

Contents
Kaggleとは?
Kaggleに登録方法と機械学習の始め方
まずはKaggleに接続してアカウントを作成してください。アカウントはGoogleアカウントを持っていればすぐに作れます。
kaggleに登録したら、つぎは機械学習に必要な自分のPython環境を確認します。Anacondaに付属しているJupyterNotebookが使えると、機械学習を始めとするデータ分析が非常に捗るので、ぜひ使えるようにしておいてください。
Pythonの開発環境であるAnaconda、そしてJupyterNotebookについては以下の記事で解説しているので、よくわからない方は参考にしていただけると幸いです。
<参照記事>
- ・Anacondaのインストールと初期設定から便利な使い方までを徹底解説!
- ・Jupyter notebookの基本的な使い方を分かりやすく説明する
- ・Window10にPythonの開発環境を構築する上で知っておくべき3つのこと
機械学習に使うライブラリはAnacondaをインストールできていれば、最初から全部インストールされているので、特にPIPなどでライブラリをインストーるする必要はありません。
機械学習に使用するライブラリ
使用するライブラリは以下の4つです。
・Pandas(データ分析用ライブラリ)
・Numpy(行列計算用ライブラリ)
・Matplotlib(プロット用ライブラリ)
・Scikit-learn(機械学習用ライブラリ)
<参照記事>
機械学習に使用するデータセットの用意
まずはデータセットを用意します。kaggleの手始めに使う機械学習用のデータだとタイタニックの乗客データが有名で、日経ソフトウエア 2019年 1 月号とかの機械学習の解説記事で鬼のように酷使されているので、今回は少し違ったデータを使用します。
というわけで今回は銀行の定期預金のデータを使っていきたいと思います。→データセットをダウンロードする
「bank-marketing-dataset.zip」というファイルをダウンロードして解凍するとBank.csvというファイルが出てきます。
データの詳細解説はリンク先にもありますが、顧客の年齢・預金残高やプロモーションをかけた回数などのデータとその顧客が定期預金に登録したかどうかが記録されています。データはCSVなのでエクセルでもPythonでも読み込めて、見てみると↓のような感じになっています。
#read.csvでCSVの読み込み
import pandas as pd
bank=pd.read_csv('bank.csv',sep=',',encoding="UTF-8")
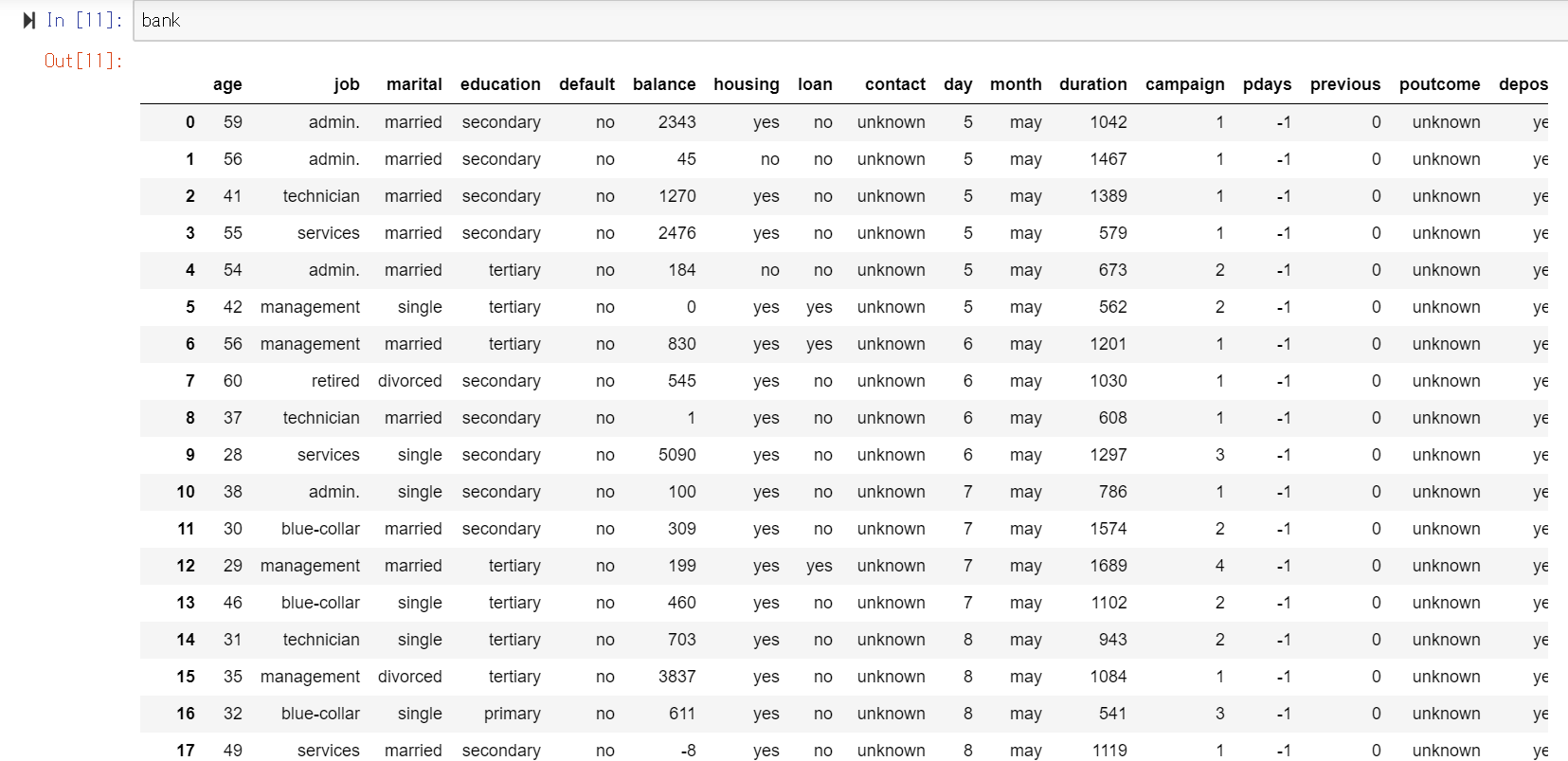
今回のデータは単なるサンプルデータなので関係ありませんが、タイタニックのデータなどコンペの対象になっているデータは、kaggleからダウンロードすると、train.csvとtest.csvの二種類があります。
kaggleのコンペに提供されているデータを使った機械学習は基本的に、test.csvの方には答えが記載されておらず、train.csvを分析して作ったモデルをtest.csvに当てはめて、予測結果を出します。
そして、test.csvの乗客データから予測した正解データ(誰が生き残ったか)をkaggleに送ることで、作成した機械学習モデルが本当の正解データとどれくらい一致していたかをkaggleに判定してもらいます。
タイタニックのやつは単なる入門なので、良い精度が出たところで特になんもありませんが、kaggleで開催されている中で大きなコンペで精度のいい予測モデルを作って入賞したりすると、大手企業から就職のお誘いとかが来たりします。
課題から分析データの何を目的変数にするか決定する
データ分析とは回帰分析からAIまでやっていることの本質は同じでXからYを予測するということで、とどのつまり、Y=aX+bという回帰式を算出することにあります。
機械学習も同じであり、分析を始める前にまず意識したいのはデータセットの何がY(被説明変数)であるかです。これが分かっていないと分析の方向が決まらないので、絶対に意識してください。
今回の銀行の顧客データであれば、顧客データからその顧客が定期預金に登録したかどうかなので、Y(被説明変数)に当たるのはその顧客が定期預金に契約したかどうかを示している[deposit]になります。
機械学習によるデータ分析の目的は顧客の他のデータ(年齢・預金額・・・etc)からdepositするかが予測できる機械学習モデルを作るということにあります。今回の場合だと、「Yを予測するためにX(説明変数)に[年齢]か[預金残高]などの顧客データから何を使うか 」and「 機械が学習しやすいように特徴量を変換するか」が機械学習エンジニアの腕の見せ所ということになってきます。
というわけで早速データ分析に入っていきましょう。
データの概要を把握する
まず機械学習に入る前にデータの全体像を確認します。読み込んだデータフレームの要素数を確認します。
#データの全体像を把握する bank.shape ※(11162, 17)
(11162, 17)と返ってくるので、Bank.csvのデータは11162行17列のデータフレームであることが分かります。
基本統計量と相関係数を計算する
次にデータの概要となる平均・標準偏差・最頻値などを計算していきます。ここでPandas型のデータであればちまちまfor文を使ったりせずとも、pd.describe()で一気に計算できます。こういうところがPandasのスゴイ点ですね。
#各列の平均などのデータの基本統計量を計算する bank.describe()
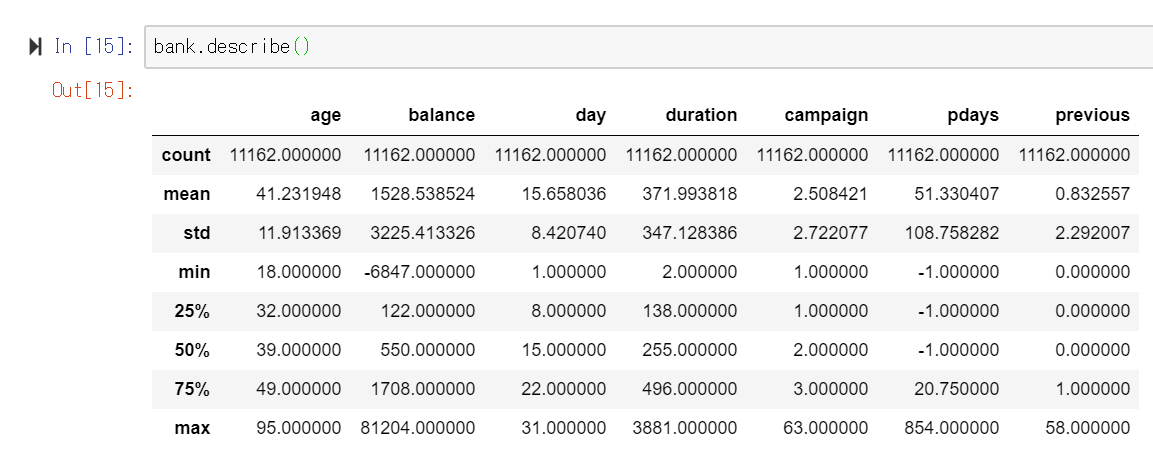
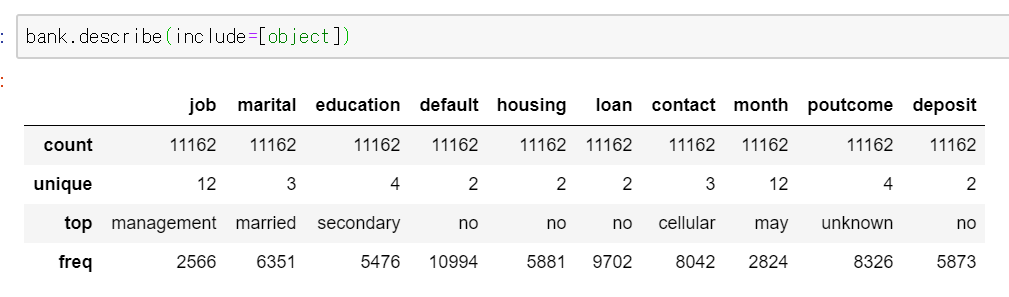
これだけだと文字データはエラーになるので、勝手に除外されます。文字のデータでどの文字が一番多く出現しているかなどを確認したい場合はpd.describe()の引数をinclude=[object]と指定してあげればOKです。
#統計量を確認する 数値型以外はINCLUD=[object], INCLUD=all,EXCLUDEで計算することができる bank.describe(include=[object])
#相関係数を計算する bank.corr()
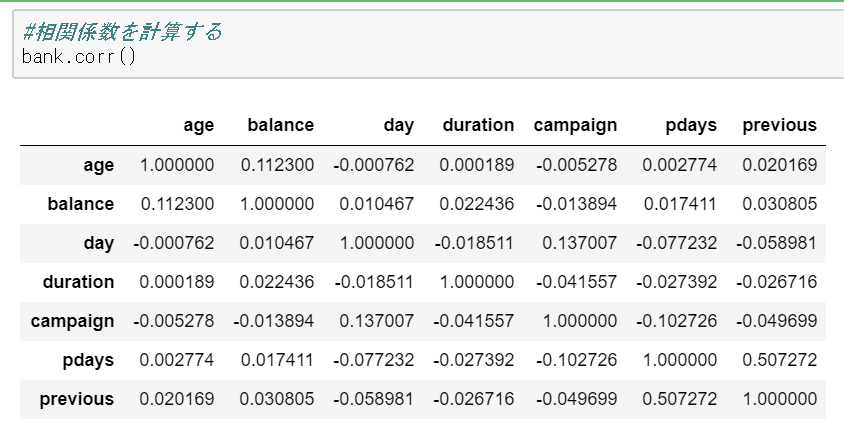
#ageとbalanceの相関係数を計算する df_corr = bank[['age','balance']].corr()
Pandasには一次元のPandas.Seriesとデータフレーム形式のPandas.Dataframeの二種類のデータ形式が用意されています。[]はSeries、[[]]はDataframeで返すということを意味しています。
データをプロットして可視化する
今度はデータの概要をイメージで掴むためにデータを可視化してみます。Pythonでのデータの可視化はMatplotlibというライブラリをつかうことで簡単に行うことが可能です。
#MatplotlibをインポートしてJupyter内でプロットできるようにする
%matplotlib inline
import matplotlib.pyplot as plt
#ヒストグラムを描く
plt.hist(bank_df['age'],label='age')
plt.xlabel('age')
plt.ylabel('frq')
plt.legend()
plt.grid()
plt.show()
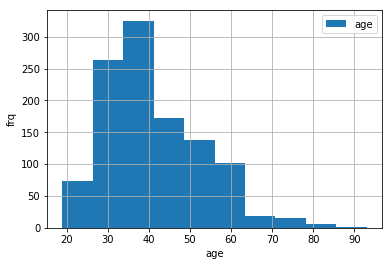
次はJobの列のデータも可視化したいと思います。Pandasのデータフレームであれば、.value_counts()で頻度が抽出できます。
#文字型データ列で単語の頻度を抽出する bank['job'].value_counts() #インデックスと頻度を抽出する job_label=bank['job'].value_counts(ascending=False,normalize=True).index job_vals=bank['job'].value_counts(ascending=False,normalize=True).values
#円グラフを作成する
plt.pie(job_vals,labels=job_label,counterclock=False, startangle=90)
plt.axis('equal')
plt.show()
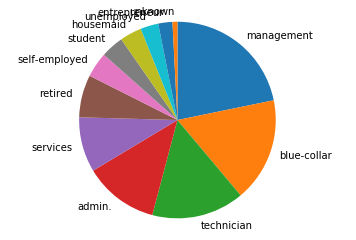
次に欠損値を確認します。Pandasでは.isnull()で確認できます。
#欠損値を確認する bank.isnull().any()
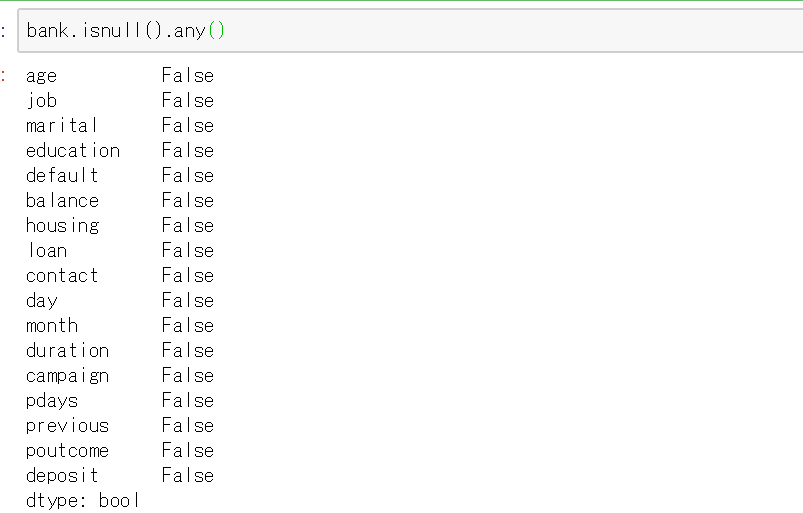
全ての列がFalseと返ってきているので、このデータセットには欠損値はありません。ですが、実務では欠損値があることが当たり前でそういった場合はほかの数値の平均で補完する、欠損値がある行そのものを削除するといったデータ処理を行う必要があります。
これでデータの大まかな流れは把握できました。このまま機械学習と行きたいところですが、このデータのままだとYESやaprやBlue-colorなど文字列が沢山あります。
人間の場合は文字も勝手に認識できますが、コンピューターはそうはいきません。コンピュータは数値でしかデータを読みません、なので、こういった文字列を意味を持たせたまま数値データに変換してあげる必要があります。
こういったデータ処理をPandasやNumpyを使ってデータを可視化して特徴を把握したり、欠損したりデータを置換することを「データの前処理」と言います。
ぶっちゃけ機械学習はモデルが認識できる形にデータを整形すればあとはやることは決まっているので、慣れてしまえば、同じ作業の繰り返しなのでそこまで苦労することはありません。
一番苦しいのがこのデータの前処理の部分です。今回はkaggleが提供していくれているデータなので、綺麗に整っていますが、実際の現場だと欠損値がいっぱいあったりするので、この前処理の部分&クライアントが何を求めているかを理解する(要件定義)の場面が一番トラブりやすいです。
Pandasを使ったデータの前処理
というわけでここからはデータが機械学習の関数に当てはめられるように変換していきます。まずが文字のデータをコンピューターが理解できるように1,0に変換します。
Pandasでのデータの置換にはreplaceやWhereなどいろいろ方法があるので、自分の好きな方法でやるといいかと思います。
#データを置き換えるときはreplace関数を使用する
bank.loan= bank.loan.replace({'yes': 1, 'no': 0})
bank.deposit= bank.deposit.replace({'yes': 1, 'no': 0})
bank.housing= bank.housing.replace({'yes': 1, 'no': 0})
実行して変数[Bank]を確認すると↓のようになっていると思います。
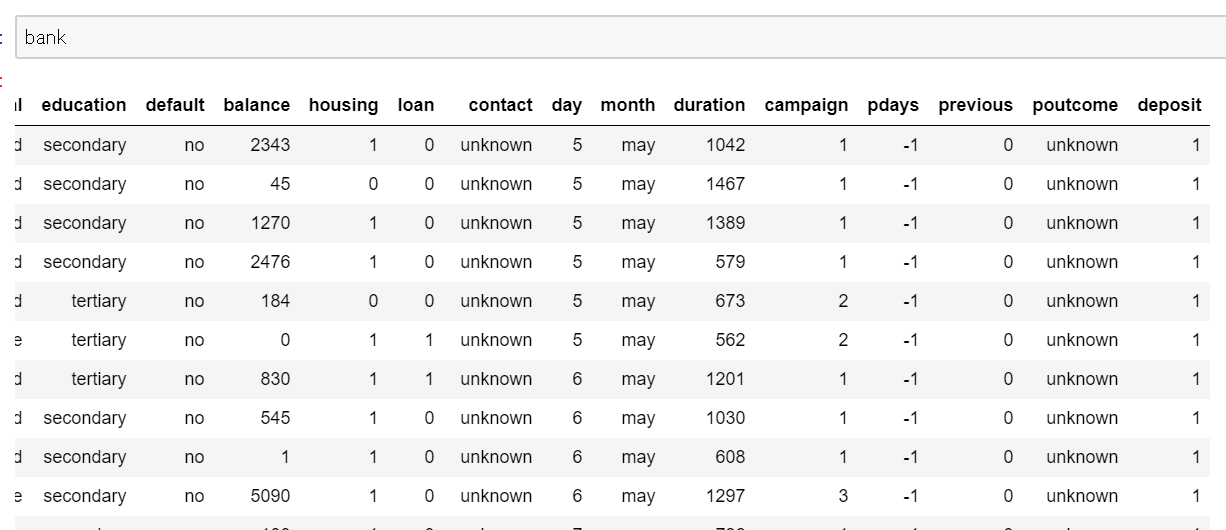
次はMonthの部分をダミー変数に変換します。ダミー変数とは別名onehot化ともいい、以下のようなイメージです。
| 性別 | 男 | 女 | |||
| 0 | 男 | 1 | 0 | ||
| 1 | 女 | ダミー変数化 | 0 | 1 | |
| 2 | 女 | → | → | 0 | 1 |
| 3 | 女 | 0 | 1 | ||
| 4 | 男 | 1 | 0 | ||
| 5 | 男 | 1 | 0 | ||
上記の例は分かりやすくするために男女でしたが、変数の項目が2つである場合は0,1に直すことが一般的でダミー変数は今回のMonthのように2つ以上項目がある変数に対して行います。
#ダミー配列を作成する dammy=pd.get_dummies(bank['month'])
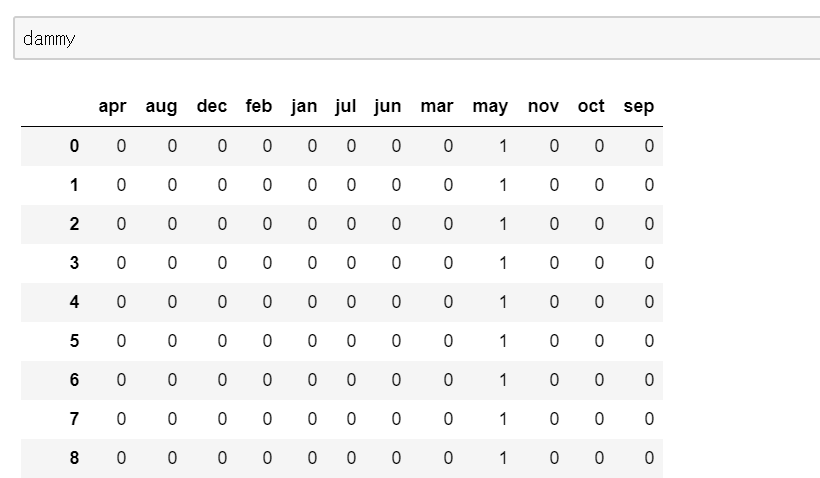
そして、このダミー変数をもとのデータフレームである[bank]と結合します。pandasでのデータフレームの結合はpd.concatでできます。
#pd.concatで目的のデータフレームを作成する forml=pd.concat([dammy,bank],axis=1) forml
pd.concatによるデータの結合は引数naxis=1を指定すると縦方向につなぐことができます。axis=0ならば横方向に結合します。
次はデータフレームの中で分析には要らないと思われる列を削除していきます。データの削除は.drop()で行えます。またデータフレームの捜査結果を新しい変数に保存せずそのまま上書きした場合は関数の引数にinplace=Trueを加えると元のデータフレームに変更内容が反映されます。
#いらない列の削除(特定の列の削除) forml.drop(["poutcome","job","marital","education","default","contact","month"],axis=1,inplace=True)
また特定の行を削除したい場合は↓のように書きます。
#特定の行(この場合だと0行目)を削除 bank.drop(0)
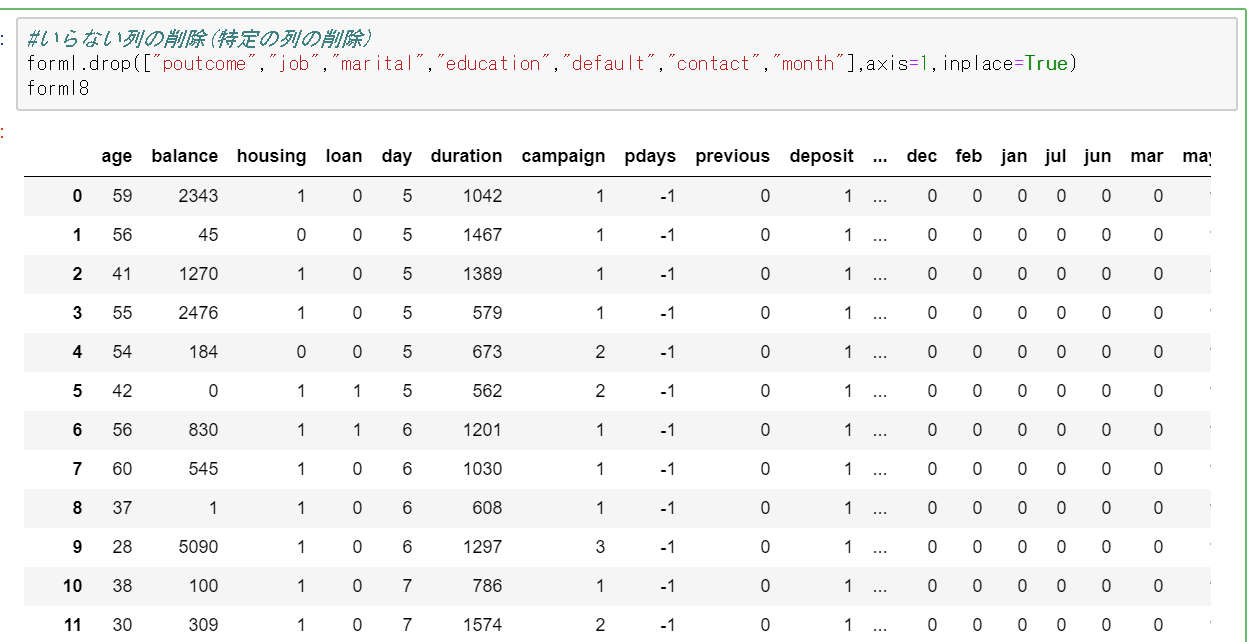
一応.dtypesで各列のデータ型がi nt64 またはunit8であるかを確認していおいてください。万が一String(文字列)やobjectが混じっていると、次の機械学習の部分でのエラーの原因になります。Pandasのデータフレームの文字型の変換は.astype()で行えます。
#データ型の確認 forml.dtypes
これでとりあえず機械学習のモデルに当てはめられるようなデータの形にする前処理は完了しました。今回はざっくりと行いましたが、機械学習モデルの精度はモデルの方式よりもいかに機械が判別しやすいような分かりやすい変数を解くって上げるかというところに依存します。
なので、これでとりあえず前処理は完了ですが、ここから「モデルを作る→結果を受けてまた変数を作り直す」というプロセスを繰り返して機械学習モデルの精度を高めていきます。
こんな感じでデータの前処理にはpandasが輝きます。他にもPandasには便利な機能がモリモリあるので、興味のあるかたは調べてみるといいかと思います。特に「Pythonデータ分析/機械学習のための基本コーディング! pandasライブラリ活用入門 」とかがPandasの取り扱いについてまとまっているのでオススメです。
当たり前のことではありますが、機械学習では扱うデータを間違えないことが大前提なので、「Pythonって便利だけどよくわからない(自分のパターン)」場合は、この本で基礎をキッチリと固めておいた方が良いです。
本屋でタイトルを見た時は「ファイルを読むだけのライブラリだから不要かな」と思って買うつもりは無かったのですが、中身を読んだ時に考えが変わって、購入してじっくり読んだらモヤモヤしていた物がスッキリしましたので、意外な良書に巡り合えました。
データをアルゴリズムに当てはめて機械学習モデルを作成する
ここからはデータの前処理も終わったのでいよいよ本題の機械学習に入っていきます。機械学習アルゴリズムはいろいろありますが、まずは決定木でアプローチしていくことが多いです。
なぜかという決定木はアルゴリズムの分類基準がブラックボックスになりやすい機械学習の中でコンピューターが何の変数を以って分類を行っているのかが非常に分かりやすいからです。
なので、まずは決定木を使った機械学習を行っていきます。Pythonでの機械学習にはscikit-learnというライブラリを使用します。
#データを分割する
#ライブラリのインポート
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
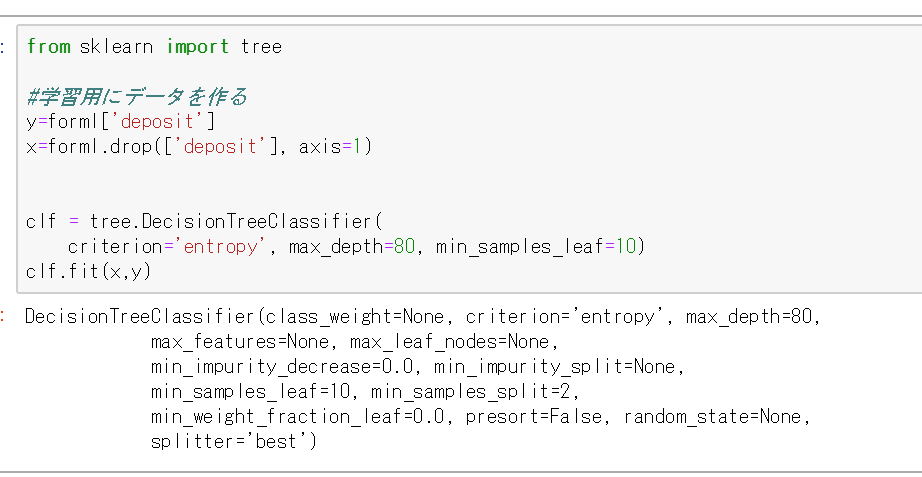
from sklearn import tree
#学習用にデータを作る
y=forml['deposit']
x=forml.drop(['deposit'], axis=1)
clf = tree.DecisionTreeClassifier(
criterion='entropy', max_depth=80, min_samples_leaf=10)
clf.fit(x,y)
実行すると↓のような感じでモデルが確認できます。
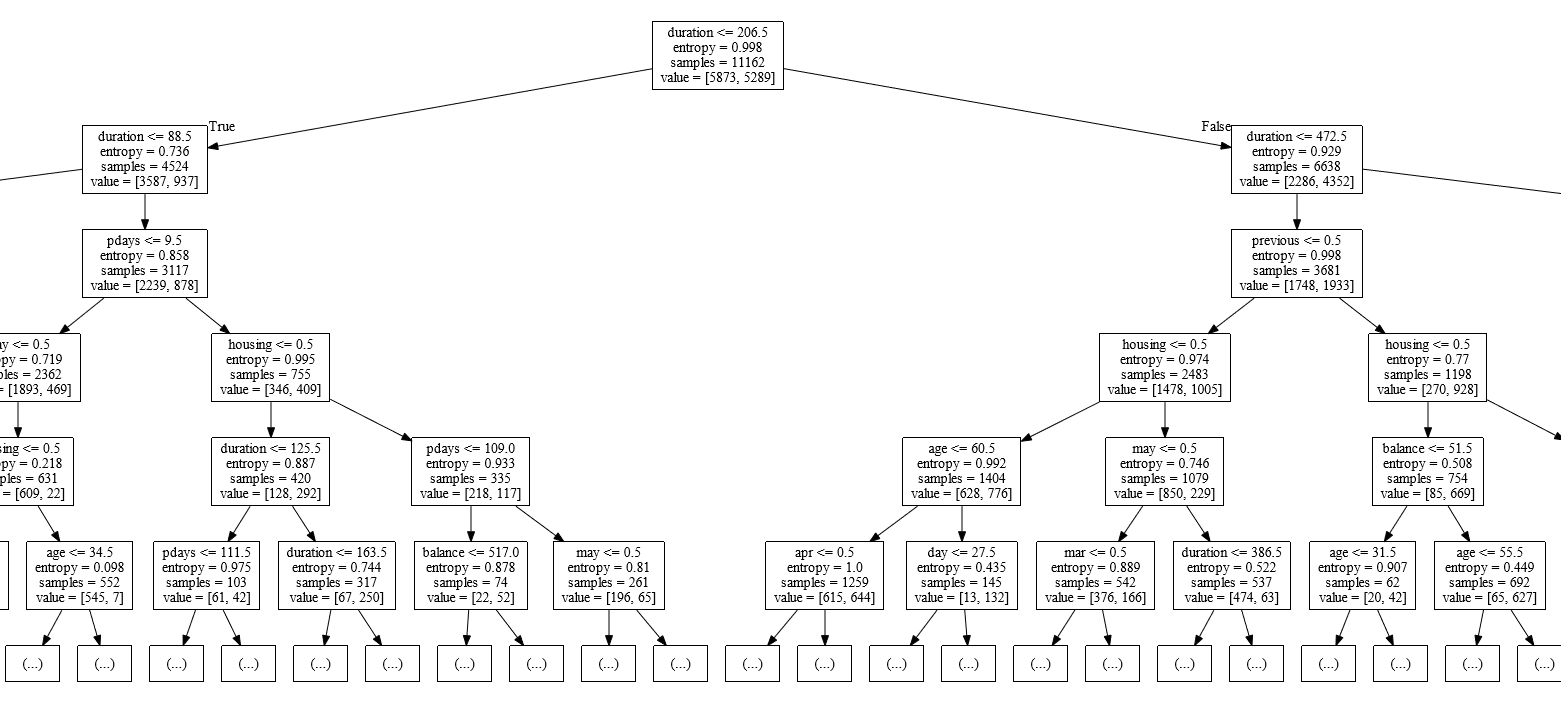
Scikit-learnで作った決定木モデルを可視化する
モデルの保存と呼び出し
学習は終わって予測モデルを作成することができたら、次はそれを外部で使用するために.pklという形式で出力することが多いです。
# 作成した機械学習モデルを保存する from sklearn.externals import joblib joblib.dump(clf, 'ml_model.pkl') #作成した機械学習モデルをテストデータに当てはめる pred=clf.predict(df_new3)
終わり
以上がざっくりとしたKaggleのデータを用いた機械学習の始め方になります。機械学習は自分で新しいアルゴリズムを作るとかでなければ、数学が分からなくとも始めることができます。



コメント