
こんにちは、ミナピピン(@python_mllover)です。
今回はiTunesStoreのアプリや音楽の情報をスクレイピングする方法について紹介していきたいと思います。
まずiTtuneStoreにはitunes-search-apiというapiが提供されているのでそれを叩くことでbeautifulsoupなどを使わずにスクレイピングが可能になります。
apiドキュメント⇒https://affiliate.itunes.apple.com/resources/documentation/itunes-store-web-service-search-api/
Pythonでituneアプリのレビューをスクレイピングする
というわけでこのAPIを使ってitune storesのアプリのレビュー内容をpythonでスクレイピングしていきます。
パラメーター設定の肝は”media”:’software’,で、mediaでアプリなのか音楽なのか検索するコンテンツ種類を指定して”country”:”JP”,と “lang”:”ja_jp”, で日本語のレビュー内容を取得できるように指定しています。
import json
import requests
import urllib
import pandas as pd
import re
from bs4 import BeautifulSoup
def itunes_api_search_encoder(d):
s = ""
for k, v in d.items():
if k == "term":
v.replace(" ", "+")
s += k + "=" + v + "&"
s = s[0:-1]
#s = urllib.parse.quote(s[0:-1])
return s
def itunes_api_song_parser(json_data):
lst_in = json_data.get("results")
lst_ret = []
for d_in in lst_in:
d_ret = {
"title": d_in.get("trackName"),
"artist": d_in.get("artistName"),
"album": d_in.get("collectionName"),
"title": d_in.get("trackName"),
"id_track": d_in.get("trackId"),
"id_artist": d_in.get("artistId"),
"id_album": d_in.get("collectionId"),
"no_disk": d_in.get("discNumber"),
"no_track": d_in.get("trackNumber"),
"url": urllib.parse.unquote(d_in.get("trackViewUrl")),
}
lst_ret.append(d_ret)
return lst_ret
uri = 'https://itunes.apple.com/search'
params = {
"term":"ウマ娘",
"attribute": "",
"media":'software',
"entity": "iPadSoftware",
"country": "JP",
"lang": "ja_jp", #"en_us", #
"limit": "10",
}
uri = uri + "?" + itunes_api_search_encoder(params)
res = requests.get(uri)
json_data = json.loads(res.text)
data = itunes_api_song_parser(json_data)
app_data_list = []
for app in data:
#print(app['title'], app['url'], app['id_track'])
app_data_list.append([app['title'], app['url'], app['id_track']])
review_data = []
for app_data in app_data_list:
# アプリIDをキーにして各アプリのレビュー情報を取得する
app_url = 'https://itunes.apple.com/jp/rss/customerreviews/id=' + str(app_data[2]) + '/json'
app_res = requests.get(app_url)
app_json_data = json.loads(app_res.text)
# リンク情報を取得
link_data = app_json_data['feed']["link"]
print(app_data[0], app_data[2])
# 最後のリンク情報を取得
last_link = link_data[3]['attributes']['href']
# リンクのページ数を取得
if re.sub(r'\D', '', last_link[52:56]) == '':
page_count = 0
else:
page_count = int(re.sub(r'\D', '', last_link[52:56]))
print('レビューのページ数', page_count)
# 最初の50件のレビューを取得
for review in app_json_data['feed']['entry']:
review_rating = review['im:rating']['label']
review_id = review['id']['label']
review_title = review['title']['label']
review_content = review['content']['label']
# print(review_title, review_content)
review_data.append([app_data[0], app_data[2], review_id, review_rating, review_title, review_content])
# 残りのレビューを取得
if page_count > 2:
for page in range(2, page_count):
res = requests.get('https://itunes.apple.com/jp/rss/customerreviews/page=' + str(page)+'/id='+ str(app_data[2]) +'/sortby=mostrecent/xml?urlDesc=/customerreviews/id=' +str(app_data[2]) +'/json')
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, 'html.parser')
for i in range(len(soup.find_all('entry'))):
review_rating = soup.find_all('entry')[i].find_all('im:rating')[0].text
review_id = soup.find_all('entry')[i].find_all('id')[0].text
review_title = soup.find_all('entry')[i].find_all('title')[0].text
review_content = soup.find_all('entry')[i].find_all(type="text")[0].text
# print('レビュータイトル:',review_title)
# print('レビュー内容:', review_content)
# print('\n')
review_data.append([app_data[0], app_data[2], review_id, review_rating, review_title, review_content])
elif page_count == 2:
res = requests.get('https://itunes.apple.com/jp/rss/customerreviews/page=2/id=1205990992/sortby=mostrecent/xml?urlDesc=/customerreviews/id=1205990992/json')
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, 'html.parser')
for i in range(len(soup.find_all('entry'))):
review_rating = soup.find_all('entry')[i].find_all('im:rating')[0].text
review_id = soup.find_all('entry')[i].find_all('id')[0].text
review_title = soup.find_all('entry')[i].find_all('title')[0].text
review_content = soup.find_all('entry')[i].find_all(type="text")[0].text
# print('レビュータイトル:',review_title)
# print('レビュー内容:', review_content)
# print('\n')
review_data.append([app_data[0], app_data[2],review_id, review_rating, review_title, review_content])
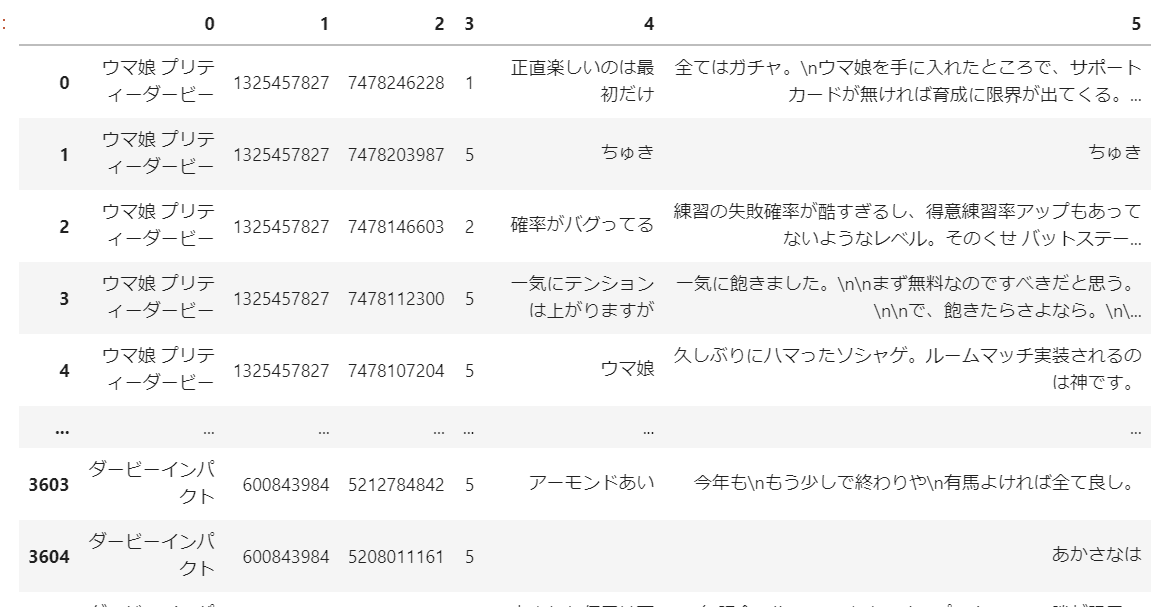
pd.DataFrame(review_data)
同じ処理があるので関数にすべきですが、とりあえずこれで動きます。アナリストは自己完結するのでコードが汚くなりがち・・・
一応こんな結果が取れます。
おまけになりますが、音楽の情報を検索したいときはparamsは以下のようにしてあげると良いと思います。
"""
params = {
"term": "カントリーロード",
"attribute": "songTerm",
"entity": "song",
"country": "JP",
"lang": "ja_jp", #"en_us",
"limit": "10",
}
"""

コメント