
今回はPythonでStable Diffusionを用いて、テキストから画像を生成する方法を紹介したいと思います
Contents
Stable Diffusionとは
Stable Diffusionとは、2022年8月に無償公開された画像描画AIです。
学習済みモデルが公開されており、Pythonから利用することが出来ます。
Stable Diffusionを用いることで、テキストでを与えることでそれに応じて画像が自動生成されます。
入力された文字列から画像を生成するタスクのことをText to Imageタスクと呼びます。
事前設定
Colabの設定
Stable Diffusionのモデルを使用するためには、GPUが必要です。今回は手っ取り早くGPU環境を用意できるGoogle Colaboratory上でコードを書いていきます。
まず前準備としてノートブックのランタイムをGPUに変更します。方法はColab上部メニューの 「編集」 → 「ノートブックの設定」を選択。ハードウェアアクセラレータ を None から GPU に変更して保存します。
HuggingFaceのアカウント作成
Hugging Faceは、自然言語処理を対象にしたオープンソースの人工知能コミュニティーで、学習済みモデルやデータセットなどが公開されているサービスです。
HuggingFaceにアクセスし画面右上のSign Upよりアカウントを作成します。
メールアドレスとパスワードを入力すると以下のようなページに遷移します。
UsernameとFull nameを入力します。
API鍵の発行
https://huggingface.co/CompVis/stable-diffusion-v1-4
HuggingFaceの画面右上のアイコンから[Settings]ページをクリックします。
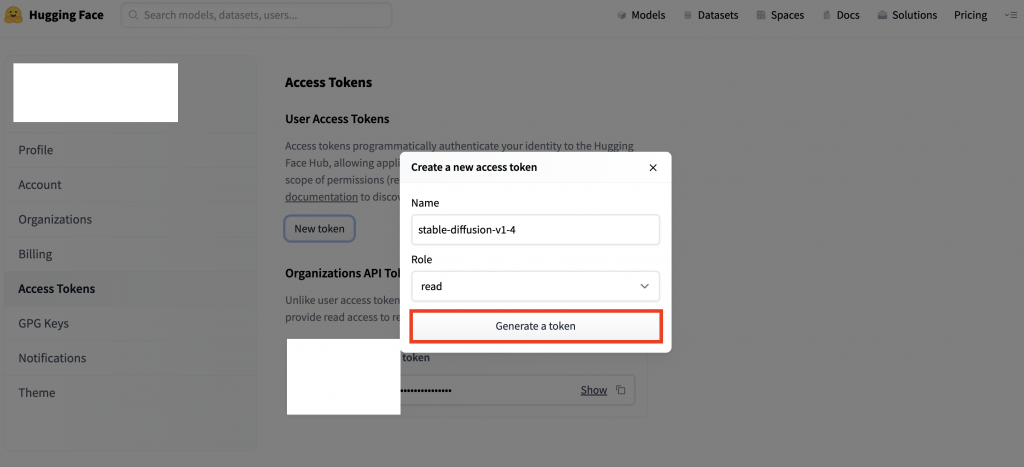
左メニューに[Access Tokens]に移動し「NewToken」ボタンよりNameに任意の名前を入力し「Generate Token」よりトークン発行します。今回Nameには「Stable-diffusion-v1-4」と入力しています。
Stable Diffusionのインストール
PythonからStable Diffusionを利用するために、GPU設定したGoogle Colabのセルに以下のコマンドを入力し、実行ください。
!pip install diffusers==0.8.0 transformers scipy ftfy
DiffusersはHuggingFaceが開発しているライブラリです。画像や音声に対応した事前学習済みの拡散モデルが提供されており、モデルのダウンロードを簡単に行うことが出来ます。今回はDiffusersを用いて、「stable-diffusion-v1-4」を読み込みます。
モデルの読み込み
先ほど発行したAPI鍵を変数access_tokenに指定し、以下のコードをColabに記載しコードを実行ください。
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
access_token = "<自分のAPI鍵>"
# モデルのダウンロード
model = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=access_token)
model.to("cuda")
これで事前準備は完了です。
テキストから画像を生成する
モデルの読み込みができたら、文章をモデルに渡すことで画像が生成してみます。
テキストから画像を生成するコードは以下になります
import matplotlib.pyplot as plt
num = 5 # 生成したい画像枚数
prompt = '''
girl,asian,white,beauty
''' # 生成させたい画像のプロンプト文章
for i in range(num):
model(prompt).images[0].save(f"outputs{i}.png") # 生成した画像を保存
# outputsフォルダに保存された画像を描画
plt.imshow(plt.imread(f"outputs{i}.png")) #生成した画像を確認
plt.axis('off')
plt.show()
print('処理完了')
promptは生成させたいもととなる文章です。任意の文章に変えてみてください。また、numという変数には生成枚数を指定しています。
このモデルは乱数シードを使用しているため、出力ごとに生成結果が変わります。なのでいい感じの画像が生成されるまでこれを繰り返します。ガチャをあたりが出るまで引き続けるイメージです
画像は、「content」直下に保存されています。中身を確認すると画像生成されています。
うち1枚は以下のような画像でした。

呪文についてはコツがあるらしく、うまく設定しないといい感じの画像を作るのは難しいです
参考:StableDiffusionでリアルな人物画像を生成するための呪文(プロンプト)ヒント集
また、日進月歩で新しい技術が登場することもあり、今回の記事で紹介した内容がすぐに古くなる可能性があります。そのため、ここで紹介しているコードが動作しなくなるなどの可能性も考えられますので、エラーが出た場合はエラーメッセージでググるなど必ず公式のWebページ等もご参考いただけますと幸いです。
<5/7 追記>
AUNTOMATIC1111というものを使用することでプログラムではなくUIからイラストを生成できるみたいです。
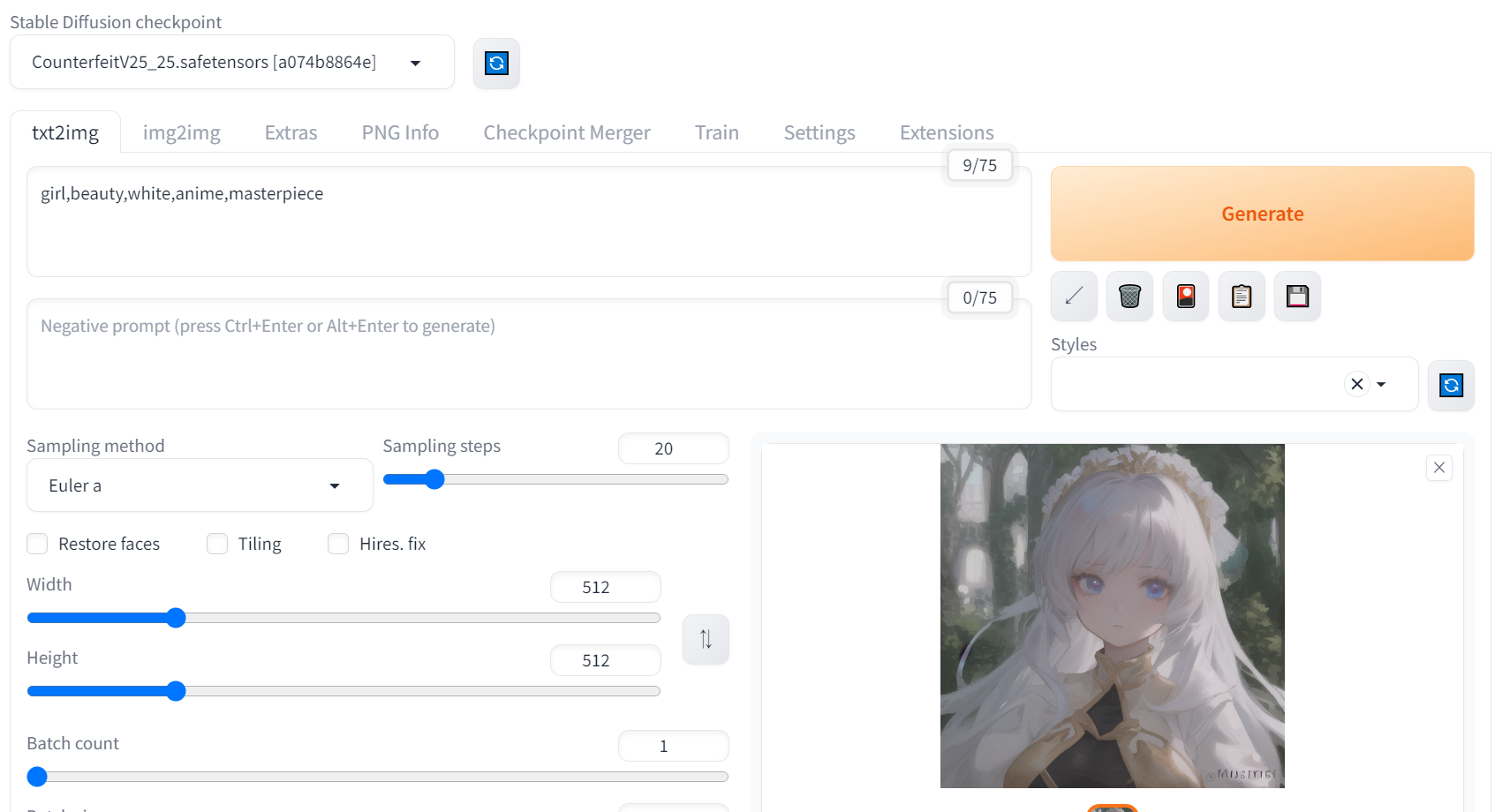
参照:【Python】GoogleColab上でStableDiffusion+LoRAで美少女イラストを生成する
関連記事:【Python】ChatGPTを使って画像を生成してみた
関連記事:Pythonを使ってChatGPTと会話するサンプルコード

コメント
[…] 参考記事:【Python】Stable Diffusionを使ってAI画像を生成するサンプルコード […]
[…] 関連記事:【Python】Stable Diffusionを使ってAI画像を生成するサンプルコード […]