
今回は業務で2つのデータフレームを比較して差分や内容に違いがある行だけを抽出したいな~と思ったのですが、少し手間取ったのでやり方をメモしておきます
データの準備
Pandasで2つのデータフレームを比較して処理を行う実例として以下のデータフレームを使用します。
import pandas as pd
df_2019 = pd.DataFrame({'商品ID':[1, 2, 3, 4, 5], '商品名': ["水", "炭酸水", "コーヒー", "コーラー", "ポカリ"], '平均価格': [200, 120, 250, 300, 260]})
df_2022 = pd.DataFrame({'商品ID':[1, 2, 3, 4, 6], '商品名': ["水", "炭酸水", "コーヒー", "コーラー", "コーラーゼロ"], '平均価格': [300, 120, 350, 300, 560]})
df_2019
商品ID 商品名 平均価格
0 1 水 200
1 2 炭酸水 120
2 3 コーヒー 250
3 4 コーラー 300
4 5 ポカリ 260
df_2022
商品ID 商品名 平均価格
0 1 水 300
1 2 炭酸水 120
2 3 コーヒー 350
3 4 コーラー 300
4 6 コーラーゼロ 560
① ~isinを使う
一番王道なのは「~」のnot演算子と「isin」を組み合わせる方法です
<例>
df_2019[~df_2019['商品名'].isin(df_2022['商品名'])]
<実行結果>
下記のように2019年のものには存在して2022年には存在しない要素を抽出することができます
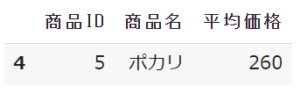
これの欠点としては差分の比較ができるのが1つの列だけという点です。
複数の列を対象に差分を取りたい場合は使えません
②outerでmergeする
2つ目はpandasのmerge関数でouterを指定する方法です
df = pd.merge(df_2019,df_2022, on=['商品ID', '商品名'], how='outer', indicator=True) df
引数の簡単な説明にはなりますが。
indicatorでどちらのデータフレームにあったかという情報を取得していて
mergeという列が追加され、both, left_only, right_onlyのいずれかが入ります。
<結果>
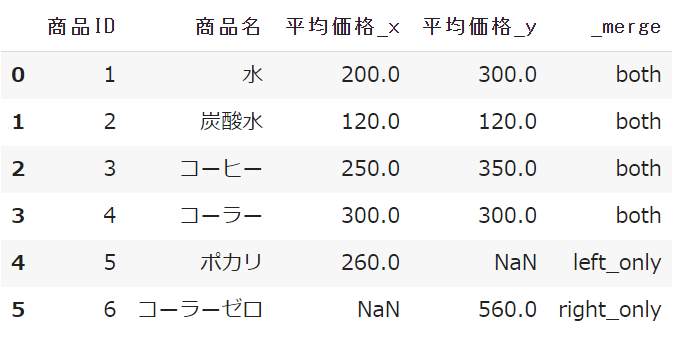
ここから2019年のデータにはあって、2022年のデータにはない条件のみを抽出したい場合は以下のように記述します
df[df['_merge'] == 'left_only'].iloc[:,:-1]
<実行結果>
商品ID 商品名 平均価格_x 平均価格_y
4 5 ポカリ 260.0 NaN
反対に2019年にはなくて2022年にはあるデータだけを抽出したい場合は以下のように記述します。
df[df['_merge'] == 'right_only'].iloc[:,:-1]
<実行結果>
商品ID 商品名 平均価格_x 平均価格_y
5 6 コーラーゼロ NaN 560.0
こんな感じで2つのデータフレームを比較して異なる部分だけを確認することができます
mergeするとメモリに乗らないようなデータだと難しいですが、その場合はもうbigqueryみたいな分析用のデータベースにデータを載せてSQLで確認したほうが良いかなと思います
終わり
差分の対象にしたいキーが1つの場合は①で問題ないですが、大抵2つくらいあると思うので②の方法がの方が応用が効くので個人的には②をよく使います。では~
関連記事:【Python】pandasのgroupbyで日ごとのデータを集計する

コメント
[…] 関連記事:pandasで2つのデータフレームの行の差分を取得する方法 […]