この記事では実際にPythonのデータ分析アプリケーション作成のフレームワークとして有名なStreamlitでログイン認証+CSVダウンロード機能付きの機械学習アプリを作成した例を紹介しています
Streamlitの概要や用途については下記の記事で作成しています
【Python】Streamlitで簡単に機械学習結果を可視化するアプリを作成する
アプリの概要
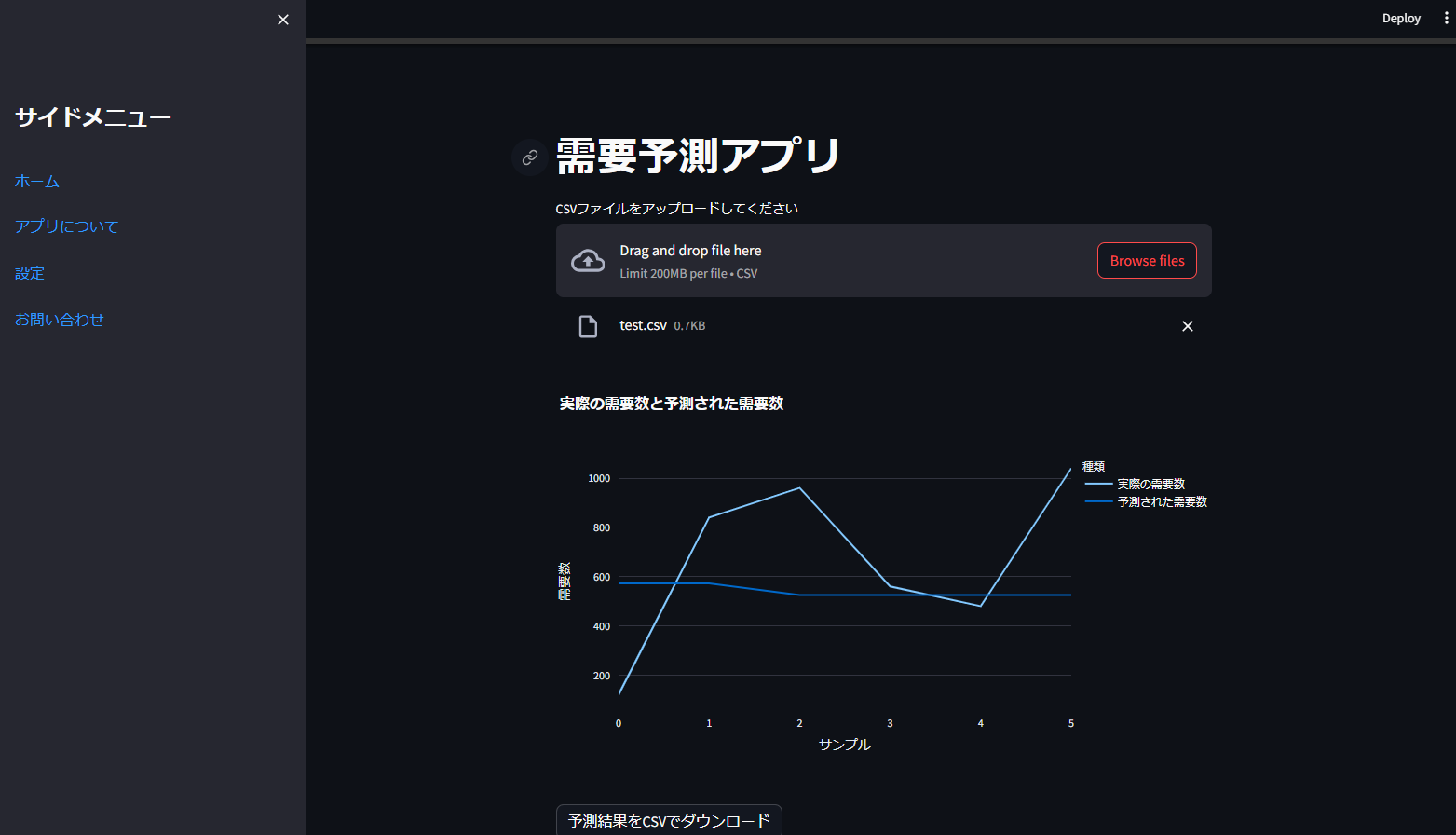
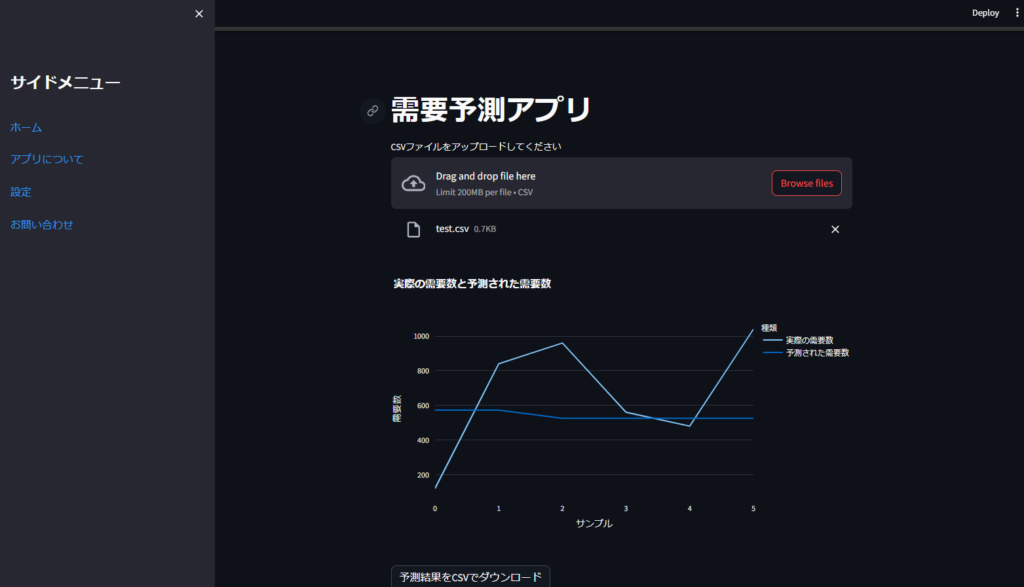
このStreamlitアプリケーションは、需要予測を行い、その結果を視覚化し、最終的に予測結果をCSVファイルとしてダウンロード可能にする機能を提供します。アプリは認証機能を備えており、指定されたユーザー名とパスワードを持つユーザーのみがアプリの機能にアクセスできます。さらに、アプリはカスタムヘッダーとサイドメニューを持ち、より使いやすいインターフェースを提供します。
アプリの構成要素
1. 認証システム
アプリの冒頭で、ユーザー名とパスワードを用いた基本的な認証システムが設定されています。ユーザーが正しい認証情報を入力すると、アプリの主要な機能にアクセスできるようになります。認証情報が間違っている場合はエラーメッセージが表示されます。
2. カスタムヘッダーとサイドメニュー
カスタムCSSとHTMLを使用して、アプリに固定されたヘッダーとサイドメニューが追加されています。ヘッダーにはアプリ名とアイコンが表示され、サイドメニューには複数のリンクが含まれています。これにより、ユーザーはアプリをより直感的にナビゲートできます。
3. 需要予測機能
ユーザーはCSVファイルをアップロードすることで、需要予測を行うことができます。アプリはアップロードされたデータを読み込み、指定された特徴量を用いてランダムフォレスト回帰モデルで予測を行います。データの前処理にはOneHotEncoderを使用し、カテゴリカル変数を処理しています。
4. 結果の視覚化とダウンロード
予測結果はPlotlyを用いて視覚化され、実際の需要数と予測された需要数が折れ線グラフで表示されます。また、予測結果を含むデータフレームはCSVファイルとしてダウンロード可能です。
アプリの用途
このアプリケーションは、需要予測の結果を迅速に視覚化し、分析結果を共有する必要があるビジネスアナリストやデータサイエンティストにとって非常に有用です。認証機能により、機密データを保護しつつ、チーム内の限られたメンバーと情報を共有できます。
セキュリティへの注意: 実際のアプリケーションでは、より強固な認証システムとデータの保護方法を検討する必要があります。
上記の技術に関する関連記事
コードとサンプルデータをまとめたレポジトリはこちらになります
→https://github.com/beginerSE/steamlit_sample_app/tree/main
予測用のデータ
商品名ジャンルサイズ需要数で構成されたデータになります。
値は適当です
‹test.csv›
| 商品名 | ジャンル | サイズ | 需要数 |
| 商品A | 食品 | M | 40 |
| 商品B | 衣類 | L | 80 |
| 商品A | 食品 | M | 50 |
| 商品B | 衣類 | L | 100 |
| 商品A | 食品 | M | 20 |
| 商品B | 衣類 | L | 240 |
| 商品A | 食品 | M | 28 |
| 商品B | 衣類 | L | 220 |
| 商品A | 食品 | M | 60 |
| 商品B | 衣類 | L | 300 |
| 商品A | 食品 | M | 140 |
| 商品B | 衣類 | L | 380 |
コード
# ライブラリを読み込む
import streamlit as st
import pandas as pd
import plotly.express as px
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from io import BytesIO# ユーザー名とパスワードの設定
USER_NAME = “admin”
PASSWORD = “password”
# セッション状態の初期化
if ‘login’ not in st.session_state:
st.session_state[‘login’] = False
# 認証フォーム
if not st.session_state[‘login’]:
user_name = st.sidebar.text_input(“ユーザー名”)
password = st.sidebar.text_input(“パスワード”, type=”password”)if st.sidebar.button(‘ログイン’):
if user_name == USER_NAME and password == PASSWORD:
st.session_state[‘login’] = True
st.success(“ログイン成功!”)
else:
st.error(“ユーザー名またはパスワードが間違っています。”)
if st.session_state[‘login’]:
# Font AwesomeのCSSを含める
st.markdown(“””
<link rel=”stylesheet” href=”https://use.fontawesome.com/releases/v5.8.1/css/all.css” integrity=”sha384-50oBUHEmvpQ+1lW4y57PTFmhCaXp0ML5d60M1M7uH2+nqUivzIebhndOJK28anvf” crossorigin=”anonymous”>
<style>
/* 固定ヘッダーのスタイル */
.custom-header {
position: fixed;
top: 0;
left: 0;
width: 100%;
background-color: #333;
color: #fff;
z-index: 9999;
padding: 10px 0;
font-size: 20px;
box-shadow: 0 2px 4px rgba(0,0,0,.5);
}
.custom-header .header-content {
margin: 0 auto;
width: 95%;
display: flex;
align-items: center;
}
.custom-header i {
margin-right: 10px;
}
/* Streamlitのコンテンツを下にずらす */
body > div:first-child {
padding-top: 60px;
}
</style>
“””, unsafe_allow_html=True)
# カスタムヘッダーのHTML
st.markdown(“””
<div class=”custom-header”>
<div class=”header-content”>
<i class=”fas fa-chart-line”></i><span>アプリ名</span>
</div>
</div>
“””, unsafe_allow_html=True)
# サイドバーにタイトルを追加
st.sidebar.title(‘サイドメニュー’)
# カスタムCSSを適用
st.sidebar.markdown(“””
<style>
/* サイドバーのスタイリング */
.css-1d391kg {
padding: 1rem 1rem; /* 余白の調整 */
background-color: #f0f2f6; /* 背景色 */
}
/* リンクのスタイリング */
a {
display: block;
margin: 0.5rem 0;
color: #333; /* リンクの色 */
text-decoration: none; /* 下線を消す */
}
a:hover {
color: #007bff; /* ホバー時の色 */
}
</style>
“””, unsafe_allow_html=True)
# サイドメニュー項目の追加
st.sidebar.markdown(‘<a href=”#” class=”sidebar-link”>ホーム</a>’, unsafe_allow_html=True)
st.sidebar.markdown(‘<a href=”#” class=”sidebar-link”>アプリについて</a>’, unsafe_allow_html=True)
st.sidebar.markdown(‘<a href=”#” class=”sidebar-link”>設定</a>’, unsafe_allow_html=True)
st.sidebar.markdown(‘<a href=”#” class=”sidebar-link”>お問い合わせ</a>’, unsafe_allow_html=True)
# タイトル
st.title(‘需要予測アプリ’)
# CSVファイルのアップロード
uploaded_file = st.file_uploader(“CSVファイルをアップロードしてください”, type=[‘csv’])
if uploaded_file is not None:
# データの読み込み
data = pd.read_csv(uploaded_file)# 簡単なデータ処理
X = data.drop(‘需要数’, axis=1) # 特徴量
y = data[‘需要数’] # 目的変数# カテゴリ変数の処理
categorical_features = [‘商品名’, ‘ジャンル’, ‘サイズ’]
categorical_transformer = OneHotEncoder(handle_unknown=’ignore’)preprocessor = ColumnTransformer(
transformers=[
(‘cat’, categorical_transformer, categorical_features)
])# モデルの定義
model = Pipeline(steps=[(‘preprocessor’, preprocessor),
(‘regressor’, RandomForestRegressor())])# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# モデルのトレーニング
model.fit(X_train, y_train)# 予測の実行
y_pred = model.predict(X_test)# 予測結果のDataFrameの作成
# results_df = pd.DataFrame({‘実際の需要数’: y_test, ‘予測された需要数’: y_pred})
# グラフの表示
# st.write(“### 予測結果のグラフ”)
# fig, ax = plt.subplots()
# ax.plot(results_df.index, results_df[‘実際の需要数’], label=’実際の需要数’, marker=’o’)
# ax.plot(results_df.index, results_df[‘予測された需要数’], label=’予測された需要数’, marker=’x’)
# plt.xlabel(‘サンプル’)
# plt.ylabel(‘需要数’)
# plt.title(‘実際の需要数と予測された需要数’)
# plt.legend()
# st.pyplot(fig)
# 予測結果のDataFrameの作成
results_df = pd.DataFrame({‘サンプル’: range(len(y_test)), ‘実際の需要数’: y_test, ‘予測された需要数’: y_pred})# Plotlyでグラフを作成
fig = px.line(results_df, x=’サンプル’, y=[‘実際の需要数’, ‘予測された需要数’], labels={‘value’: ‘需要数’, ‘variable’: ‘種類’}, title=’実際の需要数と予測された需要数’)
st.plotly_chart(fig, use_container_width=True)# CSVダウンロード機能
def convert_df_to_csv(df):
return df.to_csv(index=False).encode(‘utf-8′)csv = convert_df_to_csv(results_df)
st.download_button(
label=”予測結果をCSVでダウンロード”,
data=csv,
file_name=’predicted_demands.csv’,
mime=’text/csv’,
)
‹実行結果›


終わり
Streamlitを使用することで、プログラミング初学者でも短期間でプロフェッショナルなデータアプリケーションを開発することが可能になります。データの力を最大限に活用し、インパクトのある洞察を提供できるアプリケーションを作成してみてください。


コメント
[…] ・Streamlitでログイン認証+CSVダウンロード機能付きの機械学習アプリを作成する […]