
今回はicrawlerというライブラリでウェブから画像を一括でダウンロード・スクレイピングするサンプルコードを紹介したいと思います。
ライブラリのインストール
# icrawlerをインストールする $ pip install icrawler
icrawlerで画像を自動ダウンロード
from icrawler.builtin import BingImageCrawler
search_keyword = '内田真礼 声優'
#1---任意のクローラを指定
crawler = BingImageCrawler(storage={"root_dir": search_keyword.strip()})
#2---検索内容の指定
crawler.crawl(keyword=search_keyword, max_num=10)
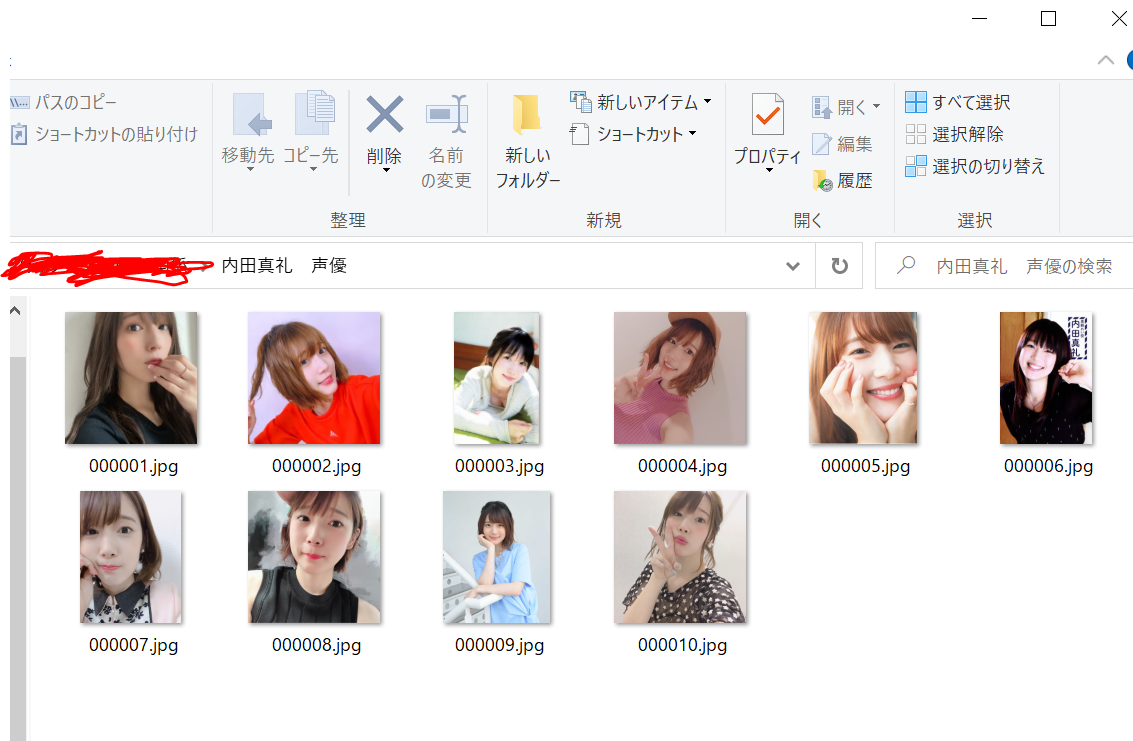
<実行結果>
関連記事:CentOSのVPSサーバーでPython+Selenium+ChromeDriverのスクレイピング環境を構築する

コメント
[…] 関連記事:【Python】icrawlerで画像検索結果を一括ダウンロード・スクレイピングする […]