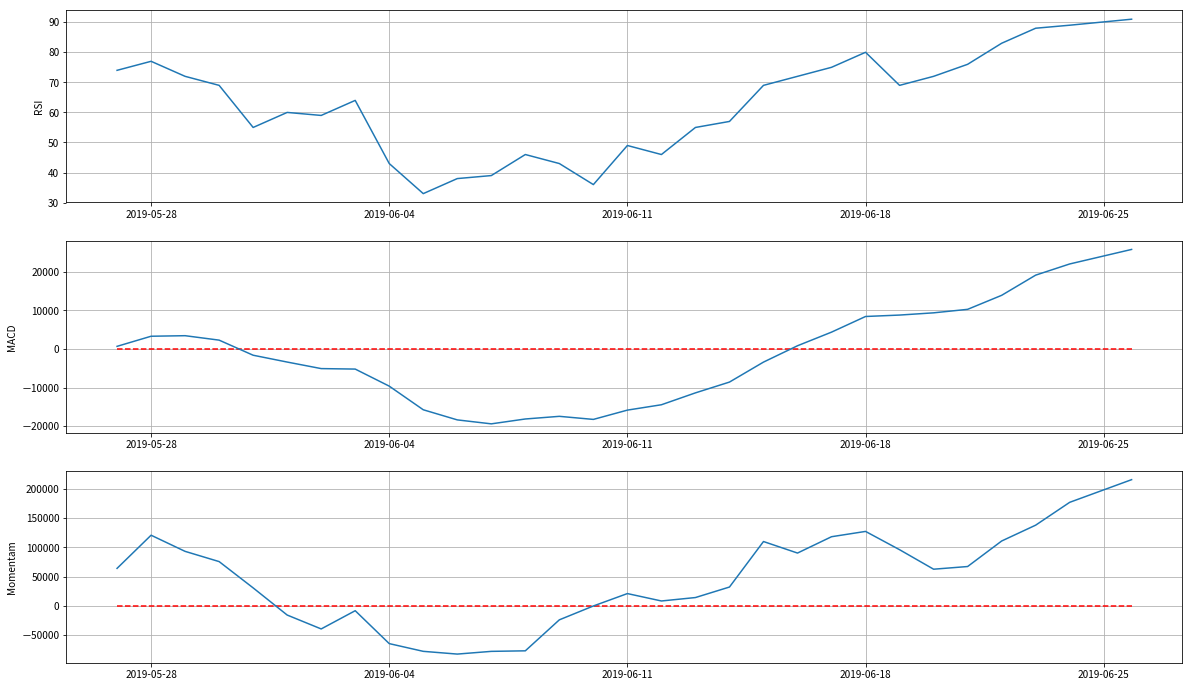
いよいよ本題の機械学習に入っていきます。まずは分析におけるxとyを設定します。今回知りたいのは価格が上がるか下がるかなので、y:被説明変数を価格の変化率にします。そして、x:説明変数をテクニカル指標(RSI・MACD・モメンタム)の数値にします。
# 説明変数xと被説明変数yを決める y = df['price'][35:] x = df[['rsi', 'mom', 'macd']][34:-1] # 要素数が同じくかを確認 print(len(x), len(y))
説明変数と被説明変数を定義したら、次は変化率-1と1に変換します。変換する理由としては、機械学習は回帰よりも分類の方が精度が高くなる傾向があるからです。この場合価格が上がっていたら1、下がっていたらー1という風にラベル付けしてあげます。ラベル付けした後に機械学習の関数に当てはまられるようにreshape()で次元を変換します。
# 変化率をシグナルに変換する
signal = []
for i in y:
if i > 0:
signal.append(1)
elif i < 0:
signal.append(-1)
# 機械学習用に次元を変換する
y2 = np.array(signal).reshape(-1,)
これでデータが整ったので、最後にデータを訓練用とテスト用に分割します。
# データを7:3に分割する import sklearn from sklearn.model_selection import train_test_split (X_train, X_test,y_train, y_test) = train_test_split(x, y2, test_size=0.3, random_state=0, shuffle=False)
決定木で可視化する
というわけでいよいよ機械学習に入っていきます。まずは決定木で分析して精度と可視化して有効性の高そうな変数を確認しましょう。
# ライブラリの読み込み
from sklearn import tree
# 決定木モデルの呼び出し
clf = tree.DecisionTreeClassifier(max_depth=5)
# 学習開始
clf = clf.fit(X_train.values, y_train)
#作成した機械学習モデルをテストデータに当てはめる
predicted = clf.predict(X_test)
# モデルのテストデータに対する精度を確認
score=sum(predicted == y_test) / len(y_test)
print('モデルの精度は{}%です'.format(score * 100))
# 決定木を画像にして出力する
import pydotplus
from sklearn.externals.six import StringIO
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data, feature_names=df.columns[-3:],)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
from IPython.display import Image
Image(graph.create_png())
うーん精度は50%前後とあまり宜しくない・・・というダメダメですね。とりあえず、可視化した決定木を見てみます。↓
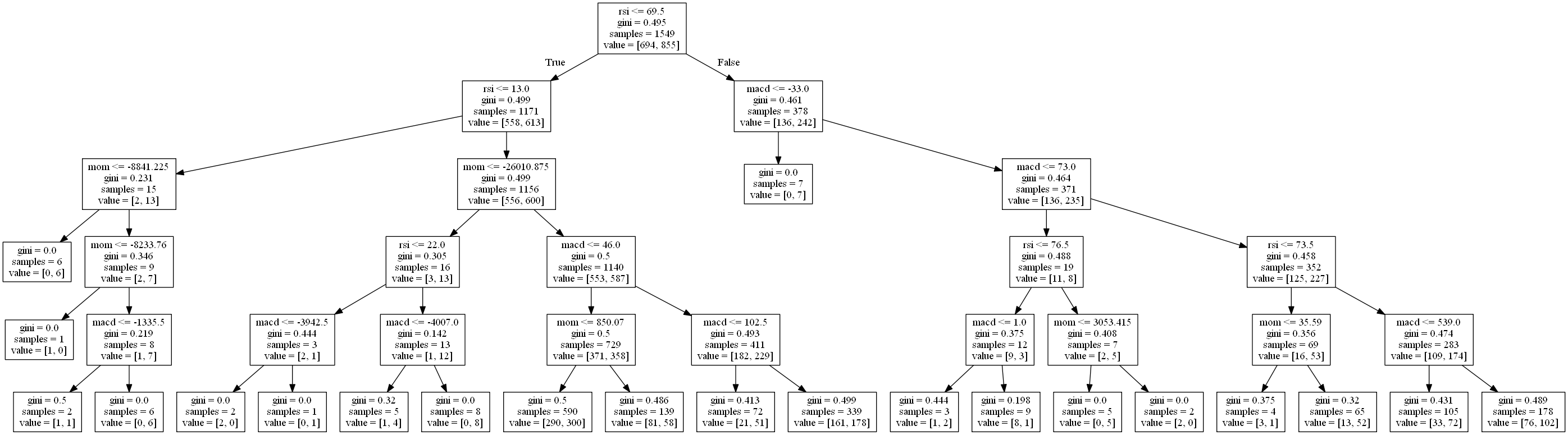
ざっとと見て初めにRSIが69.5未満かどうかで大きく分かれているので、これがまず一番効いてそうな変数説明だと分かります。FALSEを選ぶと[136,242]で約64%で上がることが予測できています。ただサンプル数が378/1549なので、有効な場面が少なそうです。
本来は決定木の結果からアプローチをかけていくのですが、今回はあまりに精度が悪いので、とりあえず置いといて、他の機械学習アルゴリズムを試していきます。
教師データありアルゴリズムで交差検証しつつ機械学習する
from sklearn import svm
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn import tree
from sklearn import neighbors
kfold = KFold(n_splits=5)
n_neighbors = 5
# 機械学習アルゴリズムのリスト
logic = [[tree.DecisionTreeClassifier(max_depth=5),'決定木'],
[LogisticRegression(),"ロジティクス回帰"],
[svm.SVC(),"サポートベクトルマシーン"],
[RandomForestClassifier(min_samples_leaf=3, random_state=0),"ランダムフォレスト"],
[neighbors.KNeighborsClassifier(n_neighbors, weights = 'distance'),"k-近傍法"]]
# for文でアルゴリズムごとに機械学習して結果を算出する
for i in logic:
# 交差検証
scores = cross_val_score(i[0], x, np.array(signal),cv=kfold)
# 各分割におけるスコア
print('Cross-Validation scores: {}'.format(scores))
# スコアの平均値
print('{}の平均スコア: {}%'.format(i[1],round(np.mean(scores)*100,2)))
<実行結果>
Cross-Validation scores: [0.52595937 0.50790068 0.55079007 0.47629797 0.48868778]
決定木の平均スコア: 50.99%
Cross-Validation scors: [0.53273138 0.51015801 0.57562077 0.5778781 0.54298643]
ロジティクス回帰の平均スコア: 54.79%
Cross-Validation scores: [0.53273138 0.51015801 0.57562077 0.5778781 0.54977376]
サポートベクトルマシーンの平均スコア: 54.92%
Cross-Validation scores: [0.49435666 0.48532731 0.51241535 0.48306998 0.50226244]
ランダムフォレストの平均スコア: 49.55%
Cross-Validation scores: [0.503386 0.50790068 0.51467269 0.50112867 0.51357466]
k-近傍法の平均スコア: 50.81%
うーんあまり良くないですね。ほとんど50%なので、ただ半丁博打しているのと大差ないです。しいていうなら線形で分類する系のアルゴリズムがちょっと有効性あるかな程度。。。
機械学習の精度を左右するのはモデルよりもデータの質なので、とりあえず説明変数(x)にあたるRSI・MACD・モメンタムの数字、つまりは特徴量を機械がより分かりやすくように手直しして再挑戦したいと思います。

→Pythonと機械学習で株価を予測する~Scikit-learnの決定木アルゴリズムを使う
→【Python】機械学習ライブラリ「Scikit-learn」を使ったビットコインの価格予測
→【Python】ビットコイン価格をディープラーニングで予測する

コメント