
Pythonで世界各国の人口データを取得する
先日株価分析に人口データを用いたいと思いまして、pandas-datareaderとかでうまいこと取得できないかなーと色々検索していたのですが、国別にうまく取得できるサイトが中々見つからず苦労していたのですが、先日目途が立ったのでとりあえずまとめてみました。
今回は世界経済のネタ帳というサイトからPythonを使ったスクレイピングでアジア各国の人口データとGDPを取得してみます。
流れとしては、requestsでスクレイピングしてBeautifulSoupでHTMLから必要なデータを抽出。Pandasで整形してMatplotlibで描画といった感じになります。
関連記事:PythonでのWebスクレイピングには「requests」がめっちゃ便利という話
関連記事:【Python】「Beautiful Soup」でスクレイピングしたhtmlデータを解析する
関連記事:【Python】Matplotlibでのグラフ作成の基本をわかりやすく解説する
<実行環境>
- Windows10
- Python3.7
- JupyterLab
# ライブラリの呼び出し
import requests
import json
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
def get_tabledata(url='https://ecodb.net/ranking/old/area/A/imf_ngdpd', start=1980, end=2018):
"""
世界経済のネタ帳からスクレイピングでデータを取得する関数
url{str} : forでループさせる大元のURL
start {int/str} : 開始年数(1980年がより前のデータはなさそう)
end {int/str} : 終了年数(現在の年数-2、前年のデータはURLの仕様が少し違うので、別でスクレピングする必要あり)
"""
data_dict = {}
for year in range(start, end):
# 対象ページのHTMLデータを取得&BS4形式に変換
res = requests.get(f'{url}_{year}.html')
data = BeautifulSoup(res.text,'html.parser')
# htmlの中からtableタグを抽出する
data_table = data.find('table')
# テーブルから1列ずつ国名と数値を抜き出す
country_dict = {}
for row in range(len(data_table.find_all('tr'))):
country = data_table.find_all('tr')[row]
# 最初の1と2はアジア合計と世界合計の列で他とタグが若干異なっているのでIF文で処理
if row == 1:
asia_sum_ = country.find('td', class_='value').text.replace(',', '').replace("'", '')
# 辞書にKEYと値を追加する
country_dict['アジア合計'] = float(asia_sum_)
if row == 2:
world_sum_ = country.find('td', class_='value').text.replace(',', '').replace("'", '')
# 辞書にKEYと値を追加する
country_dict['世界合計'] = world_sum_
# それ以外の国名の列は同じように処理
else:
try:
# 国名とGDPを取得して辞書に追加していく
country_name = country.find('td', class_='name tap').text.replace('\n', '').replace('\xa0', '')
gdp = country.find('td', class_='value value_bar_chart').text.replace(',', '')
country_dict[country_name] = float(gdp)
except Exception as e:
pass
# 各年代のアジア各国のデータ数値({国名:数値}の辞書データを辞書の中に追加する
data_dict[str(year)] = country_dict
return data_dict
# 関数を実行してデータを取得する
people_data = get_tabledata(url='https://ecodb.net/ranking/old/area/A/imf_lp_', start=1980, end=2018)
gdp_data = get_tabledata(url='https://ecodb.net/ranking/old/area/A/imf_ngdpd_', start=1980, end=2018)
このコードだとfor文で回しているURLの仕様上で最新の年のデータが取得できません。いずれgitに完成版をアップロードするつもりですが、これでも40年分くらいのデータは集められるので、十分使えると思います。
<実行結果>は↓のような感じ
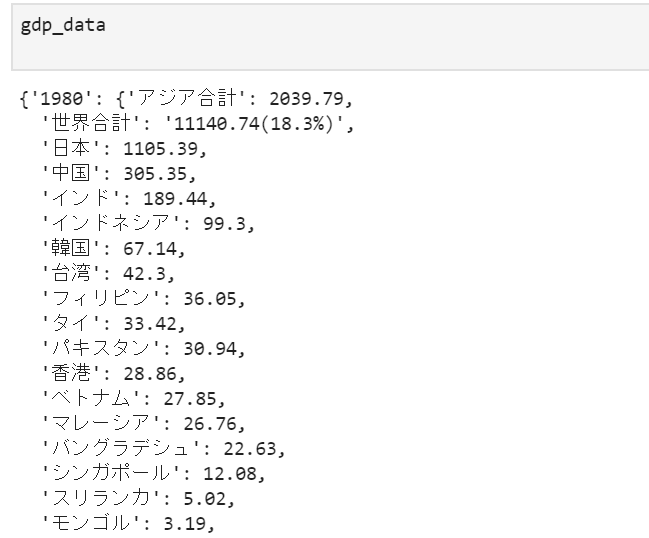
これをデータフレームに整形します
# アジアの国のリストを作成する
asia_list = list(gdp_data['1980'].keys())
people_dict = {}
gdp_dict = {}
for country in asia_list:
p_data, g_data = [], []
for year in people_data.keys():
try:
p_data.append(people_data[year][country])
except:
p_data.append('NaN')
people_dict[country] = p_data
for year in gdp_data.keys():
try:
g_data.append(gdp_data[year][country])
except:
g_data.append('NaN')
gdp_dict[country] = g_data
# 辞書からデータフレームに変換する
df_people = pd.DataFrame(people_dict.values(), index=people_dict.keys())
df_people.columns = range(1980, 2018)
df_gdp = pd.DataFrame(gdp_dict.values(), index=gdp_dict.keys())
df_gdp.columns = range(1980, 2018)
# csv出力
df_people.to_csv('asia_population.csv', encoding='SJIS')
df_gdp.to_csv('asia_gdp.csv', encoding='SJIS')
次はこれをMatplotlibでプロットします。
# データをJupyterNotebookでプロットする場合 #
from pylab import rcParams
rcParams['figure.figsize'] = 10, 20
for i in df_gdp.index[2:]:
try:
plt.plot(df_gdp.loc[i], label=i)
except:
pass
plt.title('アジア各国の年代別GDP推移')
plt.grid(which='both')
plt.legend()
plt.show()
<実行結果>
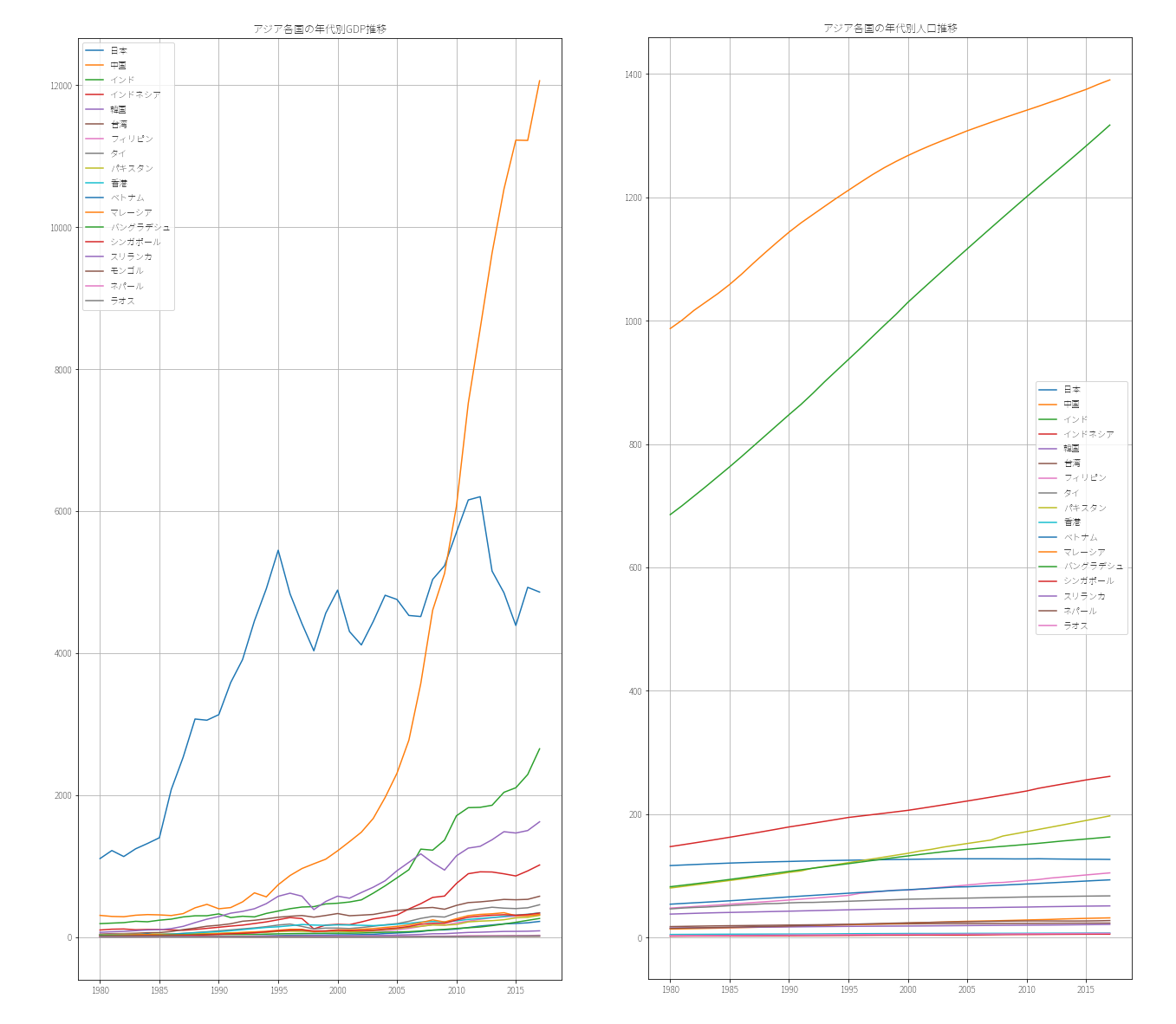
人口とGDP共に中国の伸びがすごいですね(小並感)
他にもインド・インドネシア・タイ・ベトナム辺りも伸びてきています。
関連記事:【Python】CoinGeckoのAPIからビットコイン・アルトコインの価格データを取得する
関連記事:【Python】TwitterのAPIを簡単操作できる「Tweepy」の使い方
関連記事:【Python】Quandlから上場企業の株価データを取得する
関連記事:【Python】pandasで日経平均の株価データをスクレイピングする

コメント