前回、kerasを使ったディープラーニングよる画像認識をやってみたのに続いて、今回はそれより少し高度な畳み込みニューラルネットワークを使った画像認識を行っていきたいと思います。
畳み込みニューラルネットワークとは?


分かっているという方はスルーしてもらって全然構いません。畳み込みディープラーニング(CNN)とは、簡単に言うと通常のニューラルネットワークの中間層での処理を少し変えたものです。中間層で特徴的な部分をピックアップして学習し、データの特徴をより効率よく学習させることで学習精度を向上させるという仕組みです。特に画像認識などの場合は従来のモデルより畳み込みニューラルネットワーク予測精度が良いらしいです。なので改良版と言えるでしょう。ちなみに株価などのデータの順番に意味がある時系列データでは、リカレントネットワーク(RNN/LSTM)を使うのが良いと言われています。
具体的には普通のニューラルネットワークだと、隠れ層(中間層)の計算を行う場合前の層から出力された数値データに重みを掛ける(orドロップアウト・バッチノーマリゼーション)というデータ処理になりますが、畳み込みニューラルネットワークでは、中間層にその名の通り畳み込み層とプーリング層が設定されているのが特徴です。
畳み込みとは要するに何をやっているのかと言われるとひとえに説明するのが難しいため↓のようなイメージで押さえておいてください。簡単にいうと画像全体を見るのではなく、認識のもとになる特徴的な部分だけを計算するという手法です。そのため畳み込み層は入力データを3次元のデータにする必要があり、中間層が非結合なので、出力層に伝播させる前に全結合させる必要があります。
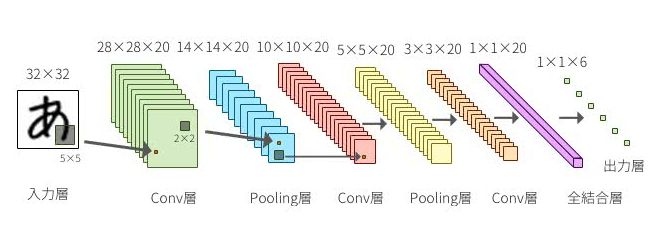
引用:https://deepage.net/deep_learning/2016/11/07/convolutional_neural_network.html
kerasとデータセットの準備
使うデータは前回と同じでモデルの中身が違うだけで使うデータ自体の中身と前処理の方法は少し違います。というのも上でチラッと触れましたが、畳み込みニューラルネットワークを実装する際は入力層に入力するデータは3次元のデータでないといけません。つまり、縦・横に加えて奥行きが必要になるため、numpyでのデータの前処理も前回と少し異なります。
# ライブラリのインポート import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras import optimizers import matplotlib.pyplot as plt import numpy as np from keras.models import Sequential, model_from_json from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K %matplotlib inline
前回と違うのは、Flatten Conv2D, MaxPooling2Dをインポートしている点です。Flattenは全結合層を定義する関数で、Conv2D・MaxPoolingは畳み込み層・プーリング層をkerasで実装する関数です。
使うデータセットは前回と同じMNISTを使います。
##データセットを読み込む
(x_train, y_train), (x_test, y_test) = mnist.load_data()
## 2次元データを1次元データに変換
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
前回はデータセットを2次元から1次元配列にしましたが今回は3次元にします。
# 畳み込みニューラルネットワークに使用するためにデータを変形する x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
実行した念のため、>>>x_test.shapeでデータがちゃんと整形出来ているか確認します。(60000,28,28,1)と返ってくればデータがちゃんと整形出来ているということになります。そして、yの方の正解データをコンピューターが認識できる形に変換します。↓
##ベクトルからone hotに変換する y_train = keras.utils.to_categorical(y_train,10) y_test = keras.utils.to_categorical(y_test,10)
これでデータの前処理は終了です。畳み込みの場合は入力データを3次元データにする点と出力層の前に全結合層を置く必要があるということを抑えておいてください。この2点が普通のディープラーニングやリカレント系のモデルと大きく違う点です。
畳み込みディープラーニングのモデルを構築する
モデルの構築自体は前回のニューラルネットワークと変わりません。ただ上述したように中間層に畳み込み層とプーリング層があるため、前回とは設定が少し異なります。ちなみにkerasでの畳み込み層の表現はConv2Dという関数で簡単に表現することができます。ちなみにConvはConvolutiona:畳み込むというところから来ています。またプーリング層はMaxPoolingという関数で定義できます。
##インスタンスを作成する model = Sequential()
プーリング層は通常畳込み層の直後に設置されます。プーリング層は畳み込み層で抽出された特徴の位置感度を若干低下させることで対象とする特徴量の画像内での位置が若干変化した場合でもプーリング層の出力が普遍になるようにします。
まずは入力層を定義していきます。ここでは3次元で入力されたデータを畳み込んで次の層に流すという作業を行っています。。
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=(28,28,1)))
入力される手書き文字の画像データは前のところで整形したように(28,28,1)の3次元データです。そして、Conv2Dで畳み込み層と定義し、次の引数で出力は32次元と定義し、フィルターサイズ:(3,3)の畳み込みこんでReLU関数の活性化層に流すということを表現しています。
# (2,2)のマックスプーリング層を追加する model.add(MaxPooling2D(pool_size=(2, 2)))
そして次はプーリング層を設定していきます。このプーリングはニューラルネットワークの性能を向上させるテクニックの1つでドロップアウト・バッチノーマライゼーションみたいな小技の一種と捉えておいてください。
プーリングとは何をするものなのか簡単に説明すると、送られてきた情報の中から無駄な情報を削減し、より学習効率を高めるという処理をしています。簡単な例だと、もし前の層からプーリング層に6×6の36マスの行列データを送られてきた場合それを2×2ごとに分割、つまり9等分に分割します。
そして分割した9個の2×2の行列の中から最大値を1つずつ選択し、3×3の9個の数値を格納した行列を作成します。この一連の処理がプーリング層で行われています。畳み込みニューラルネットワークでは畳み込んだ後、プーリングをしないと意味がないので、畳み込んだらプーリング処理を付け足すのを忘れないようにしましょう。
全結合層と出力層の作成
畳み込みニューラルネットワークの場合、ネットワークを伝播するデータは3×3みたいな2次元であるため、出力層に流す前の段階でデータを1つの数値だけ、つまり1次元に変換しなおす必要があります。これはKerasだとFlatten()という関数を使うことで簡単に変換できます。
##入力データを1次元にする model.add(Flatten())
また畳み込み層はノードからノードに全て結合するのが全結合を計算すると処理が膨大になってしまうので、非全結合で処理しています。なので出力層に流す前に一旦全結合させます。
# 出力:128次元の全結合層とReLU層を追加 model.add(Dense(128, activation='relu'))
そして、最後は前と同じく0~9に分類する10次元の出力層とソフトマックス関数層を定義します。
# 10次元のの全結合層とsoftmax層を追加 model.add(Dense(10, activation='softmax'))
まとめると↓のようなモデルになっています。
##モデルを定義する model = Sequential() ##Conv②Dで2次元レイヤーを表現する model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=(28,28,1))) # (2,2)のマックスプーリング層を追加 model.add(MaxPooling2D(pool_size=(2, 2))) # 20%をドロップするDropOut層を追加 model.add(Dropout(0.2)) # データを1次元にする model.add(Flatten()) # 出力:128次元の全結合層とReLU層を追加 model.add(Dense(128, activation='relu')) # 30%をドロップするDropOut層を追加 model.add(Dropout(0.3)) #0~9の10次元の出力層とsoftmax層を追加 model.add(Dense(10, activation='softmax'))
モデルができたので次は上で畳み込みニューラルネットワーク用に整形したデータをモデルに当てはめてみます。まずは前回と同じように学習のルールを決めます。分類なので誤差の計算はクロスエントロピーにし誤差の最適化計算は確率勾配降下法を採用、学習率はとりあえず0.01にしておき、モデルの精度の目安は正確率(accuracy)にします。
##学習の基本設定 model.compile(loss=keras.losses.categorical_crossentropy, optimizer=optimizers.SGD(lr=0.01), metrics=['accuracy'])
その次も前回と同じです。model.fitの処理の記録をresultという変数に格納することで、学習の過程(正解率と誤差の推移)がグラフなりで確認することができるようになります。
##モデルにデータを当てはめて学習させる result = model.fit(x_train,y_train, batch_size=128, epochs=20,verbose=1, validation_data=(x_test,y_test)) score = model.evaluate(x_test, y_test, verbose=0)
以下のコードを実行すると学習が始まるので、終わるまでコーヒーでも飲みながら待ちましょう。そして、学習が終わったらscoreに格納されている学習結果を確認します。
>>score [0.05055500229382887, 0.9822]
正解率は98.2%と前回の単純にディープラーニングした時より少し上昇しましたね。まあ畳み込みといえども今回は層の数が少ないので、こんなところでしょう。(一応上のモデルにもう一個畳み込み層とプーリング層とドロップアウト層を追加したところ99.8%まで上昇しました。)ディープラーニング/ニューラルネットワークはなんかよくわかんねぇけどモデルの中身変えたら精度が良くなったという現象が起こる魔境です。
終わり
以上がkerasによる畳み込みニューラルネットワークの実装方法です。ニューラルネットワークにおける中間層の畳み込みの方法には、他にもゼロパティングや範囲を広げて畳み込むストライドといったものがあります。他にも畳み込み処理やプーリング層での処理や、実装におけるパラメーターの設定などは、PythonとKerasによるディープラーニングという本に纏まっています。初心者向けの参考書ではありませんが、基礎を一通り抑えてからスキルアップしたという人に必読の一冊だと思います。

そして、これをより高度にしたのがリカレントネットワーク(RNN・LSTM)といったもので、畳み込みは画像認識などで高い効果を発揮しますが、株価や会話データなど時系列要素があるデータはリカレントネットワークを使って分析されることが多いです。



コメント
[…] ミナピピンの研究室 1 user 1 pocket【Python】Kerasを使って畳み込みニューラルネットワーク(CNN)による画像認識をや…https://tkstock.site/2018/08/24/post-674/ 前回、kerasを […]