
前回のユーザーベース/アイテムベースの協調フィルタリング引き続きレコメンドアルゴリズムで有名な「Matrix Factorization(行列因子分解)」について紹介していきます。
Matrix Factorization(行列分解)の概要
行列因子分解から分かる通り、マトリックス(行列)を分解して、ユーザーとアイテム間の潜在的な特徴を発見するための手法です。
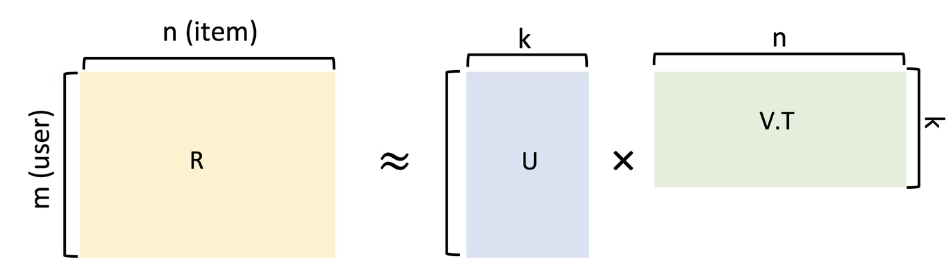
参照:https://qiita.com/michi_wkwk/items/52660778ad6a900965ee
行列分解(特異値分解)によるレコメンドアルゴリズムにはSVDやNVSVがありますが、MFはこれらよりも精度が良い傾向にあるとされています。
前準備
使用するデータは前回に引き続いてkaggleのアニメの視聴履歴と評価履歴になります。
データセット→ Anime Recommendations Database | Kaggle
ダウンロードにはkaggleのアカウント登録が必要です。
import numpy as np
import pandas as pd
df_rating = pd.read_csv(r"C:\Users\~~\archive\rating.csv")
df_label = pd.read_csv(r"C:\Users\~~\archive\anime.csv")
MatrixFacterizationはQiitaなどでハンズオンで実装している記事もありましたが、PYPLを調べたところ有志の方がライブラリを作ってくれていたので、そちらを使いたいと思います。
# ライブラリのインストール $ pip install matrix-factorization
ドキュメント:https://pypi.org/project/matrix-factorization/
GIT:https://github.com/Quang-Vinh/matrix-factorization/blob/master/README.md
PythonでMatrix Factorizationによるレコメンド予測を実装
from matrix_factorization import BaselineModel, KernelMF, train_update_test_split
import pandas as pd
from sklearn.metrics import mean_squared_error
df_rating = pd.read_csv(r"C:~~\rating.csv")
df_rating.columns=['user_id', 'item_id', 'rating']
df_rating = df_rating.drop_duplicates(subset=["user_id", "item_id"])
# データを訓練用 テスト用 検証用に分類する(区分はデータに合わせて任意変更してください)
X_train_initial = df_rating[['user_id', 'item_id']].iloc[:2000000,]
y_train_initial = df_rating['rating'].iloc[:2000000,]
X_train_update = df_rating[['user_id', 'item_id']].iloc[2000000:5000000,]
y_train_update = df_rating['rating'].iloc[2000000:5000000,]
X_test_update = df_rating[['user_id', 'item_id']].iloc[5000000:,]
y_test_update = df_rating['rating'].iloc[5000000:,]
# 訓練開始
matrix_fact = KernelMF(n_epochs=20, n_factors=100, verbose=1, lr=0.001, reg=0.005)
matrix_fact.fit(X_train_initial, y_train_initial)
# テストデータで重みを更新
matrix_fact.update_users(
X_train_update, y_train_update, lr=0.001, n_epochs=20, verbose=1
)
pred = matrix_fact.predict(X_test_update)
rmse = mean_squared_error(y_test_update, pred, squared=False)
print(f"\nTest RMSE: {rmse:.4f}")
# 評価値の予測
user = 200 #予測したいユーザーID
items_known = X_train_initial.query("user_id == @user")["item_id"]
matrix_fact.recommend(user=user, items_known=items_known)
<実行結果>
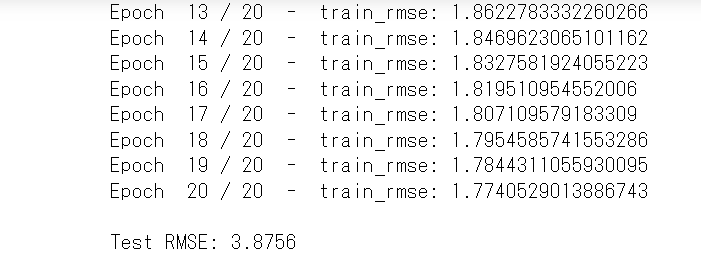
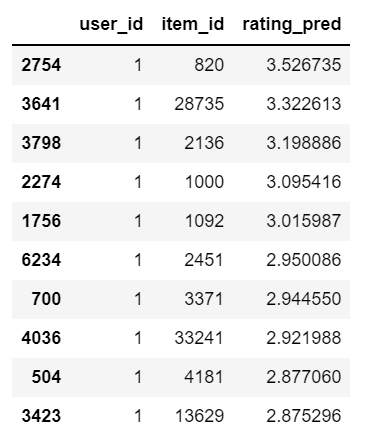
こんな感じに各ユーザーごとに未視聴のアニメに対する評価値を予測することができます。
item_idのマスタはdf_labelにあるので内部結合なりくっつけるとアニメのタイトルが確認できます。
・行列分解についてまとまっていた記事(保存用)
https://rf00.hatenablog.com/entry/2018/05/20/194121
https://www.takapy.work/entry/2020/12/10/090131


コメント