
こんにちは、ミナピピン(@python_mllover)です。今回はMENTAでYoutubeの特定の動画に紐づいているコメントを全件取得してほしいという依頼を受けたので調べた結果をまとめておこうかなと思います。
関連記事:【Python】YoutubeのAPIを叩いて色んな動画情報を取得してみる
YoutubeAPIを使ったコメント取得について
まず結論からいうとYoutubeのコメントは数千件を取得するのが限界で数万件のコメントを取得するのはAPIの仕様上不可能だと思われます。
基本的に動画のコメントは1回のAPIアクセスにつき、100件を上限に取得することができます。加えてAPIのレスポンスに含まれているnextPageTokenを使用することで、100件×20回の合計2000件取得することが可能です。
これはコメントスレッド(親コメント)の上限数で、これらにコメントに返信がついている場合、その2000件に紐づいている返信(子コメント)も取得することができ、親コメントと子コメントを合わせて合計で~6000件くらい取得することができます。
Youtubeの動画コメントをAPIで全件取得してCSV保存
以下がPythonで記述した実際のコードになります。
# ライブラリの読み込み
import pandas as pd
import requests
from typing import Dict
import requests
import json
URL = 'https://www.googleapis.com/youtube/v3/'
API_KEY = '自分のAPI鍵'
# 1つ目の動画のコメント情報を取得
VIDEO_ID = 'コメントを取得したいID'
def print_video_comment(no, video_id, next_page_token, text_data):
params = {
'key': API_KEY,
'part': 'snippet',
'videoId': video_id,
'order': 'relevance',
'textFormat': 'plaintext',
'maxResults': 100,
}
if next_page_token is not None:
params['pageToken'] = next_page_token
response = requests.get(URL + 'commentThreads', params=params)
resource = response.json()
for comment_info in resource['items']:
# コメント
text = comment_info['snippet']['topLevelComment']['snippet']['textDisplay']
# グッド数
like_cnt = comment_info['snippet']['topLevelComment']['snippet']['likeCount']
# 返信数
reply_cnt = comment_info['snippet']['totalReplyCount']
# ユーザー名
user_name = comment_info['snippet']['topLevelComment']['snippet']['authorDisplayName']
# Id
parentId = comment_info['snippet']['topLevelComment']['id']
# ユーザープロフィール情報
author_channel = comment_info["snippet"]['topLevelComment']['snippet']['authorChannelUrl']
# リストに取得した情報を追加
text_data.append([parentId, 'parent', text, like_cnt, reply_cnt, user_name, author_channel])
# 処理確認用
if len(text_data) % 100 == 0:
print(len(text_data))
# print('{:0=4}\t{}\t{}\t{}\t{}'.format(no, text.replace('\n', ' '), like_cnt, user_name, reply_cnt))
if reply_cnt > 0:
cno = 1
print_video_reply(no, cno, video_id, next_page_token, parentId, text_data)
no = no + 1
if 'nextPageToken' in resource:
print_video_comment(no, video_id, resource["nextPageToken"], text_data)
def print_video_reply(no, cno, video_id, next_page_token, id, text_data):
params = {
'key': API_KEY,
'part': 'snippet',
'videoId': video_id,
'textFormat': 'plaintext',
'maxResults': 50,
'parentId': id,
}
if next_page_token is not None:
params['pageToken'] = next_page_token
response = requests.get(URL + 'comments', params=params)
resource = response.json()
for comment_info in resource['items']:
# コメント
text = comment_info['snippet']['textDisplay']
# グッド数
like_cnt = comment_info['snippet']['likeCount']
# ユーザー名
user_name = comment_info['snippet']['authorDisplayName']
# ユーザープロフィール情報
author_channel = comment_info["snippet"]['authorChannelUrl']
# リストに取得した情報を追加
text_data.append([id, 'child', text, like_cnt, 0, user_name, author_channel])
# print('{:0=4}-{:0=3}\t{}\t{}\t{}'.format(no, cno, text.replace('\n', ' '), like_cnt, user_name))
cno = cno + 1
if 'nextPageToken' in resource:
print_video_reply(no, cno, video_id, resource["nextPageToken"], id, text_data)
text_data=[]
# コメントを全取得する
video_id = VIDEO_ID
no = 1
# 取得処理を実行
print_video_comment(no, video_id, None, text_data)
# データフレーム作成(高評価順にソート)
df = pd.DataFrame(text_data, columns=['comment_id', 'type', 'comment_data', 'like_cnt', 'reply_cnt', 'user_name', 'profile_page']).sort_values('like_cnt', ascending=False)
# csv出力
df.to_csv('youtube_comment.csv', index=False)
# データフレームを一部出力して確認する
df.head()
<実行結果>
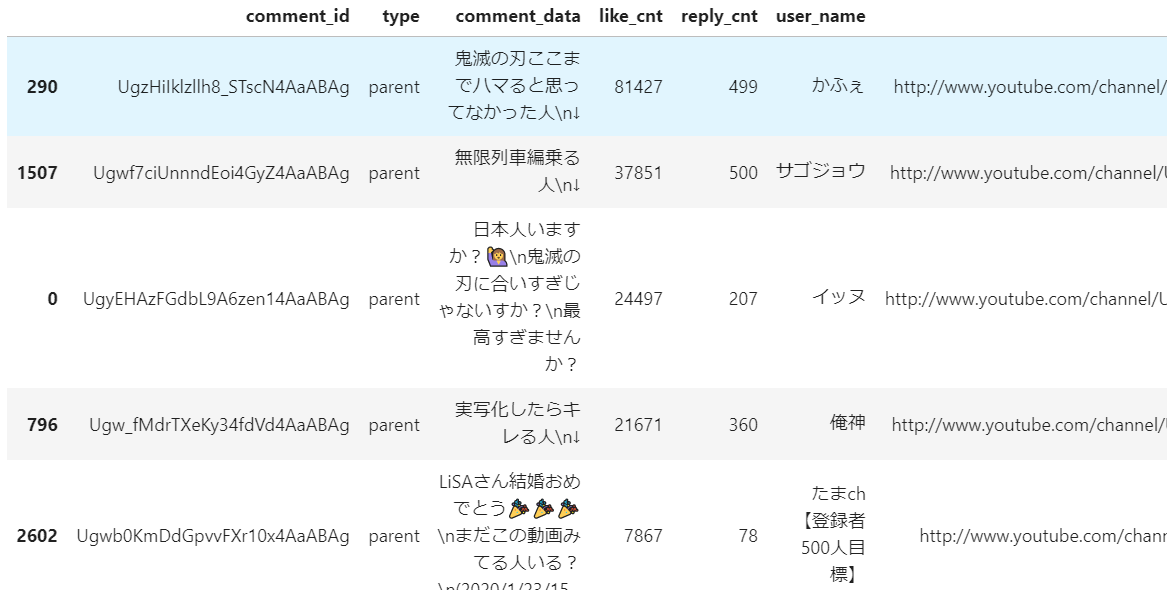
YoutubeのAPIの基本的な叩き方は別の記事で解説しているので、そちらを参考にしてください。
今回のコードのミソとしてはまずprint_video_comment()でコメント取得のAPIを一回叩くことで最大100件のコメントを取得することができます。100件以上ある場合は[“nextPageToken”]もAPIレスポンスで返されてくるので、それを使い&pageToken=にその値を入れてURLに付与することにより100件より先のコメントの続きを取得ことができます。
また、これで取得したコメントは親コメントと言われる部類のもので、それに返信があった場合、返信コメント(子コメント)が存在してます。[“totalReplyCount”]が1以上であれば子コメントが存在するので、print_video_reply()で取得する処理を行っています。件数が多い場合は先ほどと同じくpageTokenを使いできるかぎり取得しています。
コメントが数万件ある場合でも全件取得できる方法がもしありましたらツイッターやコメント欄などで教えていただけると幸いです。では~
関連記事:【Python】Youtubeの再生数・コメント数・高評価数をスクレイピングで取得する
関連記事:【Python】youtube-dlでmp4/mp3をYoutubeからダウンロードする
参照:http://sleepyokayu.blogspot.com/2018/04/youtube_12.html
参照:https://qiita.com/yaju/items/3bec88dbd544502e1343


コメント
[…] 関連記事:【Python】Youtubeの動画コメントをAPI経由で全件取得する […]
[…] 関連記事:【Python】Youtubeの動画コメントをAPI経由で全件取得する […]
98行エラーですね。
movie_data.titleという変数が宣言無いので。
エラーが出ないように修正しました
ご指摘ありがとうございます。
[…] 関連記事:【Python】Youtubeの動画コメントをAPI経由で全件取得する […]