今回は前回に引き続いてディープラーニングによる分析を行っていきたいと思います。多層パーセプトロン・畳み込みニューラルネットワーク(CNN)と来たので、次はリカレントネットワーク(RNN・LSTM)を使った分析を行っていきたいと思います。

リカレントネットワーク(RNN)はデータの順番に意味のあるデータ、つまり時系列データや会話データに対して使うのが一般的ですが、今回は手書き文字ではなく、株価・ビットコインといった金融データをつかって行っていきます。
一般的な株価分析・予測の流れ
実際の株売買に関しての話 一般的な株予測というのは、もちろんリターンを算出することにあります。ではこの場合のリターンとは一体を何を指すのでしょうか?
ここが株価分析を始めたての人が分かりにくいなと思うポイントだと思うのですが、一般的に株価分析におけるリターンとは当日と前日を比較した変化率のことを指します。
もしn日に100円でn+1日目に110円になった場合変化率は0.1(10%)となります。ようするに機械学習における一般的な株価予測とは、「当日までの過去〇日の価格データを使用して、次の日の上昇・下降」を予測するという作業が基本です。
ですが、現実問題はそんなに簡単ではなく、 当日のデータとは当日の何時に手に入るのか? 当日の終値を使用して予測した場合、当日の終値では買えない。 当日の終値で買えないので、次の日の寄値で買うことになるが、終値=寄値ではないし売買における取引手数料を超えるだけのリターンを得られるのか? などなどの様々な課題があります。
なので、単純に価格を計算して理論上売買しただけのバックテストの成績はよくても実際の売買ではてんで使えないなんてこともあります。これらの点は予測よりも重要な問題になることが多いので、単に分析するだけではなくBotにして本当に儲けようと考えている場合は注意しないといけません。
ディープラーニングによる株価予測
株価予測には移動平均線やRSIといったテクニカル指標を使うこともあれば、最近だと機械学習・深層学習で分析した結果を使用することもあります。

当たり前ですが、株価分析・予測において簡単に結果が出れば誰でも大金持ちなので、基本的にそんな期待しないほうが良いです。予測結果をもとにしたBot取引やなどはお金が簡単に稼げる打ち出の小づちではないということだけ覚えておいてください。ただ特定条件下なら使えたり少額のロットなら成果はでるので、いろいろと創意工夫すればある程度の結果は出せると思います。
pythonによるディープラーニングでの株価予測
というわけで本題のディープラーニングによる価格予測に入っていきたいと思います。ディープラーニングはpythonのライブラリが充実しているのでpythonでやるのがオススメです。

今回は「keras」という機械学習用ライブラリを使って行います。pythonにはkerasの他にもTensorflowやPytorchなどの機械学習用ライブラリがありますが、kerasが一番簡単に使えるのでkerasにしています。一応計算にscikit-learnというライブラリもインストールしておく必要があります。
# ライブラリのインポート import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras import optimizers from keras.layers.recurrent import SimpleRNN from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error from keras.layers.normalization import BatchNormalization from keras.layers.advanced_activations import LeakyReLU import matplotlib.pyplot as plt import numpy as np %matplotlib inline
次はビットコインの価格を取得します。取得に使う関数については以下の記事で解説しています。

##ライブラリーのインストール
import pandas as pd
import time
import matplotlib.pyplot as plt
import datetime
import requests
import json
import numpy as np
%matplotlib inline
def get_bitcoinprice():
url=('https://api.coingecko.com/api/v3/coins/')+str('bitcoin')+('/market_chart?vs_currency=jpy&days=max')
r=requests.get(url)
r=json.loads(r.text)
bitcoin=r['prices']
data=[]
date=[]
for i in bitcoin:
data.append(i[1])
date.append(i[0])
bitcoin=pd.DataFrame({"date":date,"price":data})
price=bitcoin['price']
a=price.pct_change()
bitcoin=pd.DataFrame({"date":date,"price":data,"change":a})
return bitcoin
この関数を実行すると以下のようなデータフレームができます。Priceがビットコインの価格、changeが前日の価格と比較した変化率です。
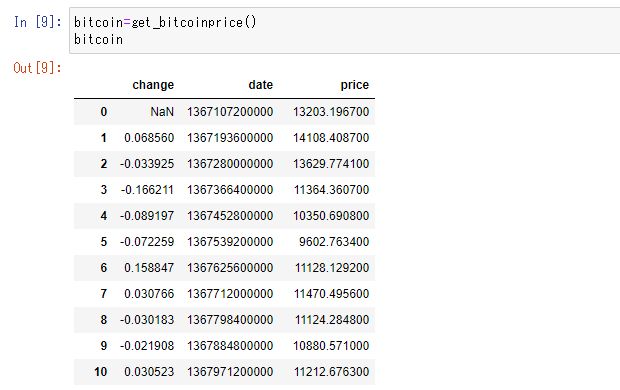
今回は変化率を使うのでchangeを抽出します。すると以下のようなpandas形式の時系列データが出てきます。
>>>price=bitcoin['change'] >>>price 0 NaN 1 0.068560 2 -0.033925 3 -0.166211 4 -0.089197 5 -0.072259 6 0.158847 7 0.030766 8 -0.030183 9 -0.021908 10 0.030523 11 -0.004451 12 0.053482
ビットコインの価格を取得と変化率の計算ができたら、次はデータを深層学習に使えるようにするために整形していきます。今回の方針としては30日分の仮想通貨の価格を学習させ、次の日に上がるか下がるかを検証するという方針でいきます。
つまり30日ごとの価格データと31日後に上がったか下がったかどうかの結果のデータを用意する必要があります。プログラムで実装するには、30日分の変化率の配列が格納されたテストデータと31日後上がっていたなら1、下がっていたなら0みたいな感じで1か0で表現された正解のテストデータの組み合わせを用意する必要があります。この辺のデータの準備方法は画像認識の記事を参考にしていただけると分かるかと思います。
まずは先ほどのビットコインの変化率のデータをnumpyの行列に変換します。
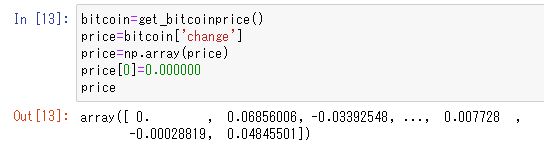
# numpy行列に変換する price = np.array(price) price[0] = 0
これで>>>priceの中身を確認すると、以下のような形になっていればOKです。price[0]=0は欠損値がエラーの原因になるので0で穴埋めしているだけです。
ビットコインの変化率のデータをnumpyの行列に出来たら、次はディープラーニングに使う「教師データ」と「正解データ」を用意します。上でもチラッと触れましたが、ここでは30日ごとの価格の変化率が入った配列とそれに対応した31日後に上がったか下がったかどうかの結果が格納されたデータを用意する必要があります。
プログラムでこの処理を行うには、30日分の変化率の配列が格納されたテストデータと31日後上がっていたなら1、下がっていたなら0みたいな感じで1か0で表現された正解のテストデータの組み合わせを用意する必要があります。この辺のデータの準備方法は画像認識の記事を参考にしていただければ分かるかと思います。
# 価格データをディープラーニング用に整形する
term = 30
pricedata = []
answer = []
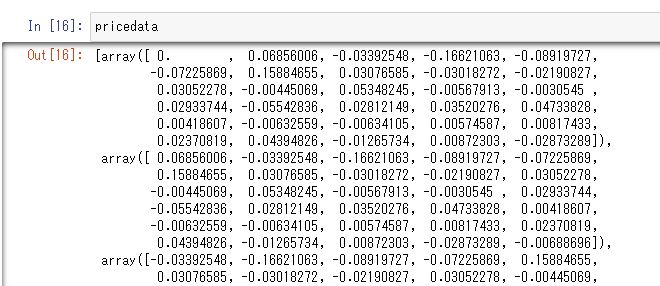
for i in range(0, length-term+1):
pricedata.append(price[i: i+term])
answer.append(price[i+term])
確認すると↓のようなデータが格納されていると思います。
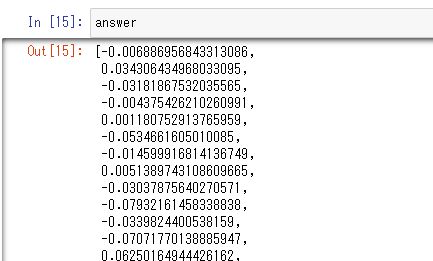
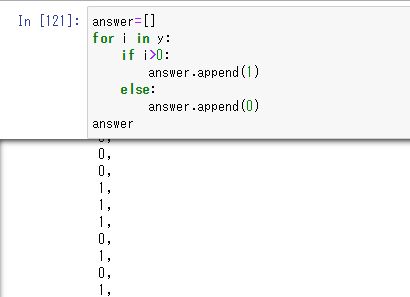
そして、answerの方を上がるか下がるかの1か0に整形します。if文で変化率が0が大きければ(価格が上がったなら)1、0より小さいならば0を格納するように条件分岐させます。
answer=[]
for i in y:
if i>0:
answer.append(1)
else:
answer.append(0)
answer
最後に行列の次元を増やします。numpyでは「np.reshape()」という関数で配列の次元を増やすことができます。アルゴリズムにfit()させる際に要求される配列の次元はRNNやLSTMでも関数ごとに違うので、keras公式ドキュメントかエラーメッセージを確認してください。
# numpy配列の次元を増やす x = np.array(pricedata).reshape(len(pricedata), term, 1) y = np.array(answer).reshape(len(pricedata), 1)
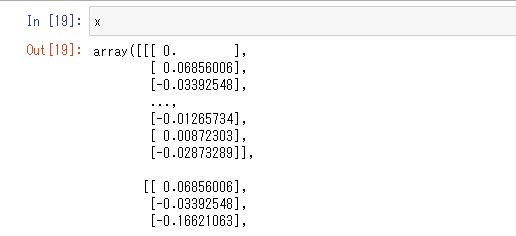
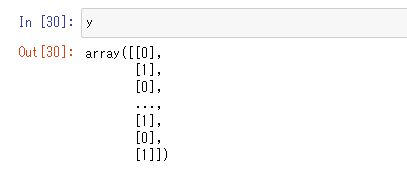
そして、「np.shape()」関数で配列の全体構造を確認して変換できているか確認します。この場合だとx.shapeでxのデータの構造を確認できます。
# データの構造を確認する >>>x.shape (1917, 30, 1) >>>y.shape (1917, 1)
xとyのデータ数が同じであることを確認します。データ数が違うとモデルにデータを入れるときにエラーになるので注意してください。(※最初の配列のデータ数である1917は全期間のビットコインの日足数なので、執筆時点の今日から日にちが経つごとに増えます)
確認出来たら次はデータを訓練データと教師データに分割します。データの分割には「train_test_split()」という関数を使います。データの分割割合は7:3.8:2くらいがデフォだと思います。
# データを訓練用とテスト用に分割する (X_train, X_test,y_train, y_test) = train_test_split(x, y, test_size=0.3, random_state=0,shuffle=False)
ここで注意したいのが引数の shuffle=Falseの部分です。時系列に意味がないデータの場合は必要ありませんが、今回は時系列データなので未来のデータを学習に使わないようにデータの順番をシャッフルしないように指定します。
そして、最後に30日間の価格変化に対する31日後のビットコインの価格が上がったか下がったかの結果のデータ(y_train・y_test)をonehotベクトルに変換します。
今回は0か1の配列なので、引数は2とします。onehotベクトルの設定については画像の認識の記事で説明していますので省略します→【Python】Kerasでディープラーニングによる画像認識をやってみる
# ベクトルからonehotベクトルに変換する(正解を列にして表示する作業) y_train = keras.utils.to_categorical(y_train, 2) y_test = keras.utils.to_categorical(y_test, 2)
LSTMによるディープラーニングモデルの構築
今回は時系列データの分析なので、リカレントネットワーク(RNN・LSTM)を使います。kerasではリカレントネットワークも引数1つで簡単に実装することができるので便利ですね。
# リカレントネットワークの構築 model = Sequential() model.add(LSTM(512, kernel_initializer='random_normal', input_shape=(30, 1))) model.add(Dense(2, activation='softmax'))
コードの処理をざっくり説明すると、中間層の関数をLSTMとすることでリカレントネットワークをしています。最初の512は出力するニューロンの数です。多ければ多いほど複雑になり計算に時間が掛かります。
次のkernel_initializerは重みの初期設定、input_shapeは入力データの次元数を設定します。今回の入力データは、x.shape (1917, 30, 1)なので、(30,1)とします。
最後のmodel.addは出力層を定義しています。今回は上がるか(1)下がるか(0)の2択なので、0か1の2種類の分類問題と言えるので、出力層の次元数は2で活性化関数はソフトマックス関数にします。
#モデルの評価方法を決める model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
今回は上がるか(1)か下がるか(0)の2項分類問題なので、クロスエントロピーが良いかと思われがちですが、リカレントネットワークでは二乗誤差を採用します。評価指標は正確率を使います。
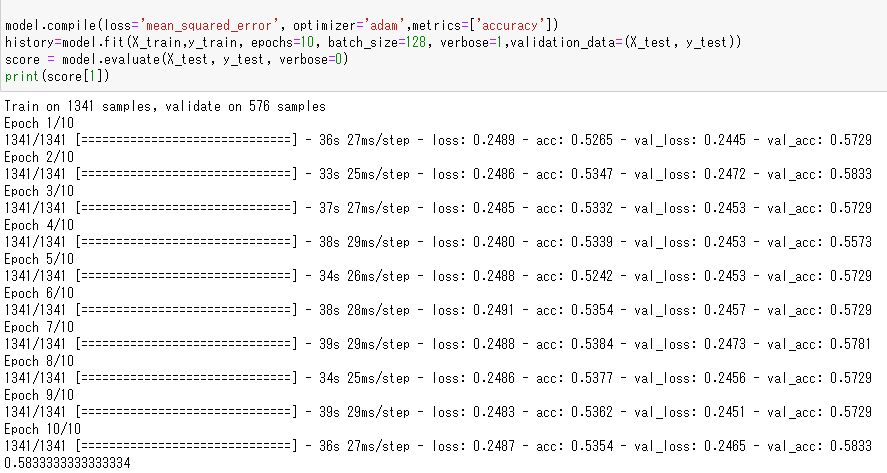
# モデルにデータを学習させる result = model.fit(X_train, y_train, epochs=10, batch_size=128, verbose=1, validation_data=(X_test, y_test)) # 学習結果を確認する score = model.evaluate(X_test, y_test, verbose=0) print(score[1])
結果は以下の様に58.3%となりました。まあ過学習気味でもなく、めっちゃ当たっている訳でもない無難な数字となりましたね。
デモ用なので計算が早く終わるように学習回数は10回にしましたが、学習回数を増やしたりすればもうちょっと精度が上がると思います。
終わり
以上が株価・ビットコイン価格を使ったディープラーニングの流れです。ディープラーニングをpythonで実際に実装するにあたって躓きやすいのが、モデルにデータを学習させるときの入力次元と出力次元の設定です。
model.fitでのエラーの原因の9割はここにあると思うので、実装する際はデータの整形、引数の設定を十分に気をつけてください。
自分も最初そうだったのですが、Pythonだけでなく深層学習(ニューラルネットワーク・ディープラーニング)の実装は自分が、そういう訓練データとテストデータを使ってどういうモデルを組もうとしてのかがちゃんと頭の中で整理できていないと、自分が用意したオリジナルのデータを学習させようとするときにエラー祭りのドツボにハマるので、理論自体の仕組みと流れ、実装する際のkerasの関数の意味を十分に理解した方がいいと思います。

まあ学習結果自体はこんな簡単にいい結果がでれば苦労しないよね・・・的なオチでしたが、小技を挟むと予測精度ももうちょいよくなるかもしれません。
Botに実装するのであれば、さくらVPSやAWSあたりのレンタルサーバーでこの計算処理を行ってその判断に基づいて売買させるということも可能でしょうね。
ちなみにこの分析をするのに、参考にさせていただいた参考書は「PythonとKerasによるディープラーニング 」と「 詳解 ディープラーニング ~TensorFlow・Kerasによる時系列データ処理~」 の2冊です。
自分はディープラーニングを独学で勉強する上で、これらの他にも机に積み上がるくらい色んな深層学習の参考書を購入しましたが、畳み込みとリカレント系のディープラーニングモデルを構築する上ではこの2冊が超役に立ちましたので、感謝も込めて紹介しておきます。


こんな感じでプログラミングと数学を駆使すれば誰でもクオンツのごとく金融データ分析をおこない、実際に投資して利益を上げることもできないことはないです。
深層学習について一通りまとめたので締めに入りますが、ディープラーニングや機械学習の勉強において自分が思うのは目的のないデータ分析は何の意味もなくむなしいものだということです。そんなモチベーションで勉強しても全然勉強していても身が入りません。
ですが、たとえば株価データを分析・予測してBotなりにして投資に役立てるという明確な目的があった場合は、そのために必要なデータ分析スキルの勉強は取り組みがいのあるものになるのではないかと思います。
要するに何が言いたいのかというと、データ分析・プログラミングは目的なく勉強しても空しいだけなので、投資で儲けるなり、何かの問題を解決したい・ゲームを作りたいなどの勉強する動機を持たせると勉強効率が上がるよってことです。
ニューラルネットワーク・深層学習はぱっと見は超とっつきにくそうですが、理論自体は思ったよりシンプルなので、ぜひ勉強してみてください。




コメント
[…] ミナピピンの研究室【Python】ビットコインの価格をディープラーニングで分類予測するhttps://tkstock.site/2018/08/28/post-648/ 今回は前回に引き続いてディープラーニングによる分析を行っ […]