
こんにちは、ミナピピン(@python_mllover)です。今回はCHAIDという決定木のアルゴリズムを使って決定木分析をやってみたので、その過程で詰まった点とかをメモっておきます。
Scikit-learnの決定木
Scikit-learnの関数で用意されている決定木はノードの分類ロジックとして、「CART」というアルゴリズムが採用されていますが、これらは分岐が単純であり、かつ過学習が起きやすいアルゴリズムです。
scikit-learnの決定木のロジックの細かい話は以下の記事が分かりやすいです。
参照:https://qiita.com/renesisu727/items/844648d6c60e578ce944
一方実際のデータ分析の実務だとkaggleのコンペなどのように0.01%でも高い予測精度を出すより、説明変数と目的変数の間にある要因分析を特定したい、みたいなケースの方が多く要因をデータ分析にあまり詳しく人が見ても分かりやすく可視化できる決定木が重宝されます。
そんなときにscikit-learnのデフォルトのアルゴリズムであるCARTなどを使っても結果で出力される決定木のノードが細分化されてしまい解釈が難しくなるため、結果を大まかに分類してくれるCHAIDを使った方が良いケースがあります。
ただ問題点としてはCHAIDのアルゴリズムはPythonの機械学習ライブラリであるscikit-learnには実装されておらず、今回の記事で解説していますが少し手間が掛かります。(SPSSやRを使える人はそれらで実装する方が手間が掛からないと思います)
PythonでCHAIDを実装する
というわけでいよいよCHAIDの決定木をPythonで実装してみましょう。前述したようにCHAIDのアルゴリズムはscikit-learnに含まれていないので、別のライブラリを使用します。
使用するデータ:https://github.com/beginerSE/titanic_sample
データの中身はkaggleのタイタニックのデータを欠損値を加工したものです。ダウンロードして適当な場所に配置してください。次に以下のライブラリをインストールします。
# ライブラリをインストール $ pip install CHAID, graphviz $ conda install orca
ここでインストールしているgraphvizとorcaは決定木を可視化するのに使用します。orcaはpipじゃなくてcondaコマンド推奨です。またgraphvizもインストールが少し厄介なライブラリで、rootにpathを通さないとエラーを吐くので注意してください。
参照記事:【Python】Window10でGaraphVizがインポートできないエラーの対処法
ANACONDAの環境構築に始まり、Pythonのモジュールエラーは大抵PATH絡みなので環境変数へのPathの通し方は知っておいて損はないと思います。
PythonでのCHAIDの決定木を実装するコードは以下になります。
from CHAID import Tree, NominalColumn
import plotly, os
import numpy as np
import pandas as pd
import orca
# データの読み込み
train = pd.read_csv('titanic_train_mod.csv')
df = train[["Pclass", "Sex", "Age", "Fare"]]
df.columns = ["Pclass", "Sex", "Age", "Fare"]
df['Survived'] = train['Survived']
independent_variable_columns = ["Pclass", "Sex", "Age", "Fare"]
dep_variable = 'Survived'
tree = Tree.from_pandas_df(df, dict(zip(independent_variable_columns, ['nominal'] * 3)), dep_variable, dep_variable_type='continuous')
tree.render(path='test.gv',view=True)
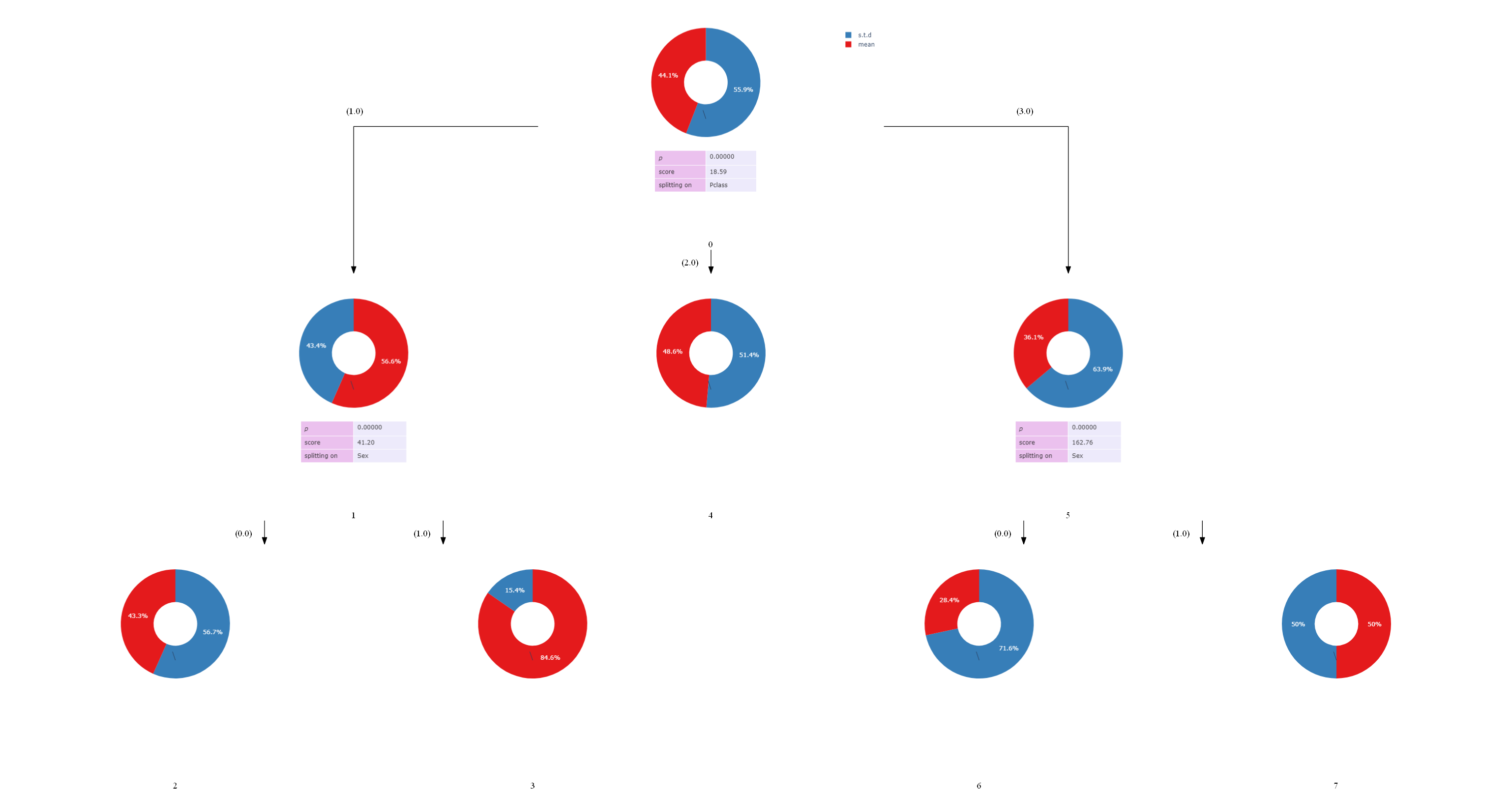
細かい部分は公式ドキュメントを参照してください。tree.render()の引数はview=Trueにすることで出力結果が画像として表示されます。Falseに変えるとディレクトリに出力されるだけになります。
ちなみにファイル名はpath=の部分で決めないと向こうが自動で決めるのですが、datetimeの時刻をそのままファイル名にしようとしているらしく内部でInvalid argumentを起こすので、ディレクトリだけでなくファイル名まで指定してあげましょう。(ここで2時間くらいハマりました笑)
そして、実行結果はこんな感じ↓、うーんSPSSとちょっと見せ方が違う。。。引数とかを弄れば変わるのかもしれないが如何せん情報がほぼ公式ドキュメントしかないので、ちょっと手間が掛かりそう。SPSSで分析したときの結果の違いと合わせて、気が向いたらまた調べるかもってところですね。まあとりあえずはSPSSでよさげ、SPSSがない会社の人は重宝しそうってところですかね?


コメント