
Contents
前回までにやったこと
・【Python】Anacondaのインストールと初期設定から便利な使い方までを徹底解説!
・【Python】Jupyter notebookの基本的な使い方を分かりやすく説明する
これまではANACONDA(アナコンダ)のインストールと「Jupyter Notebook」に基本的な使い方を見てきました。今回は「Jupyter Notebook」でデータ分析をするうえで欠かせない「pandas」というライブラリの使い方を紹介していきます。
Pandasでできること
まずPandasは何ができるの?? って話なのですが、簡単に言うとPandasはExcelで縦横(行列)の表を操作するみたいな事がPythonの環境でもできるようにしてくれるライブラリです。
Pythonを使う人の大半の目的が、データ分析に必要なHTMLやJSONなどのデータをウェブから収集するウェブスクレイピングのしやすさにあると思うので、これによって集めたデータを分かりやすく整えてくれる pandas はpythonでデータ処理を行う上で必須ライブラリでしょう。
2つのデータ型
Pandasには行列形式の「Pandas Dataframe」と一次元の配列の「Pandas Series」の2つのデータ型(クラス)が用意されており、Pythonを使ったデータ分析ではこのPandasから提供されている2つのデータ型と、別の記事で解説しているNumpyという演算ライブラリを使ってデータを処理していきます。
このシリーズの予定
今回のシリーズの記事で行っていくことは以下のような処理です。
・データの取り出し
・欠損地の取り扱い
・ラベルの位置の自動調整
・データの集計と要約
・条件を満たすデータの抽出
・データセットの結合
・データセットの変換
pandasのインストール
多分AnacondaだとPandasはデフォルトでインストールされているので、「Jupyter Notebook」を起動してImport pandasで有効化できると思いますが、Python3.6単体でインストールしている人はコマンドプロンプト(cmd.exe)を開いてpipコマンドでインストールしてください。
インポートの際は「import pandas」ではなく、import pandas as pdと入力するのが暗黙の了解というか皆がそうしているのでそうしておいた方がいい的なマナーになっています。Pandasではなくpdとして読み込んだ方がコードが短縮されるというのが理由だと思います。
サンプルデータの取得
まずはPandasでのデータ処理に使うサンプルデータを呼び出してきます。サンプルデータは用意されていないので、機械学習用のライブラリである「Scikit-learn」にあるサンプルデータを使っていきます。
「Scikit-learn」はAnacondaならデフォルトでインストールされているので、以下のコマンドで動きますが、そうでない場合はコマンドプロンプトからpipでインストールしてください。
そしてScikit-learnで読み込んだデータをpd.DataFrameという関数です。Pandas形式のデータフレームに変換しています。
#ライブラリの読み込み from sklearn.datasets import load_iris import pandas as pd #クラスの呼び出し iris = load_iris() #データフレームに変換する sample=pd.DataFrame(iris.data, columns=iris.feature_names)
引数の「columns」は列を意味しており、columns=iris.feature_namesと記述することで、今回は列名はiris.feature_namesというリストの中身を使うと指定しています。row(index)の方は何も指定しないと0から始まる数値が自動的に割り振られていきます。

そして、実行すると以下のようなデータになっていると思います。↓
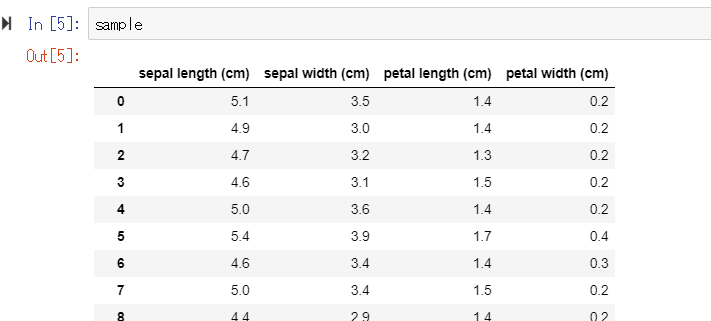
.locで特定の行・列のデータを抽出する
Pandasは様々な関数でデータを抽出することができますが、Pandasでデータフレームの中から特定データ抽出する方法は「.loc」と「.iloc」の2つのやり方があり、文字も似ているのでややこしいというのが少しネックですね。ただどちらも便利なので覚えておいて損はありません。
まずは.locでのデータ抽出を行っていきます。上述したようにPandasDataframeは.locでデータを抽出することができます。pandaで特定の行のデータを抽出した場合は以下のように書きます。
#7行目の数値を全部抜き出してリストで返す sample.loc[7] ※結果 sepal length (cm) 5.0 sepal width (cm) 3.4 petal length (cm) 1.5 petal width (cm) 0.2 Name: 7, dtype: float64 #7行目の数値を全部抜き出してデータフレームで返す sample.loc[[7]] #7行目と77行目の数値を全部抜き出してデータフレームで返す sample.loc[[7,77]] #7行目の数値を全部抜き出してデータフレームで返す sample.loc[:7]
Pandasでは[]とすると一次元リスト形式(Pandas.Series)、[[]]だとデータフレーム形式(Pandas.dataframe)でデータを返してくれます。.locでは離れた複数の列も同時に抽出することが可能です。
また特定の1つのデータだけでなく、行(列)すべてのデータを抽出したい場合は、片方を「:」とすることで抽出できます。
反対に特定の列を抽出したい場合は以下のように記述します。注目するべき点としては返すデータが1つだと[]でいいですが、複数の場合だと[[]]にすることでデータフレームにしないといけない点ですね。
#1列目('sepal length (cm)'の列)のデータを全部抽出する
sample['sepal length (cm)']
#複数の列を抽出する
sample[['sepal length (cm)','petal length (cm)']]
#複数の列の1~5行目を抽出する
sample[['sepal length (cm)','petal length (cm)']][0:8]
比較演算子(真偽値)を使ったデータ抽出
Pandasのデータフレームの面白い点としては、データが格納されている変数に対して真偽値を投げるだけで、データの1つ1つの数値にTRUE・FALSEを返す比較演算の処理ができるという点です。
#2以上ならTrue、未満ならFalse sample>2
するとこんな感じで配列の要素1つ1つに真か偽かを返してくれます。
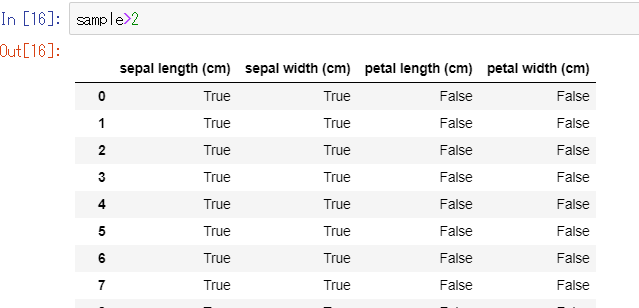
これの何が便利なのかという話なわけですが、この比較演算の処理ができるということはif文でリストに対して行うような処理をデータフレームにもそのままできるのです。
なので、こういう感じに特定の条件を満たす配列だけを抽出するということもできます。
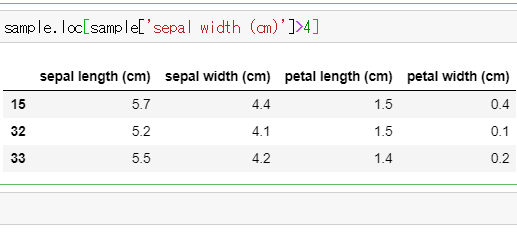
#sepal width (cm)が4以上のデータを抽出する sample.loc[sample['sepal width (cm)']>4]
※結果
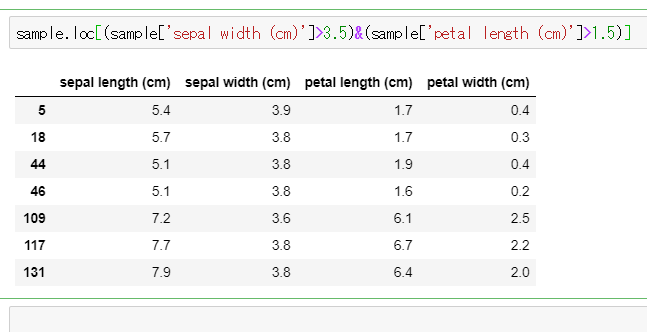
また2つ以上の条件抽出する場合は以下のように&を使って記述します。
#sepal width (cm)が3.5より大きく #かつpetal length (cm)が1.5より大きい配列を抽出する sample.loc[(sample['sepal width (cm)']>3.5)&(sample['petal length (cm)']>1.5)]
※結果
終わり
とりあえずデータフレームの基本的な操作は以下のような感じです。これだけでも簡単なデータ操作はできると思いますが、よりPandasを使いこなすため、次はSeriesの操作と「リストをデータフレームの変換する」・「csvの読み込み」・「処理したPandasのデータをcsvに保存する方法」などついて説明していきます。
→(続き)【Python】データ分析に超便利な「pandas」の使い方を解説!!(その②)


コメント