
仕事で決定木関連について後輩から質問されてたのですが、よくよく考えると決定木についてちゃんと理解していなかったな~・・・と感じたので自分用にまとめてみました
決定木
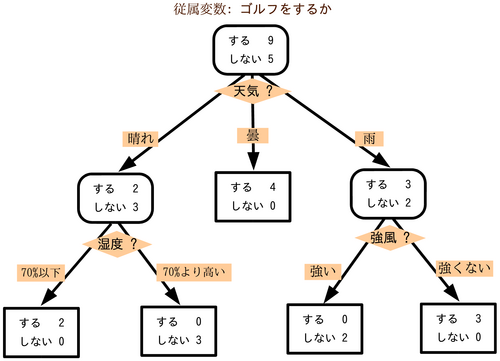
機械学習の分野において決定木は予測モデルであり、ある事項に対する観察結果から、その事項の目標値に関する結論を導く。内部の節点は変数に対応し、子である節点への枝はその変数の取り得る値を示す。 葉(端点)は、根(root)からの経路によって表される変数値に対して、目的変数の予測値を表す。
参照:https://ja.wikipedia.org/wiki/%E6%B1%BA%E5%AE%9A%E6%9C%A8
まあこれはタイタニックとかでよく使われているので普通に分かるので割愛。ジニ係数とかL1正則化の話はまた今度
決定木の問題点として良く上げられるのが、Overfitting(過学習)が起きやすい点。先人たちはこの問題を解決するために、色んな手法を編み出しました。それがこの記事で説明している「バギング」とか「勾配ブースティング」なわけです。
決定木の発展形
まず機械学習でモデルの精度を上げる方法としてまず挙げられる手法が「アンサンブル学習」というものです。
アンサンブル学習とは、複数の機械学習モデルを組み合わせることで、より強力なモデルを構築するやり方です。機械学習のモデルには「ロジスティック回帰」「SVM」「決定木」等たくさんありますが、これらはそれぞれ単独でデータに対して予測を行います。ただ、世間一般的にも、誰か1人の独断で答えを出すよりも、何人か集まって答えを導き出す、ある種の多数決がより良い結果を生むこともたくさんあると思います。アンサンブル学習とはまさにこの考え方で、複数の機械学習モデルの判断結果から多数決で、最終的に判断を下す学習の仕方です。
参照:https://qiita.com/Hawaii/items/5831e667723b66b46fba
要はエヴァで出てくるスーパーコンピューターのMAGIのように複数のモデルでそれぞれに結果を出して最終的にそれを多数決して目的変数を決める手法です。
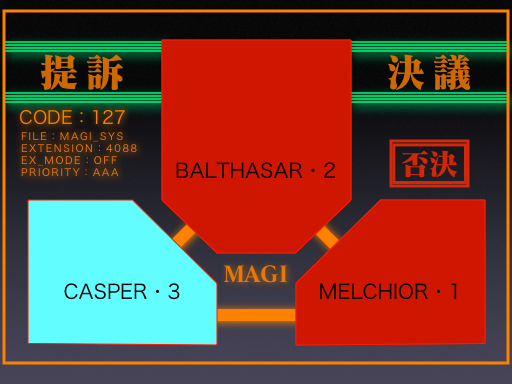
この「アンサンブル学習」の概念を決定木に応用すると、複数の決定木を作ってそれぞれが出した答えを多数決で最終的な目的変数を決めるということになります。
そして厳密に説明すると決定木における「アンサンブル学習」の手法は3つの手法に分類をすることが出来ます。これが「バギング」「ブースティング」「スタッキング」と呼ばれる手法です。
バギングとランダムフォレスト
バギングではブートストラップ手法を用いて学習データを復元抽出することによってデータセットに多様性を持たせています。復元抽出とは、一度抽出したサンプルが再び抽出の対象になるような抽出方法です。
要は同じデータをそのまま使うと全部の決定木が同じ答えになるので多様性を与えるため各決定木の説明変数データを元データからランダムに選ぶような工夫を加えます。そしてその際に以下のような条件を加えます。
・全部の説明変数を使わず、一部の説明変数しか使わない。
・決定木の深さ、つまり分岐(ノード)の数を制限する。
・決定木の剪定を最初から取り入れる。
これらの処置によって、たくさん作成される決定木にバリエーションが生まれ、似たような決定木が生まれにくくすることで決定木の短所であるOverfitting(過学習)を起きにくくしています。
そしてこのバギングによって複数の決定木モデルを作り、各決定木の多数決で目的変数を決めるアルゴリズムを一般的に「ランダムフォレスト」と言います
ランダムフォレストとは決定木にアンサンブル学習の概念を組み合わせたもので、バギング+アンサンブル学習=ランダムフォレスト、みたいな認識で良いと思う。
勾配ブースティングとXgboost
次に勾配ブースティングについて。まず先ほどのランダムフォレストは複数の決定木を一斉に計算してその結果から多数決を行い最終結果(目的変数Y)で決める仕組みでした。それに対して勾配ブースティング法は、前の決定木を計算した際の誤差を引き継いでいきます。
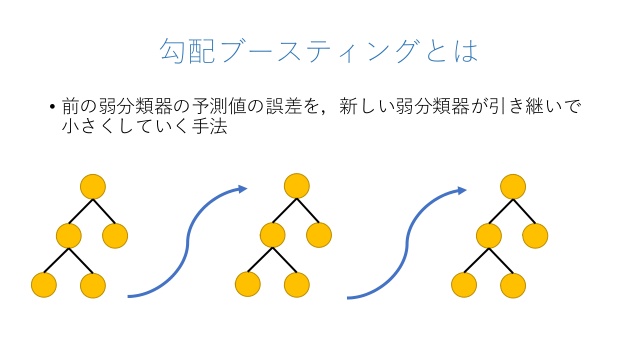
参照:https://logmi.jp/tech/articles/322734
これにより徐々に過学習的に訓練データにフィッティングしていき、最後にアンサンブル学習で最終結果を算出します。勾配ブースティングは過学習していないモデルも含めて全体の意思決定を行うためバイアスが低下すると言われています。
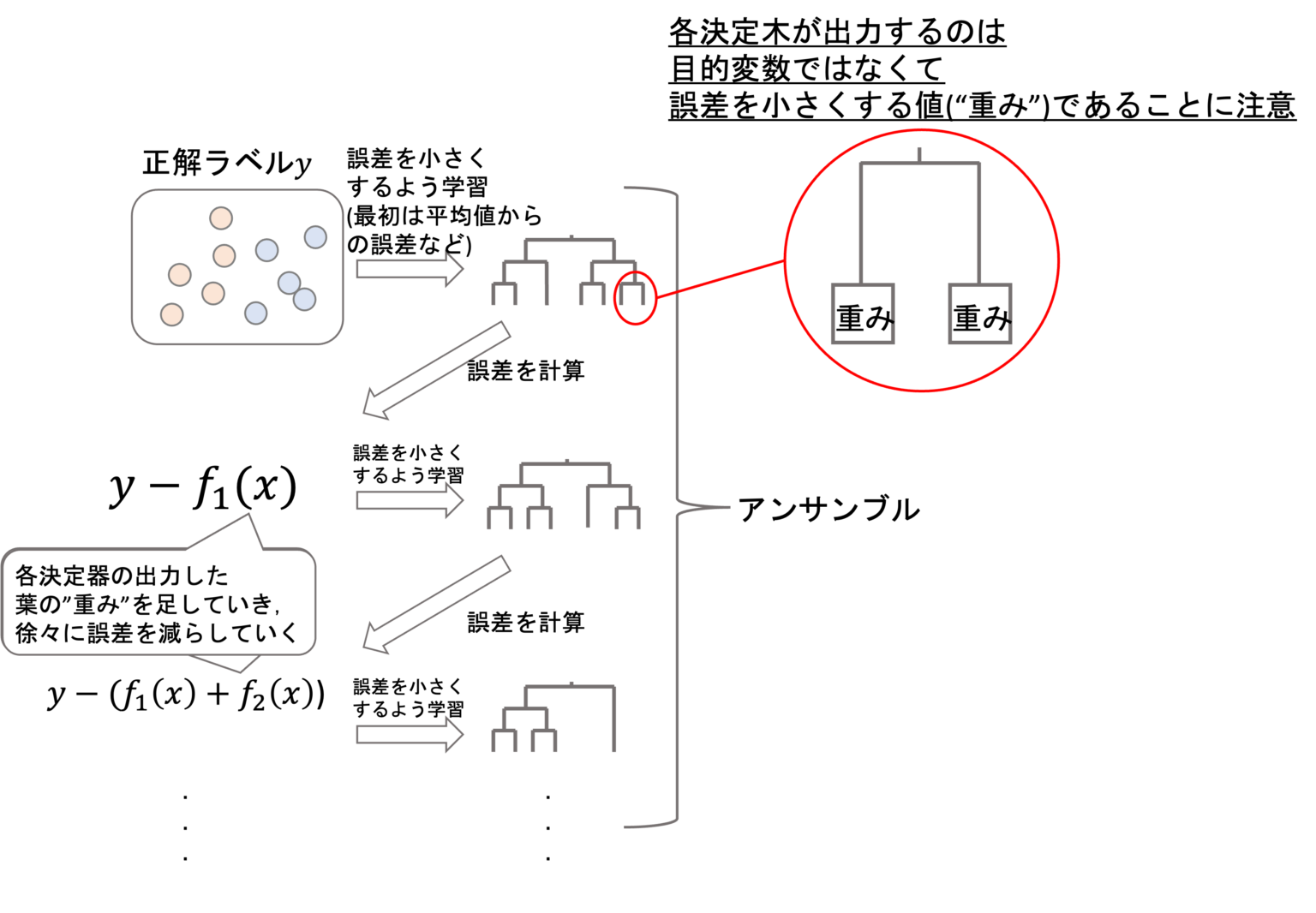
参照:https://datawokagaku.com/xgboost/
この勾配ブースティング決定木をアンサンブルで組み合わせる手法の代表的なアルゴリズムが「Xgboost」と呼ばれるアルゴリズムたちです。
勾配ブースティング木の種類
kaggleなどでよく使われる勾配ブースティング決定木は下記3種類です。
- XGBoost
- LightGBM
- Catboost
XGBoostは勾配ブースティング決定木の先駆けみたいなやつです。今は進化系がいっぱいあってあんまり使われていない印象ですが、kaggleのタイタニックで試してみると分かりますが通常の決定木・ランダムフォレストよりは良い精度が出やすいです。
LightGBMはXGBoostに似たアルゴリズムですが、XGBoostの問題点であった計算量の問題を改善しより高速で実施することが可能としたアルゴリズムです。
続いてcatboostは上記2つよりカテゴリカル変数(質的変数)の特徴をうまく捉えるようにしつつ、決定木のツリー構造を最適にして過学習を防ぐことでモデルの精度がより出やすいと言われています。
Pythonで実装するサンプルコードは以下参照:
・【Python】元最強アルゴリズム「XGBoost」で機械学習をやってみた
・【Python】「LightGBM」を使ってタイタニックの機械学習をやってみた
・【Python】「CATBoost」を使ってタイタニックの機械学習をやってみた
ランダムフォレストやXgboostのモデルの可視化について
ここまでの説明から分かるようにランダムフォレストやXgboostは複数の決定木を使った多数決で目的変数を見つける手法です。なので、内部の1つの決定木を可視化してもそれがモデル全体の構造ということにはなりません。なのでランダムフォレストやXgboostのモデルのサマライズを行う場合は変数重要度を用います。
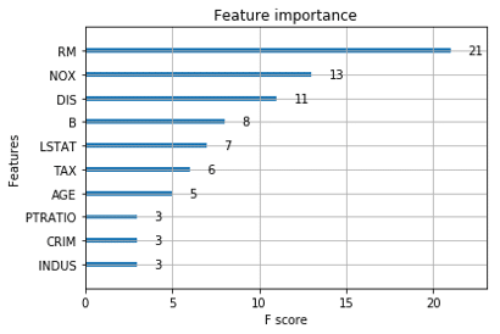
参照:https://data-analysis-stats.jp/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92/python%E3%81%A7xgboost/

コメント
[…] 関連記事:決定木とランダムフォレスト、バギングと勾配ブースティングの違いについてまとめた […]