
今回は前回スクレイピングして前処理したデータをもとにしてk-mean法によるクラスタリングを行います。pythonではpandasのモジュールで実装することが可能です。
前回の記事:【Python】pandas-datareaderでVIX(恐怖指数)をスクレイピングで取得する
基本的にクラスタリングはデータをいくつかのクラスターに分類する分析手法ですが、この際にいくつのクラスターに分類するかは人間が引数で設定します。ではこのクラスター数をどう決めるのかという話ですが、人間が雰囲気で決めてしまうと主観が入り込んでしまいます。
そうならないように今回はエルボー法を使って最適なクラスター数がいくつなのかを算出してその数に従ってクラスタリングを行います。
エルボー法で最適なクラスタ数を求める
K-Means法で分類する前に、最適なクラスタ数つまり分類数のあたりを付けていきます。
import pandas as pd
inertia =[]
x = range(1, 50)
# 1~50までで最適なクラスタ数を繰り返しで計算する
for i in x:
model = KMeans(n_clusters=i)
model.fit(tsvix)
inertia.append(model.inertia_)
plt.plot(x, inertia, marker='o')
<実行結果>
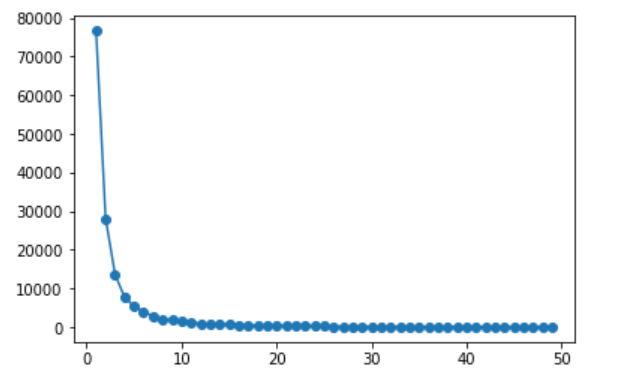
何となくだが、分類するクラスタ数は5くらいでいいと思う(小並感)。
k-Mean法でVIXをクラスタリングする
from sklearn.cluster import KMeans
n_clusters = 5
model = KMeans(n_clusters=n_clusters)
tsvix = ts.iloc[:, :1]
ts['pred'] = model.fit_predict(tsvix)
# クラスタリングしたデータを0~4まで一種類ずつ取り出して上書きプロットしていく
for i in range(n_clusters):
# i(0~4)に当てはまるデータをデータフレームから抽出する
ts2 = ts.loc[ts['pred'] == i]
# 散布図をプロットする
plt.scatter(ts2['vix'], ts2['vol']/100)
# ラベルを付ける
plt.xlabel("VIX")
plt.ylabel("Logarithmic rate of return")
<実行結果>

当たり前ではあるが、VIXが大きくなっていくと対数収益率(ボラティリティ)、つまり金融工学におけるリスクもそれにともなって大きくなっていくのが分かります。
関連記事:【Python】pandasでビットコイン価格のローソク足と移動平均線を計算してプロットする
関連記事:【Python】機械学習で株価を予測する~Scikit-Learnの決定木アルゴリズムを使う


コメント