
Rで使えるサンプルデータを準備する
まずfor文でデータ処理に使うサンプルデータを用意するわけですが、Rはデフォルトで呼び出せるデータセットが存在しています。サンプルデータの一覧は以下にあります.
チラッと見てみると,経済学,薬学,医学,生物学,天文学など……多くの分野で使われそうなサンプルデータが沢山あるので便利ですね。実務に使う感じのデータセットも多く、実践的なデータが揃っておりまさにデータ分析に特化したプログラミング言語だと言えます。まあ今回は適当にPythonの機械学習でもお馴染みのアヤメのデータを使ってみます。
#データセットをデータフレームにして読み込ませる
> iris
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
…
…
149 6.2 3.4 5.4 2.3 virginica
150 5.9 3.0 5.1 1.8 virginica
これで処理に使うデータセットは準備できたので、次は実際にfor文を使ってこのデータセットの中から欲しいデータを抽出していきます。
データフレームの基本的な操作
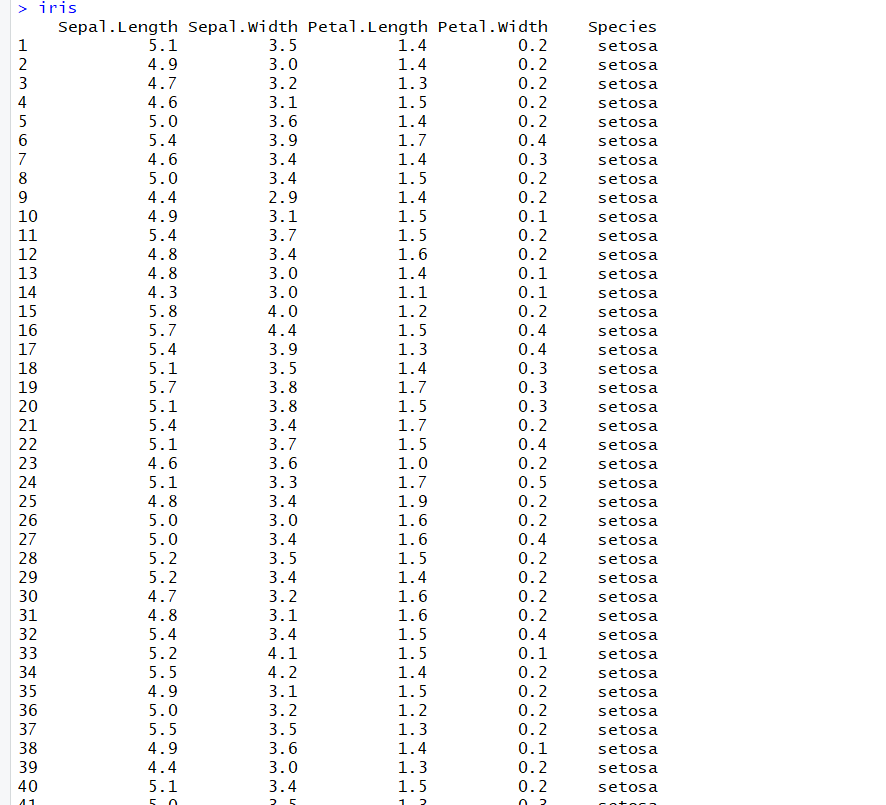
このデータフレームから横一列のデータを抽出したい場合、Rなら以下のように記述します。
> iris[1,] Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa > iris[2,] Sepal.Length Sepal.Width Petal.Length Petal.Width Species 2 4.9 3 1.4 0.2 setosa
これで横一列のアヤメ1つずつの特徴をまとめたデータが取得できます。そして、加えてその後ろに[]を付けることで横一列のデータの中から特定の場所の数値だけを抽出することも可能です。
> iris[1,][1] Sepal.Length 1 5.1 > iris[1,][2] Sepal.Width 1 3.5
データフレームをfor文で処理する
for文の使い方としてはまず「空のリストをあらかじめ作り、そこにfor文で処理した結果を加えていくという形が基本」です。Rなら空のリストは「list()」で作成することができます。
#空のリストを作る
sample=list()
そして、データフレームの処理でfor文を使いこなすためにはまずfor文の仕組みを知っておかなければいけません。for文の仕組みは「指定したリストの値を1つずつ変数「i」に代入しつつ、指定された処理を繰り返し実行する」というものです。
よく入門書の例題にあるfor(1:10)みたいなfor文は同じ処理を10回繰り返すという意味ではなく、1から10までの数字が格納されたリストの中から1つずつデータを取り出して「i」に代入しているにすぎません。
#print('helloWORLD!'を10回繰り返す
> for(i in 1:5){print('helloWORLD!')}
[1] "helloWORLD!"
[1] "helloWORLD!"
[1] "helloWORLD!"
[1] "helloWORLD!"
[1] "helloWORLD!"
試しにここに「i」の中身をprint()で表示させる処理を加えてみるとこんな感じの実行結果になります。
> for(i in 1:5){
+ print('helloWORLD!')
+ print(i)
+ }
[1] "helloWORLD!"
[1] 1
[1] "helloWORLD!"
[1] 2
[1] "helloWORLD!"
[1] 3
[1] "helloWORLD!"
[1] 4
[1] "helloWORLD!"
[1] 5
これが分かっていればデータフレームの処理にもfor文を簡単に応用することができるようになります。for文の使い方は状況によって多岐に渡りますがデータ分析という点でよく使うのは条件に一致するデータの抽出するという処理でしょう。
まずよくある処理の一例として、さっきのアヤメのデータフレームの中からSepal.Widthが3.5以上の個体のデータだけ抜き出すという処理をfor文を使って実行してみます。
アヤメのSepal.Width は「iris[1,][2]」という風に記述することで抜き出すことができました。これをiris[150,][2]まで繰り返してその中から3.5以上のアヤメの個体データが欲しいわけです。
なのでfor文の繰り返す範囲はfor(i in 1:150)にして「i」を順番に代入していく部分はiris[]の部分になりますので、iris[i,]とします。
for(i in 1:150){iris[i,][2]}
そして、iris[i,][2]の値が3.5以上であれば、あらかじめ作った空のリストに加えるという処理を行います。そのためにはSepal.Widthの値が3.5以上なら加える、3.5未満なら加えないという条件ごとに異なる処理を行う必要があります。そんなときに使えるのがif文です。if文の仕組みは「if~の条件式がTrueだった場合続きの処理を実行する」というものです
条件式というのは「x<5」みたいな不等号みたいな記号であらわされた式です。この式を実行すると正しかった場合は「True」間違っていたら「False」が返されます。
例えば
x=5
x<10
[1] TRUE
x<3
[1] FALSE
この条件式が「TRUE」だった場合に続きの処理を実行するのがif文の仕組みです。なので、Sepal.Widthの値が3.5以上ならその列の値をリストに加えたい場合は以下のように書きます。
sw=iris[i,][2]
if(sw>3.5){paste(sample,list(sw))}
このif文とfor文を組み合わせると以下のようになります。
for(i in 1:150){
+ sw=iris[i,2]
+ if(sw>3.5){sample<-append(sample,iris[i,])}
+ }
> sample
終わり
以上が基本的なfor文によるデータフレームのデータ処理方法です。ただRの場合はスクリプト言語なのでfor文が遅いため、データ処理をfor文で行うのはあまり得策ではありません。基本的にはRでのデータフレームの処理はdplyrを使って行列として処理するのが一般的です。
ただプログラミングの基本あくまでif文とfor文なので、データ処理の基本はこういうものだということは知っておくべきです。自分がそうだったのですが、dplyrなどを使って手早く処理する手法はこういうfor文の基本ができてから始めないと何も身に付かないのでちゃんと押さえておきましょう。

コメント