
こんにちはミナピピン(@python_mllover)です!今日はかつてKaggleの機械学習系アルゴリズムで、最強の座にもっとも近かった「XGBoost」について紹介していきたいと思います
XGBoostとは?
xgboostは、決定木モデルの1種であるGBDTを扱うライブラリです。正式名称は「Gradient Boosting Decision Tree」。日本語だと「勾配ブースティング」というやつです。
xgboostの特徴としては以下のようなものが挙げられます。
- 欠損値の補完が不要
- 冗長な特徴量があっても問題ない(相関が高い説明変数があってもそのまま使える)
- ランダムフォレストや普通の決定木より生成モデルの精度が高い傾向にある
実際に学習で使ってもらえばわかりますが、とにかくこいつは適当に特徴量作って投げるだけでそこそこ良い結果になるというのが大きな特徴で、kaggleなどで0.1%でも精度を上げたい場合なんかによく使います。実務だとchaidの決定木でとりあえずノードの分岐を見とけば丸く収まります。
同じ決定木モデルだと「ランダムフォレスト」が有名ですが、下記記事が違いを簡潔にまとめられていましたので、もう少し知りたい方は以下の記事が参考になるかと思われます。
参照記事:【機械学習】決定木モデルの違いをまとめてみた – Qiita
Pythonで実装してみる
① データの確認
というわけでさっそくPythonで「xgboost」を使った機械学習をやってみましょう。まずライブラリをインストールします。
# インストールしていない場合は新しくインストール $pip install xgboost
今回学習に使用するのは、皆さんおなじみのKaggleのタイタニックのデータです。以下のサイトから「titanic_train_mod.csv」と「titanic_test_mod.csv」をダウンロードしてください。
csvの中身は欠損値や特徴量を加工したタイタニックの乗客データです。特徴量エンジニアリングに関しては今回の話題ではないのでサクッと飛ばします。ダウンロードしたcsvは任意の場所に配置して、下記のpd.read_csvのパスを弄って読み込めるようにしておいてください。
# ライブラリの読み込み
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import xgboost as xgb
#データの読み込み(パスは自分の環境に合わせて変えてください)
train = pd.read_csv('~/titanic_train_mod.csv.csv')
test= pd.read_csv('~/titanic_test_mod.csv.csv')
②xgboostで機械学習する
まずはデータを説明変数と目的変数に分けてから訓練データと正解データに7:3で分割します。
#学習データを説明変数と目的変数に分ける data = train[["Pclass", "Sex", "Age", "Fare"]].values target = train['Survived'].values # データを訓練データと正解データに7:3で分ける X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.3, shuffle=True)
続いて分けたデータをXGB専用のデータ型に変換します。
dtrain = xgb.DMatrix(X_train, label=y_train) dtest = xgb.DMatrix(X_test, label=y_test)
# パラメーター設定
params = {'max_depth': 4, 'eta': 0.3,
'objective': 'binary:logistic','silent':1, 'random_state':1234,
# 学習用の指標 (RMSE)
'eval_metric': 'rmse',
}
#訓練データはdtrain、評価用のテストデータはdvalidと設定
watchlist = [(dtrain, 'train'), (dtest, 'eval')]
【パラメータの説明】
- objective:最小化させるべき損失関数の指定。デフォルトはlinear。
- max_depth:決定木の深さ
- eta:学習率
- silent:モデル実行のログのはき方の指定。デフォルトは0(ログを出力する)
- eval_metric:データの評価指標。rmseやloglossがある
関連記事:損失関数のパラメーター一覧
# モデル訓練
model = xgb.train(params,
dtrain,#訓練データ
early_stopping_rounds=20,
evals=watchlist,
)
- early_stopping_rounds:N回連続して評価指標が改善しなかったら学習を中断する
コンソールに表示されるのは各学習ごとの訓練データ・正解データの「rmse(平均平方二乗誤差)」です。基本的に誤差が学習回数が増えていくごとに減少していきますが、誤差が小さすぎると過学習している可能性があるので、学習回数や目安誤差の設定は各自で調整する必要があります。
#変数重要度を出力
mapper = {'f{0}'.format(i): v for i, v in enumerate(["Pclass", "Sex", "Age", "Fare"])}
mapped = {mapper[k]: v for k, v in model.get_fscore().items()}
xgb.plot_importance(mapped)
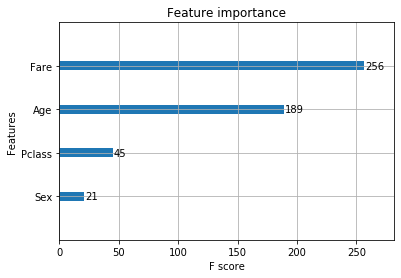
データフレームの4番目の変数 “Fare”=料金が効いていることが分かります。高い料金を払っている人に生き延びた人が多かったという結果となりました。
【おまけ】
graphvizがインストールされている場合、xgbostで作成した決定木を可視化することもできます。(ただgraphvizはOSによっては設定が厄介なのでエラーが出た人はスルーしてください)
# 決定木を可視化する
graph1 = xgb.to_graphviz(model)
graph1.format = 'png'
graph1.render('tree1')
関連記事:【Python】Window10でGaraphVizがインポートできないエラーの対処法
③モデル予測と精度確認
②まででモデル作成が完了したので、この作ったモデルをもとにテストデータの生存者を予測してみます。
#予測
prediction_XG = model.predict(xgb.DMatrix(test[["Pclass", "Sex", "Age", "Fare"]].values), ntree_limit = model.best_ntree_limit)
#小数を丸めて整数←これをしないとkaggleに提出しても正しく採点されない
prediction_XG = np.round(prediction_XG).astype(int)
# PassengerIdを取得
PassengerId = np.array(test["PassengerId"]).astype(int)
# my_prediction(予測データ)とPassengerIdをデータフレームへ落とし込む
my_result = pd.DataFrame(prediction_XG, PassengerId, columns = ["Survived"])
# xgb_result.csvとして書き出し
my_result.to_csv("xgb_result.csv", index_label = ["PassengerId"])
これで作業ディレクトリにxgb_result.csvが出力されています。そしてこのxgb_result.csvをhttps://www.kaggle.com/c/titanic/submitにアップロードしてmake submissionで採点してもらいます。
ちないに今回採点結果は以下のようになりました。
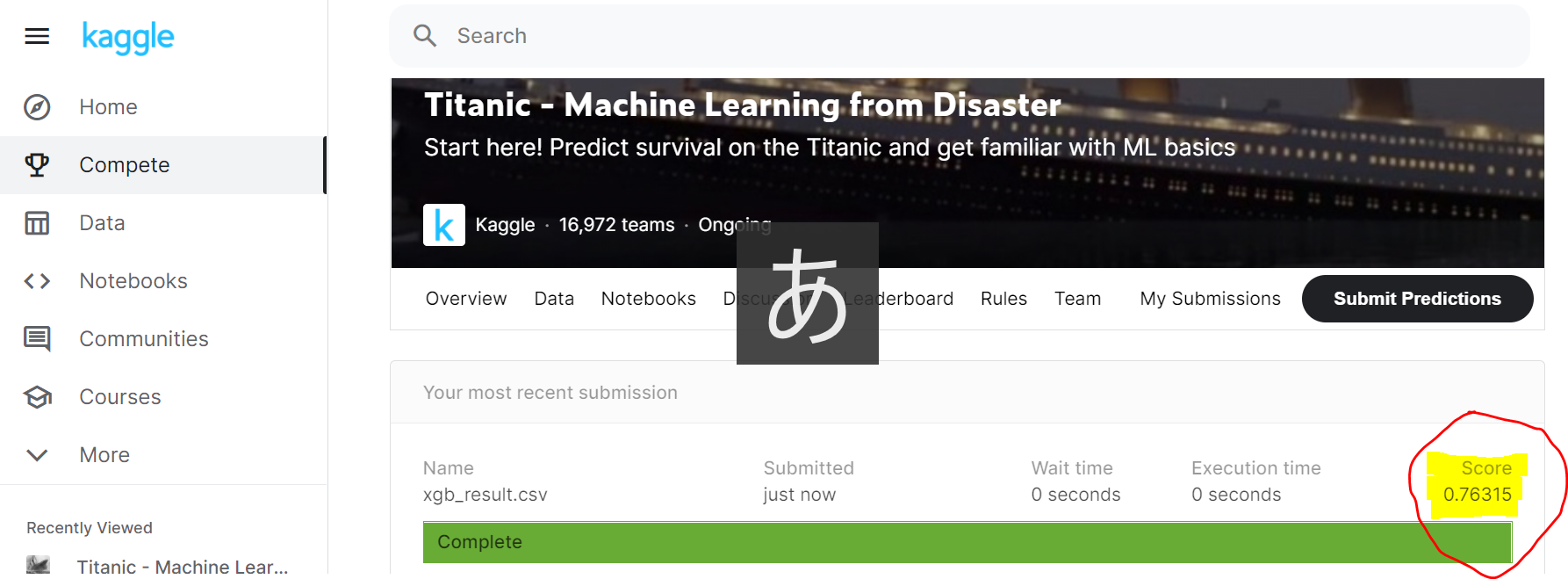
これ普通の決定木だと正答率7割くらいなのですが、アルゴリズムをXGBoostに変更するだけで76.3%と大きく跳ね上がりました。(ちなみに順位は13000位くらい・・・)
終わり
Kaggleのようなコンペでは、xgboostやLGBMといった勾配ブースティングがよく使われているので、とりあえずkaggleとか社内コンペとかがあったら、適当に特徴量処理してxgboostとlightgbm・catboostあたりでアンサンブル学習しとけば、ある程度の正答率は出せます。
関連記事:【Python】 XGBboost・LightGBM・Catboostでアンサンブル学習をやってみる
関連記事:【Python】機械学習で株価を予測する~Scikit-Learnの決定木アルゴリズムを使う
参照:https://qiita.com/predora005/items/19aebcf3aa05946c7cf4

コメント
不知道说什么好,还是祝疫情早点结束吧!
[…] 関連記事:【Python】元最強アルゴリズム「XGBoost」で機械学習をやってみた […]
[…] 参照記事:【Python】元最強アルゴリズム「XGBoost」で機械学習をやってみた […]
[…] 参照記事:【Python】元最強アルゴリズム「XGBoost」で機械学習をやってみた […]
[…] 【Python】元最強アルゴリズム「XGBoost」で機械学習をやってみたこんにちはミナピピン(@python_mllover)です!今日はかつてKaggleの機械学習系アルゴリズムで、最強の座にもっとも近かった「X […]
[…] ・【Python】元最強アルゴリズム「XGBoost」で機械学習をやってみた […]
[…] 関連記事:【Python】元最強アルゴリズム「XGBoost」で機械学習をやってみた […]