
業務でクラスタリングした結果をプロットしてほしい、みたいな依頼を受けたのですが2次以上の多次元の配列データをk-meansでクラスタリングした結果ってどうやって可視化するんだっけ…?と少し悩んだのでメモしておきます。
データの準備&前処理
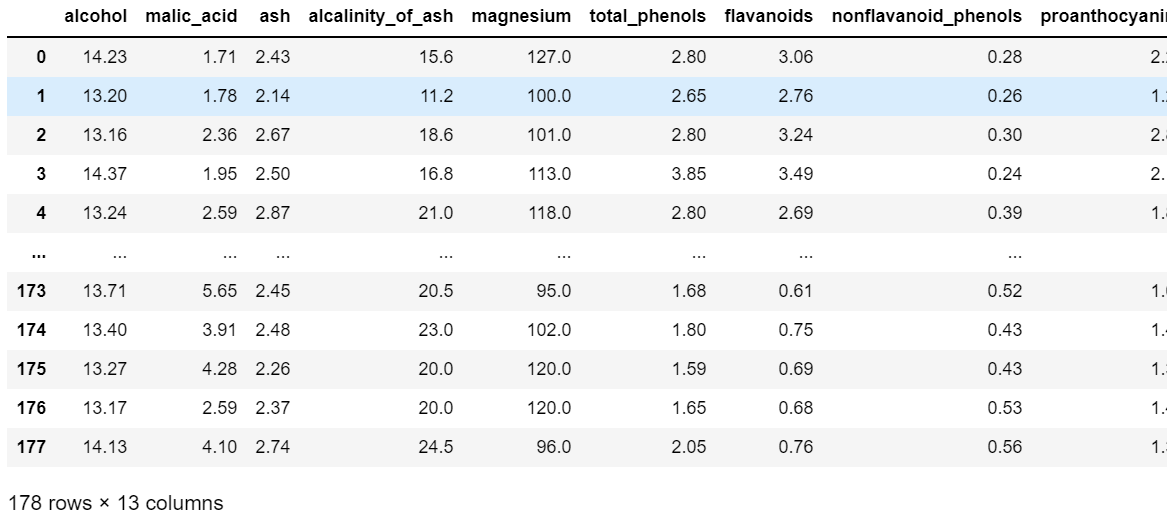
sk-learnにあるワインのデータを使います。
from matplotlib import pyplot as plt from sklearn import datasets, preprocessing import numpy as np import pandas as pd wine_data = datasets.load_wine() df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names) df
K-meansでクラスタリングを行う
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
sc = StandardScaler()
clustering_sc = sc.fit_transform(df)
# クラスタリング
kmeans = KMeans(n_clusters=5, random_state=0)
clusters = kmeans.fit(clustering_sc)
df['cluster'] = clusters.labels_
df.groupby('cluster').count().iloc[:,1]
<実行結果>
cluster 0 52 1 31 2 48 3 39 4 8
雑にクラスタリングしていますが、本来はエルボー法とかでクラスターのばらけ具合を見た方が良いです。
参照:【Python】pandas-datareaderでVIX(恐怖指数)をスクレイピングで取得する
これでクラスタリングできましたが、このままだとプロットすることは難しいです。
PCA(主成分分析)で次元を削減を行う
PCA(主成分分析)とはデータの特徴を損なうことなく、次元を削減する手法です。
参照:【Python】主成分分析(PCA)でのクラスタリングを実装する
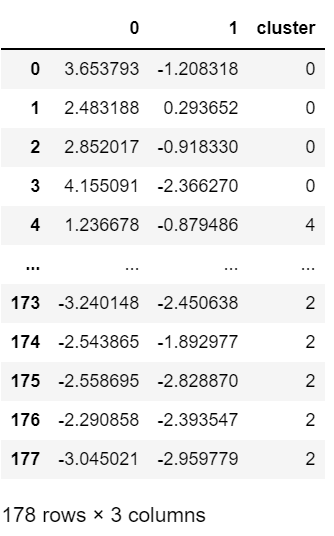
# PCAでデータを2次元に削減する from sklearn.decomposition import PCA x = clustering_sc pca = PCA(n_components=2) pca.fit(x) x_pca = pca.transform(x) pca_df = pd.DataFrame(x_pca) pca_df['cluster'] = df['cluster'].values pca_df
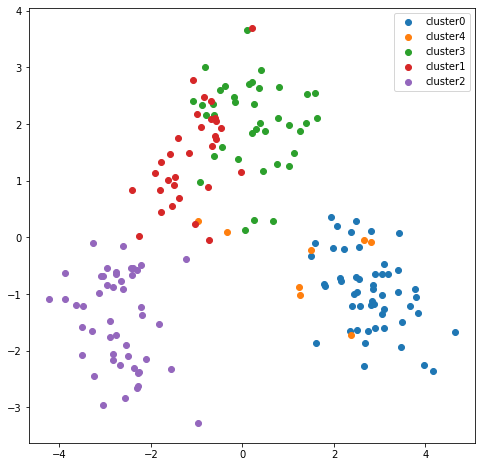
散布図をプロットする(2次元)
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure(figsize = (8, 8))
for i in pca_df['cluster'].unique():
tmp = pca_df.loc[pca_df['cluster'] == i]
plt.scatter(tmp[0], tmp[1], label=f'cluster{i}')
# 各要素にDataFrameのインデックスの数字をラベルとして付ける
plt.legend()
<実行結果>
散布図をプロットする(3次元)
ちなみに2次元の散布図で見るとクラスターが固まっている場合は3次元プロットで3D立体的に見ることで散らばり具合を確認できるケースもあります。
fig = plt.figure(figsize = (16, 16))
# PCAでデータを2次元に削減する
from sklearn.decomposition import PCA
x = clustering_sc
# 三次元なので次元圧縮後の次元数を3に指定する
pca = PCA(n_components=3)
pca.fit(x)
x_pca = pca.transform(x)
pca_df = pd.DataFrame(x_pca)
pca_df['cluster'] = df['cluster'].values
print(pca_df.head())
ax = fig.add_subplot(222, projection='3d')
# 視点角度を調整する
#ax.view_init(elev=30, azim=30)
color_list = ["orange","pink","blue","brown","red","grey","yellow","green", "darkblue", "c"]
for i in pca_df['cluster'].unique():
tmp = pca_df.loc[pca_df['cluster'] == i]
sc = ax.scatter(tmp[0], tmp[1], tmp[2], color=color_list[i])
三次元プロットのグラフの視点の方向はコメントアウトしている#ax.view_init(elev=30, azim=30)の部分の数値を弄ってもらえれば変更できます。
Matplotlibの3次元プロットしてグラフの視点や角度の変更について以下記事参照:
Python 3次元グラフのテーマカラー,グラフの表示角度を変更 – Qiita
<実行結果>
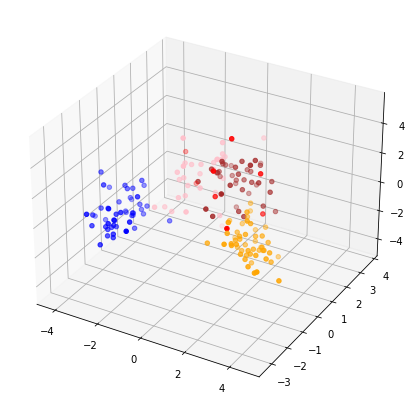
こんな感じでクライアントにクラスタリングした結果を見せられると向こう側の満足度も上がるかもしれません。
参考:https://qiita.com/MATU0055/items/121e21df5904af4d281e
参考:https://python.atelierkobato.com/axes3d/
参考:https://www.delftstack.com/ja/howto/matplotlib/set-color-for-scatterplot-in-matplotlib/
参考:https://chusotsu-program.com/scikit-learn-clustering-plot/

コメント
[…] 実装記事:【Python】K-MEANSでのクラスタリング結果を主成分分析で次元削減してグラフで可視化する […]