
こんにちは、ミナピピン(@python_mllover)です。
今回はTweepyで2021年に新しく公開されたTwitterAPI V2のAPI鍵を使ってツイートする方法を紹介したいと思います。(Tweepyのバージョンは4.0以上である必要があります。)
2023年からTwitter APIは有料化され、今回のユーザーのツイート(タイムライン)取得する場合はBASICプラン(100$/月)を契約している必要があります
Contents
前準備
まずライブラリをインストールしていない場合はPIPでインストールします
# 最新バージョンをインストール $ pip install tweepy --upgrade
LOOKUPでユーザーの内部IDを確認する
Twitterでユーザーのツイートを取得するためにはユーザータイムラインをAPIを使用します。これにはまず Users lookupでユーザーの内部ID(@~~ではない)を取得する必要があります。コードは↓
# Users lookup endpointを叩く
import requests
import tweepy
username= "<@以降のアカウントID>"
bearer_token = "<自分のbearer_token(BASICに切り替えて再生成したもの)>"
url = f"https://api.twitter.com/2/users/by/username/{username}"
headers = { "Authorization": f"Bearer {bearer_token}" }
response = requests.get(url, headers=headers)
if response.status_code == 200:
user_data = response.json()["data"]
user_id = user_data["id"]
print(f"User ID for {username}: {user_id}")
else:
print(f"Error {response.status_code}: {response.text}")
TweepyでTwitterAPI_V2のユーザータイムラインAPIを叩く
上記で変数user_idに格納された対象ユーザーの内部IDを使ってusertimelineのエンドポイントを叩きます
# OAuth 2.0 Bearer Token 認証情報付きのアクセスクライアント
client_oath_20_bearer_token = tweepy.Client(
bearer_token=bearer_token
)
params = {
"expansions": "attachments.media_keys,author_id",
"tweet.fields": "created_at,text,public_metrics",
"media.fields": "media_key,url,type",
"user.fields": "name,username,description,public_metrics"
}
results = []
count = 0
lcount = 0
pagination_token =""
tweets = client_oath_20_bearer_token.get_users_tweets(user_id,
max_results=20,
tweet_fields="entities,referenced_tweets,created_at,text,public_metrics",
expansions="attachments.poll_ids,attachments.media_keys,author_id",
media_fields="media_key,url,type,variants",
user_fields= "name,username,description,public_metrics",
exclude="retweets",
)
print(tweets.data)
ツイートに関するデータはtweets.dataに格納されています
パラメーター解説
- user_id:
- 取得するユーザーのID。Twitterの各アカウントには一意のIDが割り当てられており、このIDを指定することで特定のユーザーのツイートを取得できます。
- max_results:
- 一度のリクエストで取得するツイートの最大数。この例では20と指定していますので、最新の20ツイートを取得します。
- tweet_fields:
- 取得するツイートの属性を指定します。
entities: ツイート内のエンティティ(URLs, ハッシュタグ, メンションなど)の詳細情報。referenced_tweets: 当該ツイートが返信や引用の場合、元となるツイートの情報。created_at: ツイートの投稿日時。text: ツイートの本文。public_metrics: ツイートの公開メトリクス(いいね数、リツイート数など)。
- expansions:
- 追加の情報を取得したい場合に使用するパラメータ。
attachments.poll_ids: ツイートに添付された投票のID。attachments.media_keys: ツイートに添付されたメディア(画像、動画など)のキー。author_id: ツイートしたユーザーのID。
- media_fields:
media_key: 各メディアの一意のキー。url: メディアのURL。type: メディアのタイプ(画像、動画など)。variants: 動画の場合の異なる品質やフォーマットの情報。
- user_fields:
- 取得するユーザー情報の属性を指定します。
name: ユーザーの表示名。username: ユーザーのスクリーンネーム。description: ユーザープロフィールの説明文。public_metrics: ユーザーの公開メトリクス(フォロワー数、フォロー中の数など)。
- exclude:
- 特定のタイプのツイートを結果から除外します。この例では、リツイートを結果から除外しています。
この関数を使用することで、指定されたユーザーIDのツイートとそれに関連する追加情報を取得できます。
ツイートデータをデータフレームに加工する
次にここから各データを取り出してデータフレームに変換します
import pandas as pd
import datetime
for tweet in tweets.data:
tweet_time = datetime.datetime.fromisoformat(str(tweet.created_at).replace("Z", "+00:00"))
# JSTに変換
jst_timezone = pytz.timezone('Asia/Tokyo')
tweet_time_jst = tweet_time.astimezone(jst_timezone)
# 年-月-日 時:分:秒の形式で秒まで表示
jdate = tweet_time_jst.strftime('%Y-%m-%d %H:%M:%S')
# 'date'x, 'user_name'x, 'user_id'x, 'tweet_url'x, 'tweet_id'x, 'base_tweet_id'x, 'tweet_type'x,'text'x,'favx', 'rt'x, 'link'x, 'img_url', 'movie_url'
# 基本情報
result = {
"tweet_url": f"https://twitter.com/{tweet.author_id}/status/{tweet.id}",
"user_id":username, #@~~~~
'tweet_id':tweet.id,
"date": jdate,
"text": tweet.text,
"rt": tweet.public_metrics["retweet_count"],
"fav": tweet.public_metrics["like_count"],
"img_url": None,
"img2": None,
"img3": None,
"img4": None,
"movie_url":None
}
# ユーザー情報
user = tweets.includes["users"][0]
result["user_name"] = user.name #ユーザー名
result["screen_name"] = user.username
result["profile_text"] = user.description
result["ff_count"] = user.public_metrics["followers_count"]
# リプライかどうかの判断と親ツイートのURL取得
result["tweet_type"] = None
result["base_tweet_id"] = None
try:
result["base_tweet_id"] = tweet.get("referenced_tweets", [])[0].id
result["tweet_type"] = "child"
except:
result["tweet_type"] = "parent"
result["base_tweet_id"] = tweet.id
# 外部リンク
result['link'] = None
try:
outer_url = tweet.entities["urls"][0]['expanded_url']
if "twitter.com" not in outer_url:
# print(outer_url)
result['link'] = outer_url
except:
print("リンク無し")
pass
# メディア情報
if "attachments" in tweet:
images = []
for media in tweets.includes["media"]:
if media.media_key in tweet.attachments["media_keys"] and media.type== "photo":
images.append(media.url)
# print(media.url)
elif media.type == "video":
# 動画URLは直接得られないため、動画の情報を参照するURLとなる
# print("Video Info URL:", media.url,media.variants)
for m in media.variants:
# print(m)
if m['content_type']=='video/mp4':
result["movie_url"]=m["url"].split("?")[0]
for i, img in enumerate(images):
result[f"img{i+1}_url"] = img
print(result["movie_url"])
print("ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー")
results.append(result)
df = pd.DataFrame(results)
print(df)
サンプルコード
これらをまとめると以下のようになります。下記ではループの2回目からntil_id = oldest_id で前回取得したものより古いツイートを指定することでページネーションを加味しています
oldest_id =""
for i in range(2):
if oldest_id !="":
tweets = client_oath_20_bearer_token.get_users_tweets(user_id,
max_results=50,
tweet_fields="entities,referenced_tweets,created_at,text,public_metrics",
expansions="attachments.poll_ids,attachments.media_keys,author_id",
media_fields="media_key,url,type,variants",
user_fields= "name,username,description,public_metrics",
exclude="retweets",
until_id = oldest_id #2回目からは前のループで取得したoldest_idより古いものだけを指定
)
else:
tweets = client_oath_20_bearer_token.get_users_tweets(user_id,
max_results=50,
tweet_fields="entities,referenced_tweets,created_at,text,public_metrics",
expansions="attachments.poll_ids,attachments.media_keys,author_id",
media_fields="media_key,url,type,variants",
user_fields= "name,username,description,public_metrics",
exclude="retweets",
)
result_count = tweets.meta['result_count']
print(f"{result_count}件のツイートを取得しました")
for tweet in tweets.data:
tweet_time = datetime.datetime.fromisoformat(str(tweet.created_at).replace("Z", "+00:00"))
# JSTに変換
jst_timezone = pytz.timezone('Asia/Tokyo')
tweet_time_jst = tweet_time.astimezone(jst_timezone)
# 年-月-日 時:分:秒の形式で秒まで表示
jdate = tweet_time_jst.strftime('%Y-%m-%d %H:%M:%S')
# 'date'x, 'user_name'x, 'user_id'x, 'tweet_url'x, 'tweet_id'x, 'base_tweet_id'x, 'tweet_type'x,'text'x,'favx', 'rt'x, 'link'x, 'img_url', 'movie_url'
# 基本情報
result = {
"tweet_url": f"https://twitter.com/{tweet.author_id}/status/{tweet.id}",
"user_id":username, #@~~~~
'tweet_id':tweet.id,
"date": jdate,
"text": tweet.text,
"rt": tweet.public_metrics["retweet_count"],
"fav": tweet.public_metrics["like_count"],
"img_url": None,
"img2": None,
"img3": None,
"img4": None,
"movie_url":None
}
# ユーザー情報
user = tweets.includes["users"][0]
result["user_name"] = user.name #ユーザー名
result["screen_name"] = user.username
result["profile_text"] = user.description
result["ff_count"] = user.public_metrics["followers_count"]
# リプライかどうかの判断と親ツイートのURL取得
result["tweet_type"] = None
result["base_tweet_id"] = None
try:
result["base_tweet_id"] = tweet.get("referenced_tweets", [])[0].id
result["tweet_type"] = "child"
except:
result["tweet_type"] = "parent"
result["base_tweet_id"] = tweet.id
# 外部リンク
result['link'] = None
try:
outer_url = tweet.entities["urls"][0]['expanded_url']
if "twitter.com" not in outer_url:
# print(outer_url)
result['link'] = outer_url
except:
print("リンク無し")
pass
# メディア情報
if "attachments" in tweet:
images = []
for media in tweets.includes["media"]:
if media.media_key in tweet.attachments["media_keys"] and media.type== "photo":
images.append(media.url)
# print(media.url)
elif media.type == "video":
# 動画URLは直接得られないため、動画の情報を参照するURLとなる
# print("Video Info URL:", media.url,media.variants)
for m in media.variants:
# print(m)
if m['content_type']=='video/mp4':
result["movie_url"]=m["url"].split("?")[0]
for i, img in enumerate(images):
result[f"img{i+1}_url"] = img
print(result["movie_url"])
print("ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー")
results.append(result)
oldest_id = tweets.meta["oldest_id"]
df = pd.DataFrame(results)
print(df)
oldest_id = "": 最も古いツイートのIDを保存する変数を初期化します。この変数を使って、次回のAPIリクエストでどのツイート以前のものを取得するかを指定します。oldest_id = tweets.meta["oldest_id"]で一番古いツイートのIDを確認if oldest_id != ""::oldest_idが空でない場合、すなわち2回目のリクエストのときの処理。tweets = client_oath_20_bearer_token.get_users_tweets(...):tweepyを使用して、指定したユーザーのツイートをAPIから取得します。until_id = oldest_id: 最も古いツイートのIDより前のツイートを取得します。
else::oldest_idが空の場合、すなわち1回目のリクエストのときの処理。
上記ではループが2回なので100件取得できる想定です。また2023年10月現在 Twitter APIのBASICプランだとユーザーのツイートは月10000ツイートまで取得可能です
まあAPIの制限は大分キツイのでSeleniumを使用するのも手段の1つだと思います
関連記事:Twitterメディアダウンローダーでユーザーの画像情報を収集しよう!
注意点
ツイートするためにはDeveloper Portalの「User authentication settings」で、アプリケーションレベルのパーミッション(App permissions)がRead and writeか「Read and write and Direct message」でないといけません。(初期値はRead)
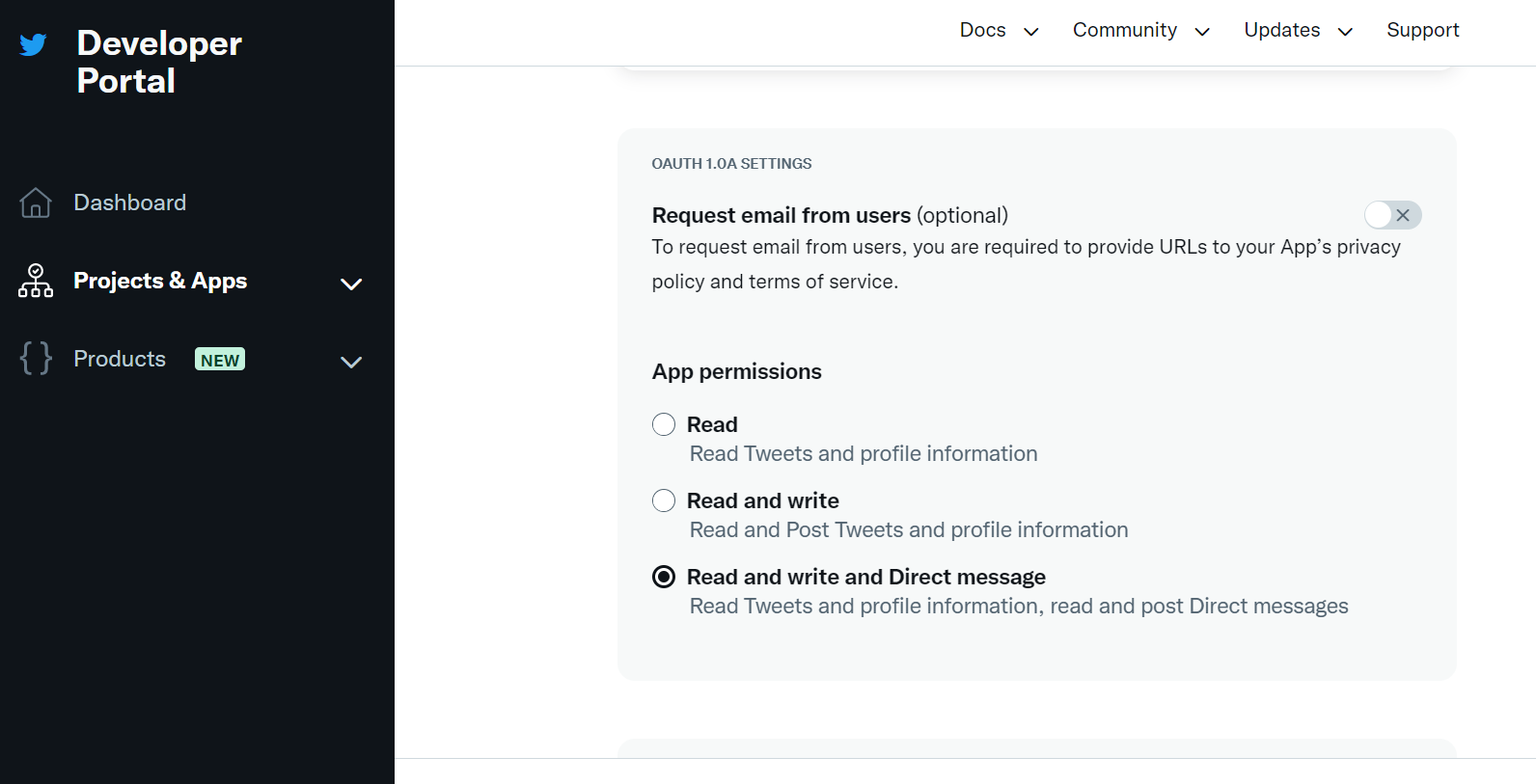
加えて、APIのツイート読み取り/書き込み/DM送信の権限変更は↑のパーミッション設定を変更しただけでは反映されないので都度、apikey/apisecret/Access Token/AccessTokenSecretをrevokeもしくはregenerateで再生成する必要があるので注意です。
関連記事:【Python】Tweepyで特定ユーザーの過去ツイートをスクレイピングで自動取得する
関連記事:【Python】TwitterのDM送信をTweepyで自動化する
関連記事:【Python】TwitterAPI V2のBearer tokenを使ってツイート検索をしてみる

参考:https://qiita.com/penguinprogrammer/items/b220be0c203eaaad015a
コメント
[…] 関連記事:【Python】TweepyでTwitterAPI_V2のAPIを使ってツイートするサンプルプログラム […]
[…] 参照:【Python】TweepyでTwitterAPI_V2のAPIを使ってツイートするサンプルプログラム […]