クライアントからもらったデータの検品する際にPandasを使用しますが、その際によく使う処理をメモ的にまとめてみました。よく前処理を行う人の参考になれば幸いです。
Contents
pandasの概要
pandasは、データの解析や加工に特化したPythonのライブラリです。主な機能として、表データの取り扱いや変換、集計、グラフ描画などがあります。
pandasのインストール
pandasを使うためには、まずはpandasをインストールする必要があります。以下のコマンドをコマンドプロンプトやターミナルで入力してください。
$ pip install pandas
これでインストールが完了します。
欠損値の個数を確認する
欠損値とは
欠損値とは、データの中に値が存在しない(欠けている)状態を指します。欠損値が含まれていると、データの分析や加工に支障をきたす場合があります。
pandasで欠損値を確認する
pandasではisnull()を使って、欠損値の有無を確認できます。例えば、以下のようにコードを書くことで、欠損値が含まれているかどうかを確認できます。
import pandas as pd
data = {"name":["A","B","C"],"age":[20,None,30]}
df = pd.DataFrame(data)
print(df.isnull())
出力結果:
name age
0 False False
1 False True
2 False False
このように、2行目に欠損値(True)が含まれていることが分かります。
df.isnull().sum()
出力結果:
name 0
age 1
dtype: int64
ユニークな要素数を確認する
重複とは
重複とは、複数のデータの中に同じ値が複数含まれている状態を指します。例えば、同じ名前や住所を持つ人が複数いる場合などが該当します。pandasでは以下のメソッドを用いることで重複を排除することができます。
pandasで重複を確認する
pandasでは、duplicated()を使って、重複が含まれるかどうかを確認できます。例えば、以下のようにコードを書くことで、重複が含まれているかどうかを確認できます。
import pandas as pd
data = {"name":["A","B","C","C"],"age":[20,30,25,40]}
df = pd.DataFrame(data)
print(df["name"].duplicated())
出力結果:
0 False
1 False
2 False
3 True
dtype: bool
このように、4行目に重複(True)が含まれていることが分かります。
個数を集計する場合は以下のように記述します
df["name"].duplicated().sum() # 1
上記のコードでは、duplicated()を使って重複かどうかを判定し、sum()で集計しています。
データのユニークな(重複がない)要素のみを取得する
pandas.Series.unique()は、pandasシリーズの中のメソッドの一つで、データのユニークな(重複がない)要素のみを取得することができます。
import pandas as pd series_data = pd.Series([1, 2, 2, 3, 4, 4, 4, 5]) unique_data = series_data.unique() print(unique_data)
上記のコードを実行すると、次のような出力が得られます。
[1 2 3 4 5]
上記の出力には、データの中にある重複している要素は含まれていません。つまり、unique()メソッドによってユニークな要素のみが抽出されたことが分かります。
要素の出現数をカウントする
pandasのSeriesオブジェクトに対して、それぞれの値が何回出現したかをカウントする関数です。戻り値は、値とその値が出現した回数を紐付けたpandas.Seriesオブジェクトです。以下は、使い方の例です。
import pandas as pd data = pd.Series([1, 2, 1, 3, 3, 3]) print(data.value_counts())
この場合、1は2回、2は1回、3は3回出現しているため、以下のようなSeriesオブジェクトが返されます。
出力結果:
3 3
1 2
2 1
dtype: int64
value_counts()はSeriesオブジェクトに対して呼び出すことができます。また、デフォルトでは出現回数の多い順にソートされますが、オプションでソート順を変更することもできます。以下は、その例です。
print(data.value_counts(ascending=True)) # ソート順を昇順に変更
この場合、出現回数の少ない順にソートされたSeriesオブジェクトが返されます。
ユニークな要素数を集計する
pandas.Series.nunique()は、pandasのSeriesオブジェクトからユニークな値の数を取得するための関数です。これを使うことで、Seriesオブジェクト内に含まれるユニークな値の数を簡単に抽出できます。
import pandas as pd # Seriesオブジェクトの作成 s = pd.Series(['apple', 'banana', 'apple', 'orange']) # ユニークな値の数を取得 n = s.nunique() # 結果を表示 print(n)
この場合、Seriesオブジェクトには、重複する値(apple)が含まれているため、ユニークな値の数は3となります。したがって、上記のコードを実行すると、以下のような結果が得られます。
3
また、pandas.Series.nunique()関数には、引数を指定することもできます。以下は、Seriesオブジェクトのうち、特定の条件を満たす要素のうちのユニークな値の数を取得する例です。この場合、引数に条件式を指定することで、条件を満たす要素のうちのユニークな値の数を取得しています。
import pandas as pd # Seriesオブジェクトの作成 s = pd.Series([10, 20, 30, 40, 50, 60]) # 条件式の作成 condition = s > 30 # ユニークな値の数を取得 n = s[condition].nunique() # 結果を表示 print(n)
この場合、引数で指定した条件式「s > 30」にマッチする要素は、40, 50, 60の3つです。したがって、このコードを実行すると、以下のような結果が得られます。
3
ユニークな要素にIDを付与する
また上記集計したユニークな要素に対して1,2,3,・・・のようなIDを付与することも可能です・
詳細は以下の記事で紹介しています
参考:pandasで特定列のユニークな値を数値IDに変換する方法
平均・中央値を集計する
平均
pandasを使って平均値を集計するには以下のように記述します
import pandas as pd data = [3, 4, 5, 6, 7] df = pd.DataFrame(data) # 平均値の計算 mean_value = df.mean() # 結果の表示 print(mean_value)
これで、以下のように平均値が求められます。
0 5.0 dtype: float64
結果の解説:
– 0はcolumnの名前
– 5.0は平均値
中央値
次に、中央値を求める方法について説明していきます。中央値とは、データを昇順または降順に並べたとき、真ん中に来る値のことです。
import pandas as pd data = [3, 4, 5, 6, 7] df = pd.DataFrame(data) # 中央値の計算 median_value = df.median() # 結果の表示 print(median_value)
これで、以下のように中央値が求められます。
0 5.0 dtype: float64
結果の解説:
– 0はcolumnの名前
– 5.0は中央値
GROUP BYで合計を集計する
Pythonのpandasには、groupbyという機能があります。この機能を使うと、データをグループに分けて集計することができます。例えば、ある商品の売り上げデータがあった場合、それを地域別に集計することができます。まずデータを定義します。ここでは、ある商品の売り上げデータを定義しています。
data = pd.DataFrame({
"region": ["East", "West", "East", "West", "East", "West", "East", "West"],
"sales": [1000, 1200, 800, 900, 1100, 1300, 700, 1000]
})
このデータは、地域別の売り上げデータを表しています。region列には地域名、sales列には売り上げ額が格納されています。では、これを地域別に集計してみましょう。groupbyを使って、まずは地域別にグループ化します。
grouped = data.groupby("region")
ここでは、region列を指定してgroupbyを実行しています。これにより、地域ごとにグループ化されたデータができあがります。次に、このグループ化されたデータを集計します。ここでは、売り上げ額の合計を求めてみましょう。
result = grouped.sum()
これで、地域別の売り上げ額の合計が求まりました。実行結果は以下のようになります。
sales
region
East 3600
West 3400
これを解説すると、East地域の売り上げ額は3600、West地域の売り上げ額は3400ということです。なお、groupbyには、複数の列を指定することもできます。例えば、地域別・年別にグループ化して集計する場合は、以下のようになります。
grouped = data.groupby(["region", "sales"]) grouped.sum()
<実行結果>
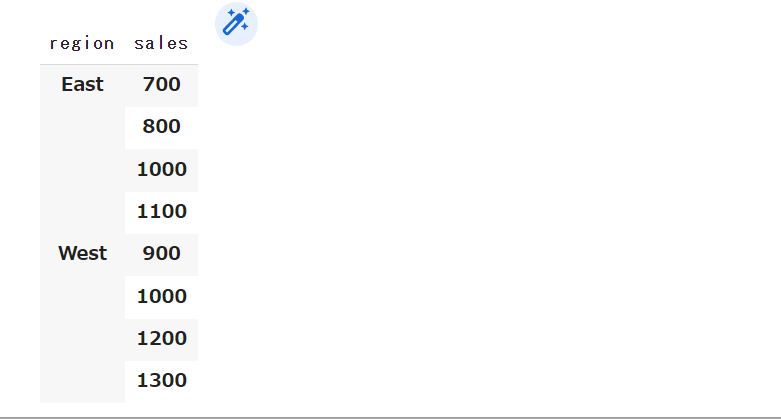
関連記事:【Python】pandasのgroupbyで日ごとの数値データを集計する
特定の条件に合致したデータを抽出する
関連記事:Pandasで条件に一致したデータを検索・抽出するサンプルコード
終わり~オススメ参考書籍
これらのコードが以下の参考書で紹介されているものをアレンジしたものになります。


コメント