決定木は、その透明性と解釈の容易さから、機械学習において広く使用されています。この記事では、scikit-learnを使用して構築した決定木モデルの各ノードで用いられる特徴量、閾値、およびクラス別の人数を分析する方法を紹介します。
決定木モデルのトレーニング
まず、scikit-learnの DecisionTreeClassifier を使用して、典型的な分類問題であるIrisデータセットを使って決定木モデルをトレーニングします。
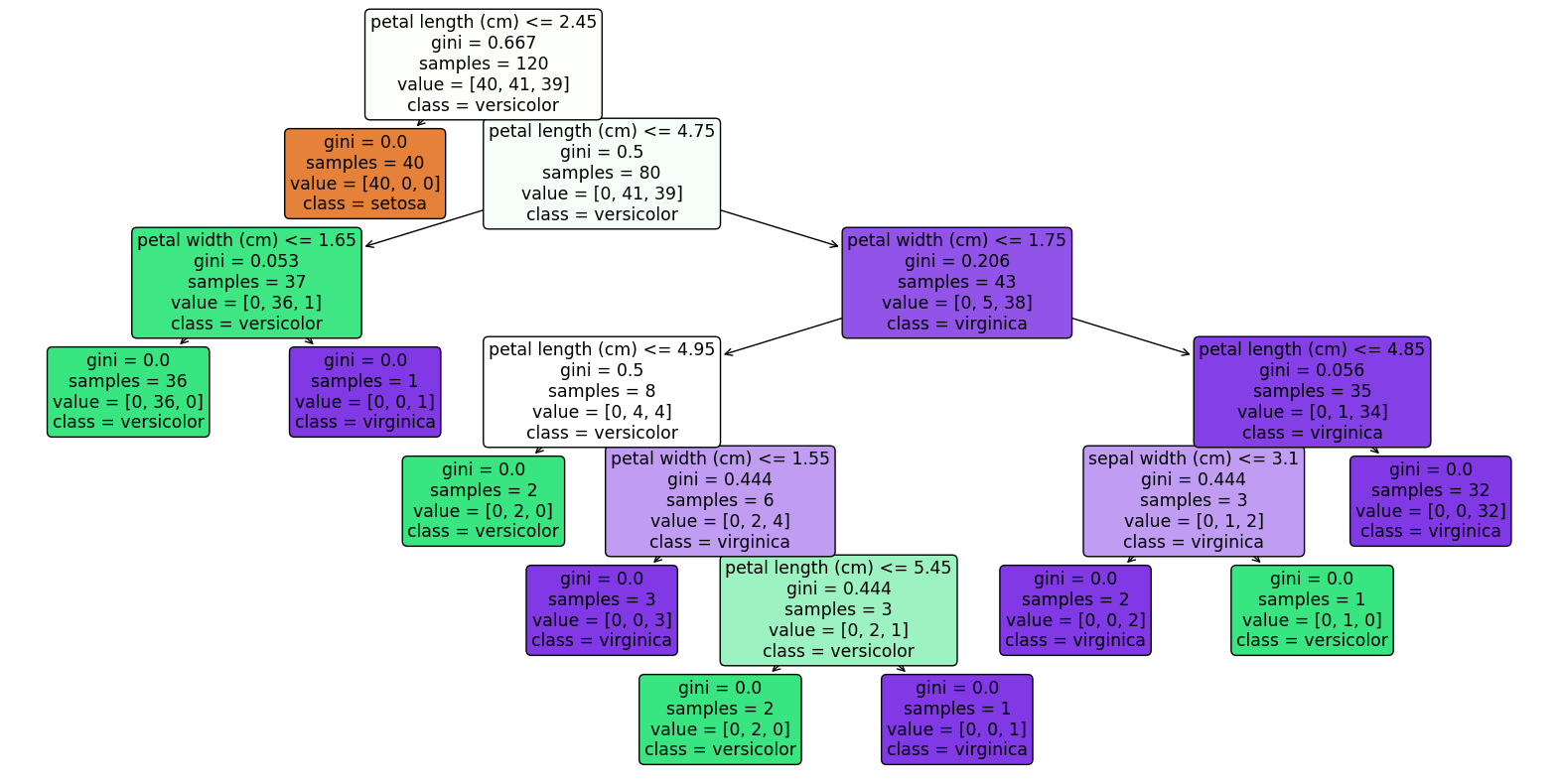
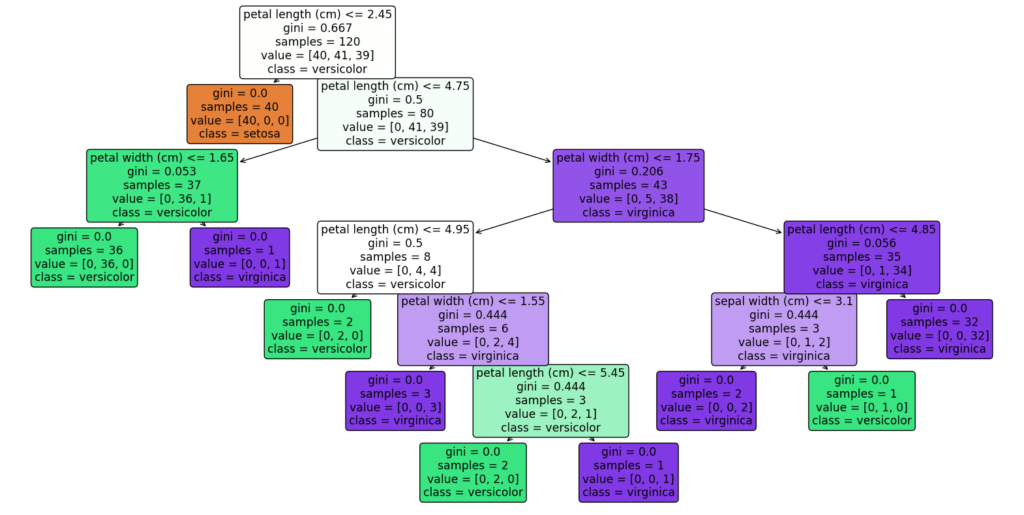
import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier, plot_tree from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import pandas as pd # サンプルデータセットのロード(ここではIrisデータセットを使用) data = load_iris() # 説明変数と目的変数をデータフレームにする X = pd.DataFrame(data.data,columns=data.feature_names) y = pd.DataFrame(data.target) # データを訓練セットとテストセットに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 決定木モデルのトレーニング clf = DecisionTreeClassifier(random_state=42) clf.fit(X_train, y_train) # 決定木のプロット plt.figure(figsize=(20,10)) plot_tree(clf, filled=True, feature_names=X.columns, class_names=['setosa', 'versicolor', 'virginica'], rounded=True, proportion=True) plt.show()
<実行結果>
ノード数とクラス数を取得する
クラス数は決定木モデルの classes_ 属性から取得することができます。
n_nodes = clf.tree_.node_count
n_classes = len(clf.classes_)
print(f"Number of nodes: {n_nodes}")
print(f"Number of classes: {n_classes}")
<実行結果>
Number of nodes: 19
Number of classes: 3
各決定木のノード情報を取得する
決定木モデルがトレーニングされた後、モデルの tree_ 属性からノードに関する情報を取得します。これには、ノード数、各ノードでの分割に用いられる特徴量、分割の閾値、および各ノードでのクラス別の人数が含まれます。
モデルの各ノードに対して、以下の情報を表示します。
特徴量と閾値: 各ノードでの分割判断に使用される特徴量とその閾値。
クラス別人数: そのノードに到達した各クラスのサンプル数。
# 決定木のノード情報を取得
n_nodes = clf.tree_.node_count
children_left = clf.tree_.children_left
children_right = clf.tree_.children_right
feature = clf.tree_.feature
threshold = clf.tree_.threshold
node_values = clf.tree_.value
# 各ノードの情報を表示
for i in range(n_nodes):
if children_left[i] != children_right[i]: # 子ノードがある場合
print(f"ノード {i} - 特徴量: {data.feature_names[feature[i]]}, 閾値: {threshold[i]:.2f}")
else:
print(f"ノード {i} - 葉ノード")
print(f"クラス別人数: {node_values[i]}")
n_nodes はツリー内のノードの総数を表します。
children_left と children_right は、それぞれ各ノードの左右の子ノードのインデックスを保持します。
feature と threshold は、各ノードでの分割に用いられる特徴量のインデックスとその閾値を示します。
node_values は、各ノードでのクラス別のサンプル数を示します。
<実行結果>
ノード 0 – 特徴量: petal length (cm), 閾値: 2.45
クラス別人数: [[40. 41. 39.]]
ノード 1 – 葉ノード
クラス別人数: [[40. 0. 0.]]
ノード 2 – 特徴量: petal length (cm), 閾値: 4.75
クラス別人数: [[ 0. 41. 39.]]
ノード 3 – 特徴量: petal width (cm), 閾値: 1.65
クラス別人数: [[ 0. 36. 1.]]
ノード 4 – 葉ノード
クラス別人数: [[ 0. 36. 0.]]
ノード 5 – 葉ノード
クラス別人数: [[0. 0. 1.]]
ノード 6 – 特徴量: petal width (cm), 閾値: 1.75
クラス別人数: [[ 0. 5. 38.]]
ノード 7 – 特徴量: petal length (cm), 閾値: 4.95
クラス別人数: [[0. 4. 4.]]
ノード 8 – 葉ノード
クラス別人数: [[0. 2. 0.]]
ノード 9 – 特徴量: petal width (cm), 閾値: 1.55
クラス別人数: [[0. 2. 4.]]
ノード 10 – 葉ノード
クラス別人数: [[0. 0. 3.]]
ノード 11 – 特徴量: petal length (cm), 閾値: 5.45
クラス別人数: [[0. 2. 1.]]
ノード 12 – 葉ノード
クラス別人数: [[0. 2. 0.]]
ノード 13 – 葉ノード
クラス別人数: [[0. 0. 1.]]
ノード 14 – 特徴量: petal length (cm), 閾値: 4.85
クラス別人数: [[ 0. 1. 34.]]
ノード 15 – 特徴量: sepal width (cm), 閾値: 3.10
クラス別人数: [[0. 1. 2.]]
ノード 16 – 葉ノード
クラス別人数: [[0. 0. 2.]]
ノード 17 – 葉ノード
クラス別人数: [[0. 1. 0.]]
ノード 18 – 葉ノード
クラス別人数: [[ 0. 0. 32.]]
決定木のノード情報をCSVに出力する
# ノード情報をデータフレームに保存
node_info = []
for i in range(n_nodes):
# 葉ノードかどうか
is_leaf = children_left[i] == children_right[i]
# ノード情報
node_data = {
'node_id': i,
'is_leaf': is_leaf,
'feature': data.feature_names[feature[i]] if not is_leaf else None,
'threshold': threshold[i] if not is_leaf else None,
'class_distribution': node_values[i]
}
node_info.append(node_data)
df_nodes = pd.DataFrame(node_info)
# CSVファイルに保存
df_nodes.to_csv('tree_node_info.csv', index=False)
まとめ
この方法により、決定木の各ノードでのデータの流れと分類の決定基準を詳細に理解することができます。これは、モデルの解釈性を高め、データの洞察を深めるのに非常に役立ちます。

コメント
[…] 関連記事:Scikit-learnで作った決定木から閾値とノード数・クラス数などを取得する […]