
Pythonで文字画像の文字をテキストに書き起こす
前準備
#pyocrのインストール pip install pyocr
次にOCRを行う「tesseract」のインストール。「Home · tesseract-ocr/tesseract Wiki · GitHub」のwindowsの箇所にある「Tesseract at UB Mannheim」のリンクから、自分の環境にあったインストーラーの実行ファイルをダウンロードします。
自分の場合はWindows10で「tesseract-ocr-setup-3.05.02-20180621.exe」をダウンロードインストールしました。Tesseractは最新バージョンは4.0ですが、個人的には3.0系のものの方がいいと思います。というのも自分の場合は4.0をインストールすると、「(3221225477, b”) TesseractError」という原因不明のエラーが発生したからです。
なので後述するパス設定もちゃんとしてるのに、pyocrがTesseractが呼び出せないというエラーが起こった場合はver3.0のモノをインストールするというのも対応策の1つだと思います
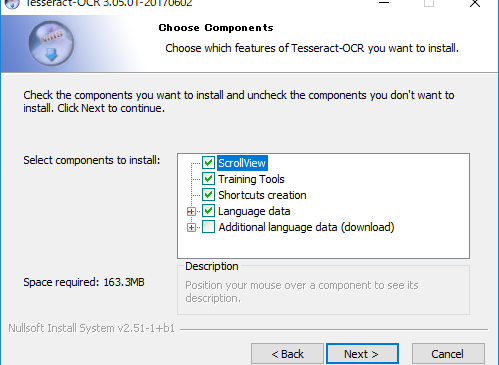
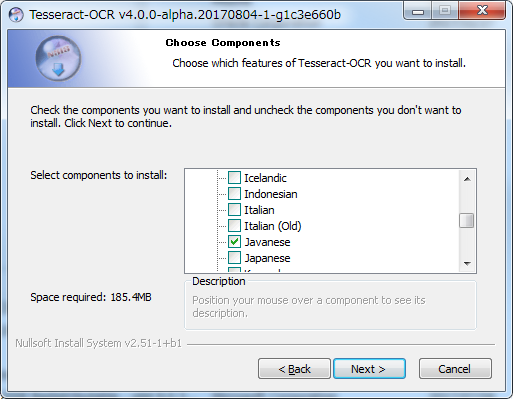
インストーラーを起動して「次へ」をポチポチすればインストール完了ですが、ここで気を付けたいのは、コンポーネントの指定の部分でデフォルトだと「Additional Langage」の部分にチェックマークがついていないので、ここの+部分をクリックして、言語タブを開き中にある「Japanese」のタブにチェックを付けてください。そうしないと画像の日本語の文字をtesseract-ocrが認識できないので、読み込ませても文字化けします。
環境変数を設定する
tesseract-ocrのダウンロード・インストールが終わったら、次は環境変数を設定します。普通はわざわざ設定しなくても勝手にパスが通っているものなのですが、なぜかこのTesseract-OCRに関してはデフォルトでは、インストール後に再起動してもパスが通っていないので、そのままpyocrから呼び出しても、PC上に認識されないので、使用することができません。
その場合、toolsの出力が [] となり、なにも返ってきません。結果、エラー処理により No OCR tool found と出力されてしまいます。
No OCR tool found An exception has occurred, use %tb to see the full traceback. SystemExit: 1
そうならないためには環境変数を設定する必要があります。
Windows10で環境変数を設定(Pathを通す)の場合であれば、まず「コントロール パネル\システムとセキュリティ\システム」に移動して詳細設定のタブを開きます。
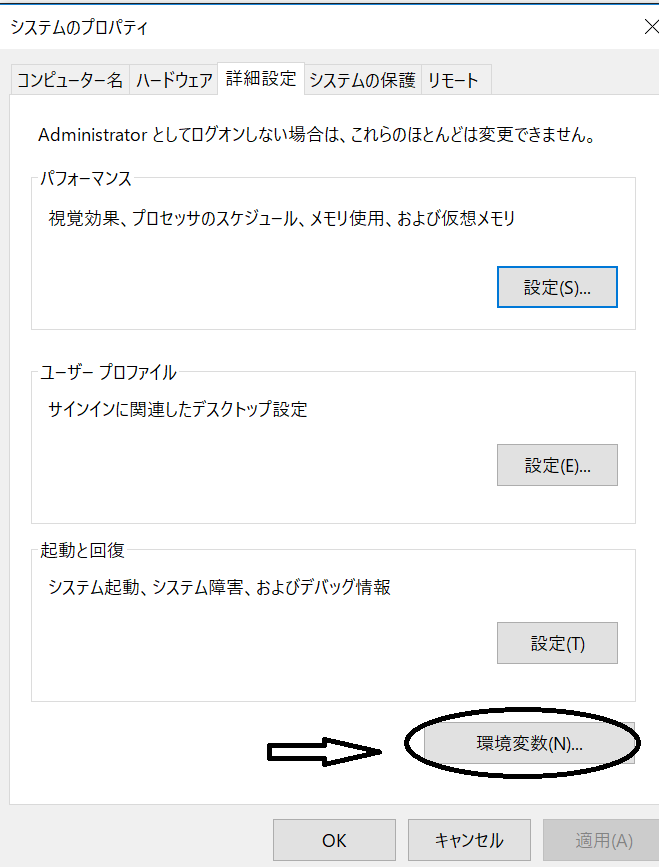
環境変数のタブを開いたら、Pathの部分を指定して、「編集」をクリックします。
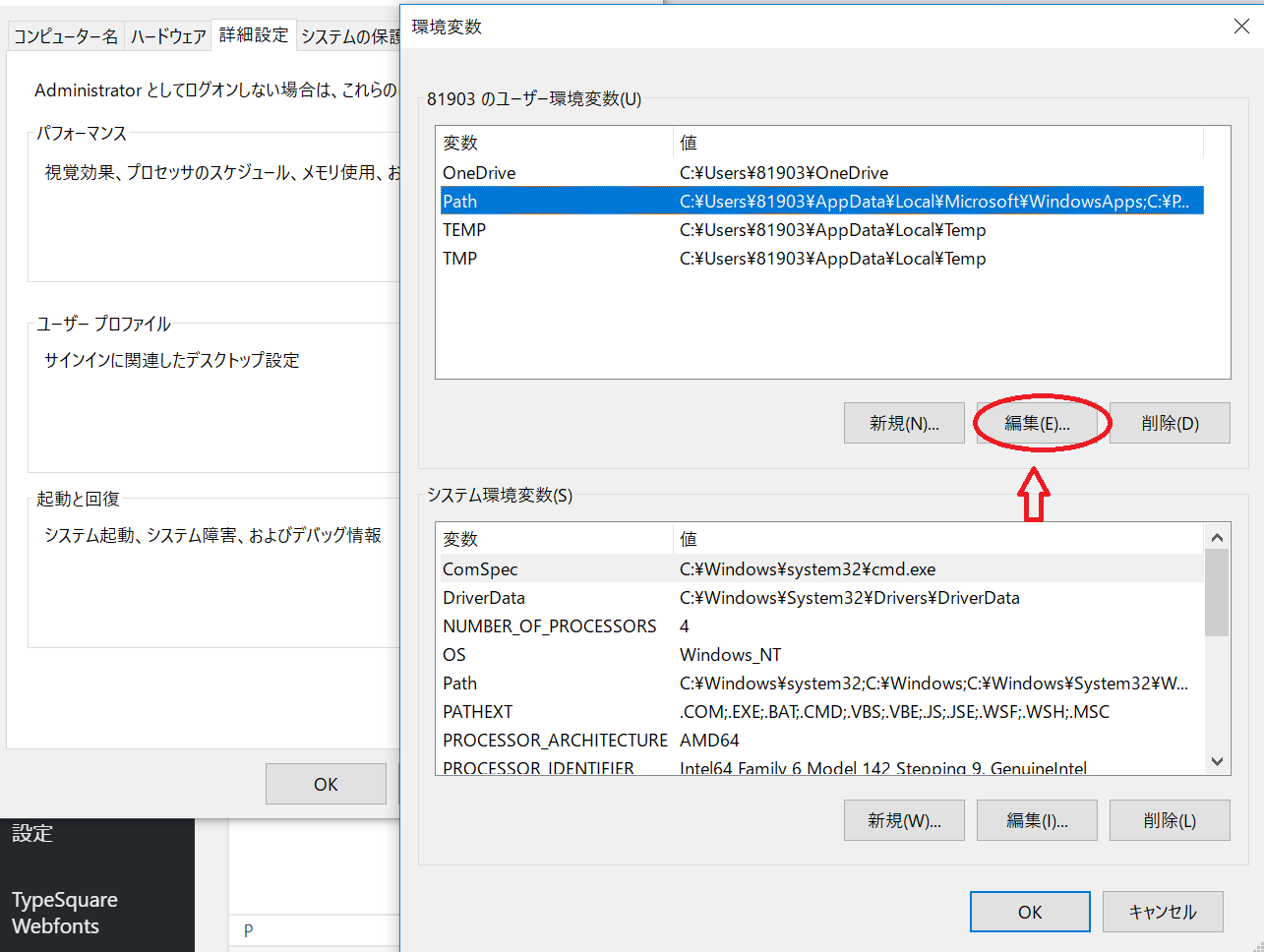
そこにTesseractのパスの追加します。Windows10(64bit版)の場合であれば「C:\Program Files (x86)\Tesseract-OCR」にインストールされているはずですが、インストールするバージョンによってはフォルダ名が違っていたりするので、一応自分の環境でTesseractがインストールされた場所を確認してください。
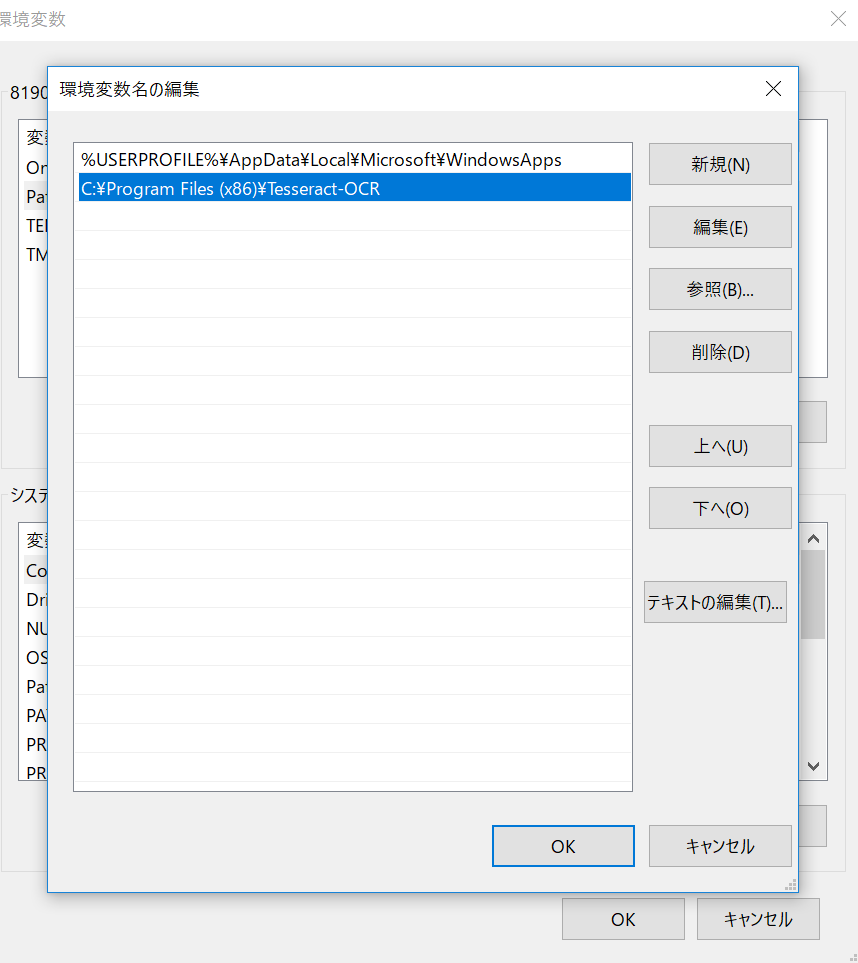
これでOKを押して変更を保存して再起動すれば準備は完了です。これでエラーが出る場合は環境変数の下の欄にあるシステム変数にTESSDATA_PREFIXを追加してパスをC:\Program Files (x86)\Tesseract-OCR\tessdataと設定するとうまくいく動くことがあります。
TESSDATA_PREFIX環境変数が適切に設定されていないと必要なデータが参照できないと云われています。
pyocrでpngに書かれている文字をテキスト化する
これで前準備は終わったので、pyocrでpngファイルに掛かれた文字をテキスト化してみます。今回試しに使う.pngの画像ファイルは↓でファイル名はtest.pngです。

from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
# The tools are returned in the recommended order of usage
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
# Ex: Will use tool 'libtesseract'
langs = tool.get_available_languages()
print("Available languages: %s" % ", ".join(langs))
lang = langs[2]
print("Will use lang '%s'" % (lang))
# Ex: Will use lang 'fra'
# Note that languages are NOT sorted in any way. Please refer
# to the system locale settings for the default language
# to use.
txt = tool.image_to_string(
Image.open('スクリーンショット (113).png'),
lang="jpn+eng",
builder=pyocr.builders.TextBuilder()
)
# txt is a Python string
print(txt)

うーーん、まあまあそれっぽく文字起こしはできているものの、0と1がうまく認識できていない感じですかね?
まあ日本語の文字自体は認識できているので、文字だけの画像ならもっとうまくできそうですね。とりあえずPythonを使ってpyocrとTesseract-OCRで画像ファイルから文字起こしする方法はこんな感じです。


コメント