
webサイトのテーブルタグの中身のデータをまとめて簡単に取得する方法がないかを探していたところpandasのpd.read_html()という関数が非常に便利だったのでメモがてら紹介したいと思います。
pd.read_html()でウェブサイトのテーブルタグ内のデータをデータデータフレームにしてスクレイピングする
今回はスクレピングするのは商品先物価格情報(TOCOM)の先物商品の価格情報です
dfs = pd.read_html(f'https://cf.market-info.jp/Japanese/Future/PriceInfoListTocom?productNm=All&tz=WholeDay&dateStr=2021%2F12%2F02')
# 最初のテーブルを表示させる
print(dfs[0].head())
#すべてのテーブルをcsvに出力する
count = 0
for i in dfs:
count += 1
i.to_csv(f'{count}.csv', encoding='cp932')
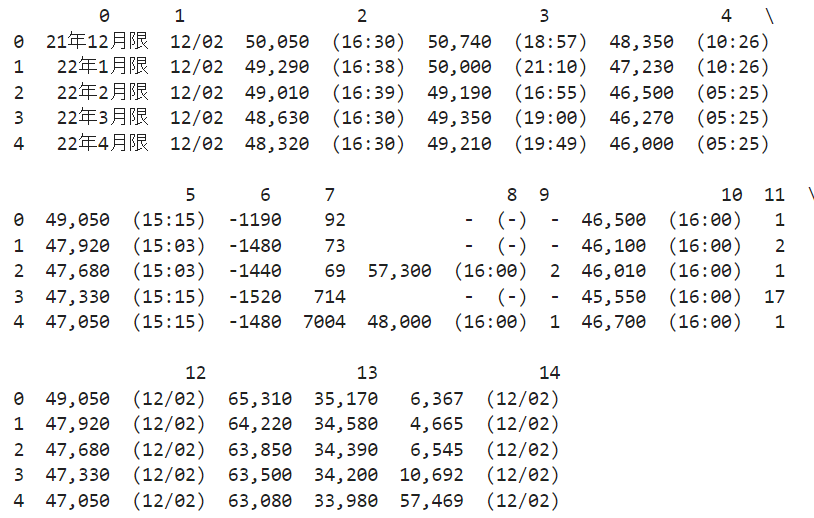
こんな感じで関数1つでテーブルタグ内のデータをデータフレームにして吐き出してくれるので非常に便利です。Pandasはやはりすごい。。。
ただこの関数は非同期処理で生成されるテーブルタグには対応していないのでそういう場合はSeleniumのpage_sourceなどで取得したHTMLタグデータを引数に渡してあげればよいです
<イメージ> driver.get(f'https://cf.market-info.jp/Japanese/Future/PriceInfoListTocom?productNm=All&tz=WholeDay&dateStr=2021%2F12%2F02') dfs = pd.read_html(driver.page_source)
関連記事:【Python】Seleniumでのスクレイピングでよく使うサンプルコードまとめ
<おまけメモ>
dfs = pd.read_html(f'https://cf.market-info.jp/Japanese/Future/PriceInfoListTocom?productNm=All&tz=WholeDay&dateStr=2021%2F{month}%2F{day}')
r = requests.get(f'https://cf.market-info.jp/Japanese/Future/PriceInfoListTocom?productNm=All&tz=WholeDay&dateStr=2021%2F{month}%2F{day}')
soup = BeautifulSoup(r.content,'html.parser')
num = 0
tocom_df_lists = []
for df in dfs:
df.columns=['限月','取引日','始値','高値','安値','現在値','前日比','取引高','売り気配', '売り気配数量','買い気配','買い気配数量','帳入値段','SCB幅上限/下限','取組高']
df=df[:-2].copy()
df['帳入値段'] = df['帳入値段'].apply(lambda x: x.split('(')[0])
df['帳入値段'] = df['帳入値段'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['始値'] = df['始値'].apply(lambda x: x.split('(')[0])
df['高値'] = df['高値'].apply(lambda x: x.split('(')[0])
df['安値'] = df['安値'].apply(lambda x: x.split('(')[0])
df['現在値'] = df['現在値'].apply(lambda x: x.split('(')[0])
df['前日比'] = df['前日比'].apply(lambda x: x.split('(')[0])
df['取引高'] = df['取引高'].apply(lambda x: x.split('(')[0])
df['売り気配'] = df['売り気配'].apply(lambda x: x.split('(')[0])
df['売り気配数量'] = df['売り気配数量'].apply(lambda x: x.split('(')[0])
df['買い気配'] = df['買い気配'].apply(lambda x: x.split('(')[0])
df['買い気配数量'] = df['買い気配数量'].apply(lambda x: x.split('(')[0])
df['限月(数値)'] = df['限月'].apply(lambda x: re.sub(r'\D', '', x))
df['限月(数値)'] = df['限月(数値)'].apply(lambda x : int(x[:2]+'0'+x[2]) if len(x) == 3 else int(x))
df['始値'] = df['始値'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['高値'] = df['高値'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['安値'] = df['安値'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['現在値'] = df['現在値'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['前日比'] = df['前日比'].apply(lambda x : x.replace('-', '') if x == '-' else float(x.replace(' ', '').replace(',', '')))
df['取引高'] = df['取引高'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['売り気配'] = df['売り気配'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['売り気配数量'] = df['売り気配数量'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['買い気配'] = df['買い気配'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df['買い気配数量'] = df['買い気配数量'].apply(lambda x : x.replace('-', '') if '-' in x else float(x.replace(' ', '').replace(',', '')))
df = df[['取引日', '限月', '帳入値段','始値', '高値','安値','現在値','前日比','取引高','売り気配', '売り気配数量','買い気配','買い気配数量','限月(数値)' ]]
df = df.replace('- (-)', '')
df = df.replace('- ', '')
tocom_df_lists.append(df)
# 日ごとのデータ
with pd.ExcelWriter(f'{todate}_商品先物価格情報収集データ.xlsx', mode='w') as writer:
for d in tocom_df_lists:
num += 1
print(soup.find_all('h2')[num].text.strip().lstrip().rstrip())
d[['取引日','限月', '帳入値段','始値', '高値','安値','現在値','前日比','取引高','売り気配', '売り気配数量','買い気配','買い気配数量','限月(数値)' ]].to_excel(writer, sheet_name=soup.find_all('h2')[num].text.strip().lstrip().rstrip(), index=False, encoding='cp932')
print('処理完了')


コメント
[…] 関連記事:【Python】requestsでapparent_encodingが「Windows-1254」だったときの対処法 […]