
前回までにやったこと

前回はデータフレームから特定の条件を満たす配列の抽出する方法を解説しました。今回はPandas.Series(Series)の操作とデータフレームの変換・読み込み・保存・欠損値の処理などについて説明していきます。
Seriesについて
PandasにはPandas.Dataframeの他にPandas.Seriesというクラスが用意されていて、Pandasのデータフレームの列のデータはSeriesという一次元のデータにして抜き出せます。前回の記事で使ったアヤメのデータだと列名を指定してデータを抽出すると、データフレームではなく↓みたいな数値と横に数字が振られているデータ配列が返ってきます。これがSeries(Pandas.Series)というやつです。

このSeriesは簡単に言えばNumPyのndarrayの一次元配列のようなものです。しかしNumPyのndarrayとは少し異なっていて代表的な違いとしては以下の3点があります。
①インデックスを番号以外で振ることができる。
②時間データを格納できる(PandasのTimeSeriesが扱える)
③オブジェクトそのものに名前をつけることができる。
というわけで実際に触ってみて確認していきます。
リストからPandas.Series型のデータを作成する
まずはSeris型のデータを作成します。リストの変数データをSeris型のデータは基本的にする際にはpd.Series()という関数で作成できます。
#Seriesのデータ配列を作成する example=pd.Series([3.5,3.0,3.2]) #前回のデータセットからSeriesを作成する example=sample['sepal width (cm)'][0:3] ※結果(どちらも一緒です) 0 3.5 1 3.0 2 3.2 Name: sepal width (cm), dtype: float64
引数indexを省略すると左側のラベル部分は0.1.2という数字が順番に割り当てられます。ラベルを付けたい場合は引数にindex=~と入れてラベルを入力します。これがnumpyのndarrayとの大きな違いですね。今回は適当にabcとしましたが、このindexを日付データをすると、時系列データが作れます。
example=pd.Series([3.5,3.0,3.2],index=['a','b','c']) ※結果 a 3.5 b 3.0 c 3.2 dtype: int64
次はこのラベルからデータを抽出します。ラベルの抽出は「.loc」でできます。
#b行のデータを抽出する
example=pd.Series([3.5,3.0,3.2],index=['a','b','c'])
example.loc['b']
※
b 3.0
他にも前回取り扱ったPandas.Dataframeの時と同じように、「:」を付けて範囲抽出も可能です。
example.loc['b':'c']
※結果
b 3.0
c 3.2
dtype: int64
またデータフレームと同じように「.iloc」位置からデータを抽出することも可能です。for文や関数などを作る際にはpythonの行番号は0から始まることに注意してください。
example.iloc[2] ※結果 3.2
そして、比較演算子と.loc[]を使ってデータフレームと同じように条件に合うデータのみを抽出することもできます。
#3じゃないならTrue、3ならFalseを返す
example!=3
※結果
0 True
1 False
2 True
Name: sepal width (cm), dtype: bool
#3ではないものを抽出する
example.loc[example!=3]
※結果
0 3.5
2 3.2
Name: sepal width (cm), dtype: float64
以上がPandas.Series(Seris)配列の基本的な処理方法です。まあデータフレームとあまり変わりませんね。実際の処理であれば、データフレームから.loc[]とかで抜きだしたSeris型の数値データをnumpy行列に変換して計算する~みたいな感じに使います。
時系列データみたいにラベルに意味があるデータの場合はnumpyだとラベルを付けられないので、Seriesのままにして処理するか、いったんnumpyにして計算処理してから、pd.Series()の引数にindexで再指定して作り直すなんてこともあります。
これでPandas.DataframeとPandas.Seriesについての一通りの説明が終わりました。次は実際にデータを使った処理を行っていきたいと思います。
Pandas.Seriesを結合してデータフレームの作成する
次はSeriesの結合してデータフレームを作ってみます。ちなみにPandas.Dataframeはpd.dataframe()という間数で作成できます。indexが縦、Columnsが横のラベルを指定する引数です。
#データフレームの作成 df=pd.dataframe( [1,2,3],[4,5,6],[7,8,9], index=['a1','a2','a3'], columns=['b1','b2','b3'])
改行しなくてもコードは有効ですが、改行した方が見やすいですし、エラーが出た時もどこがおかしいのか見直ししやすいので、書いているコードが長くなったときは改行しましょう。pythonでコードの途中で改行する場合は字下げする必要がありますが「JupyterNotebook」なら自動で行ってくれます。そして、実行結果は↓のようになります。
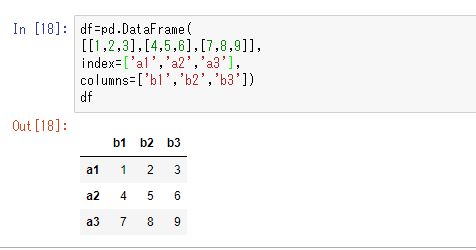
そして、Seriesを結合させてデータフレームを作成する場合は以下のように書きます。aとbの部分には任意の文字を入力できます。この時結合する2つのSeriesの長さが同じでないとエラーになるので注意してください。
#Seriesの作成
example=sample['sepal width (cm)'][0:10]
example2=sample['petal width (cm)'][0:10]
#Seriesからデータフレームを作る
df=pd.DataFrame({"a":example,"b":example2})
実行すると以下のような結果になると思います。こんな感じでSeriesからデータフレームを作ることができます。ちなみにこのpd.dataframe()はリストでもnumpyのndarrayでも一次元の数値配列で同じデータの長さであれば、使用することができるので非常に便利です。

まとめ
以上がpandasの基本的な操作方法です。pythonにおいてjupyter notebookとpandas・numpy・matplotlibはもはや知らないとモグリレベルの超大切かつ便利なツールとパッケージなので、使い方は是非マスターしておきましょう。
この辺の部分は「PythonユーザのためのJupyter[実践]入門」という参考書が現時点で一番分かりやすく解説してくれているので超オススメです。




コメント